实例分析
即使学过机器学习的人,对机器学习中的 MLE(极大似然估计)、MAP(最大后验估计)以及贝叶斯估计(Bayesian) 仍有可能一知半解。对于一个基础模型,通常都可以从这三个角度去建模,比如对于逻辑回归(Logistics Regression)来说:
MLE: Logistics Regression
MAP: Regularized Logistics Regression
Bayesian: Bayesian Logistic Regression
本文结合实际例子,以通俗易懂的方式去讲解这三者之间的本质区别,希望帮助读者扫清理解中的障碍。
先导知识点: 假设空间(Hypothesis Space)
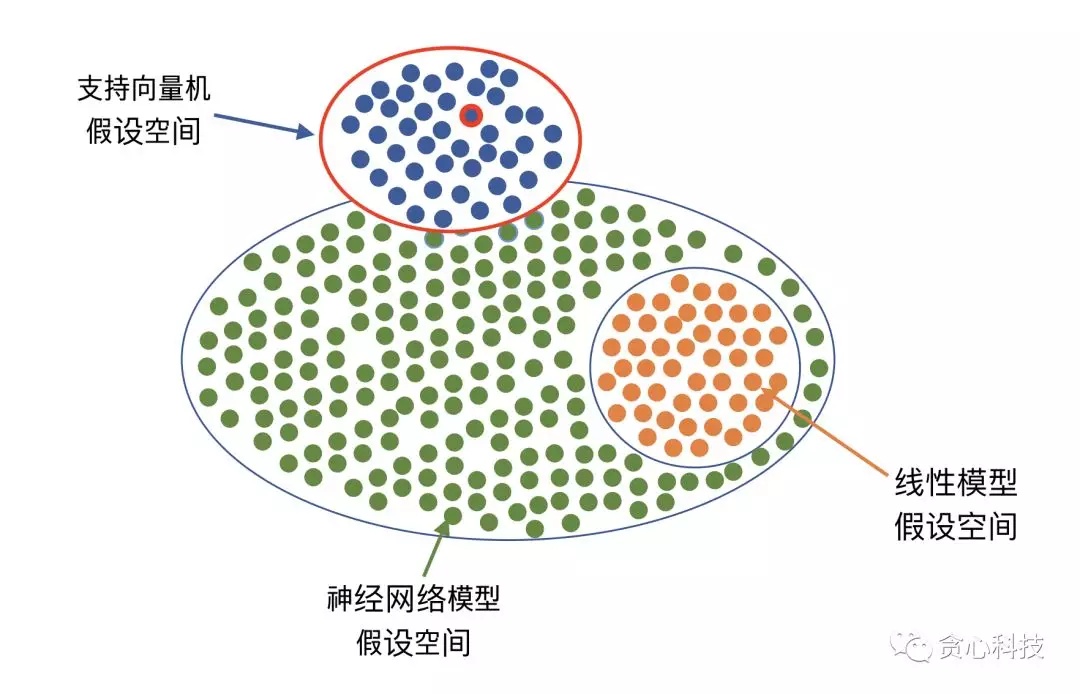
什么叫假设空间呢?我们可以这样理解。机器学习包含很多种算法,比如线性回归、支持向量机、神经网络、决策树、GDBT等等。我们在建模的时候,第一步就是要选择一个特定的算法比如“支持向量机”。一旦选择了一个算法,就相当于我们选择了一个假设空间。 在一个假设空间里,我们通常会有无数种不同的解(或者可以理解成模型),一个优化算法(比如梯度下降法)做的事情就是从中选择最好的一个解或者多个解/模型,当然优化过程要依赖于样本数据。举个例子,如果我们选择用支持向量机,那相当于我们可选的解/模型集中在上半部分(蓝色点)。
一个具体“toy”问题
“ 张三遇到了一个数学难题,想寻求别人帮助。通过一番思考之后发现自己的朋友在清华计算机系当老师。于是,他决定找清华计算机系学生帮忙。那张三用什么样的策略去寻求帮助呢?
在这里,“清华计算机系”是一个假设空间。在这个假设空间里,每一位学生可以看做是一个模型(的实例化)。

对于张三来说,他有三种不同的策略可以选择。
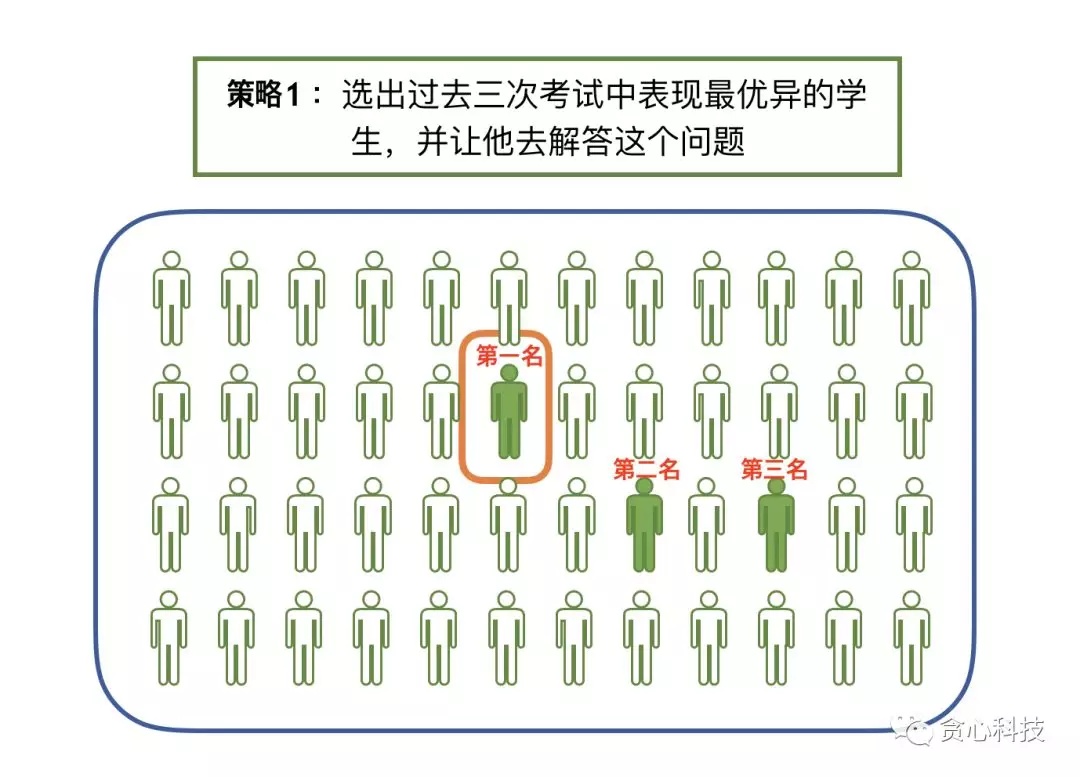
第一种策略 : MLE
第一种策略就是从系里选出过往成绩最好的学生,并让他去解答这个难题。比如我们可以选择过去三次考试中成绩最优秀的学生。
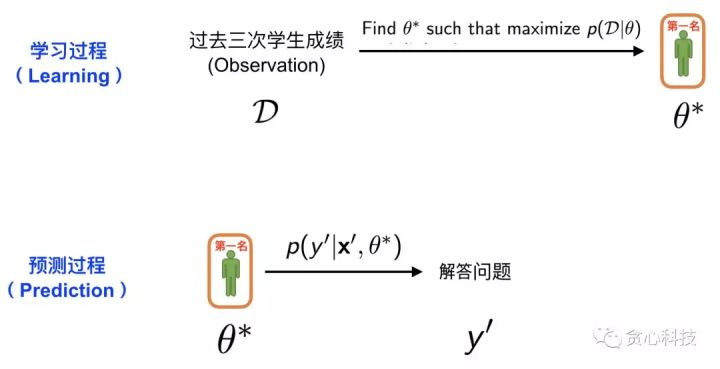
一般的学习流程分为“学习过程”和“预测过程”。第一种策略的方案可以用下面的图来表示。 在这里,学习过程相当于从所有系的学生中挑选出成绩最好的学生。所以,这里的“学生过往成绩单”就是我们已知的训练数据 D, 选出成绩最好的学生(计算历史平均分数,并选出最高的),这个过程就是MLE。一旦我们找到了成绩最好的学生,就可以进入预测环节。在预测环节中,我们就可以让他回答张三手里的难题 x’, 之后就可以得到他给出的解答 y’。
第二种策略:MAP
跟第一种策略的不同点在于,第二种策略中我们听取了老师的建议,老师就是张三的朋友。这位老师给出了自己的观点:_“小明和小花的成绩中可能存在一些水分”。_当我们按照成绩的高低给学生排序,假设前两名依次为小明和小花,如果我们不考虑这位老师的评价,则我们肯定把小明作为目标对象。然而,既然老师已经对小明和小花做了一些负面的评价,那这个时候,我们很有可能最后选择的是班级里的第三名,而不是小明或者小花。
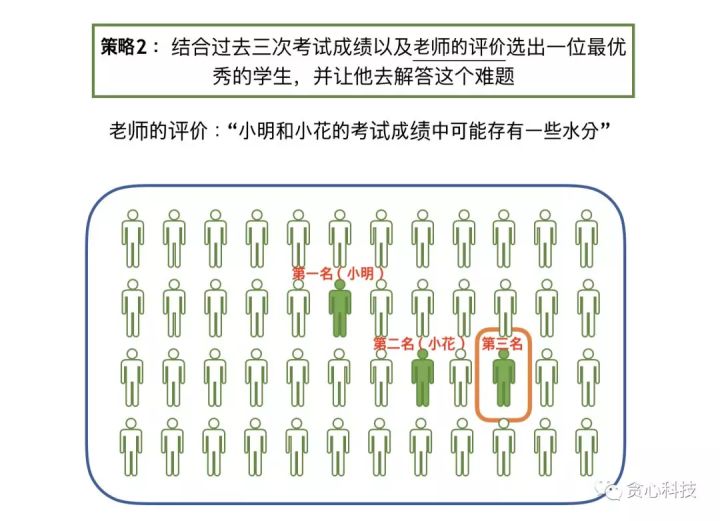
我们把第二种策略的过程也用一个图来描述。与上面的图相比,唯一的区别在于这里多出了老师的评价,我们称之为 Prior。 也就是说我们根据学生以往的成绩并结合老师评价,选择了一位我们认为最优秀的学生(可以看成是模型)。之后就可以让他去回答张老师的难题 x’,并得到他的解答 y’。整个过程类似于MAP的估计以及预测。
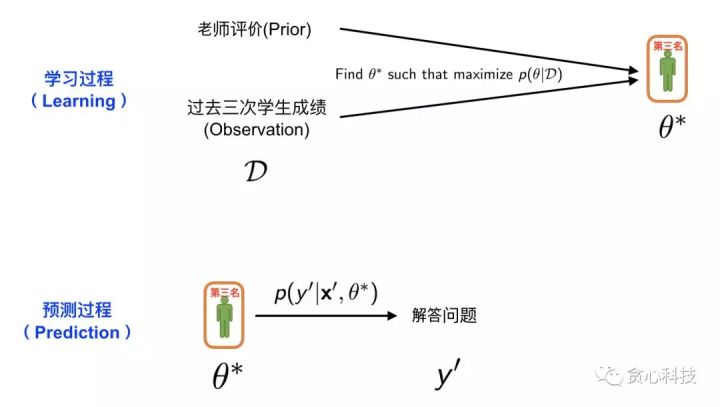
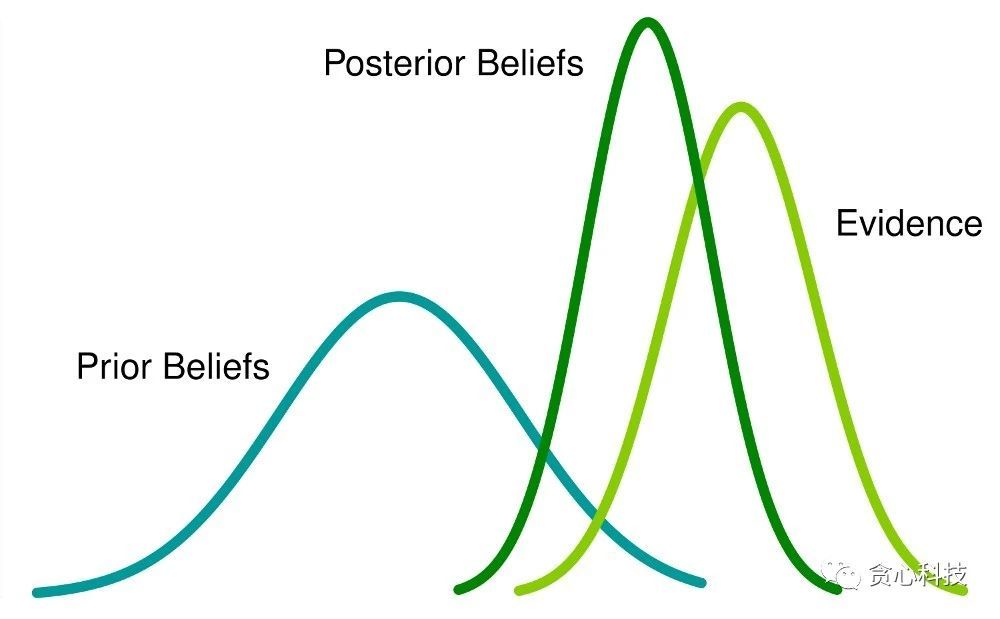
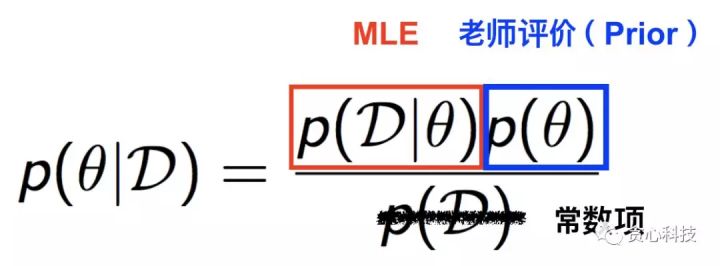
到这里,有些读者可能会有一些疑惑:“_老师的评价(Prior)跟学生过往的成绩(Observation)是怎么结合在一起的?”_。 为了回答这个问题,我们不得不引出一个非常著名的定理,叫做 贝叶斯定理, 如下图所示。左边的项是MAP需要优化的部分,通过贝叶斯定理这个项可以分解成 MLE(第一种策略)和 Prior,也就是老师的评价。在这里,分母是常数项(Constant),所以不用考虑。
第三种策略 - Bayesian
最后,我们来介绍第三种策略。这种策略应该很多人也可以想象得到,其实就是让所有人都去参与回答张三的难题,但最后我们通过一些加权平均的方式获得最终的答案。 比如有三个学生,而且我们对这三个学生情况没有任何了解。通过提问,第一个学生回答的答案是A,第二个学生回答的答案也是A,但第三个学生回答的是B。在这种情况下,我们基本可以把A作为标准答案。接着再考虑一个稍微复杂的情况,假设我们通过以往他们的表现得知第三个学生曾经多次获得过全国奥赛的金牌,那这个时候该怎么办? 很显然,在这种情况下,我们给予第三个学生的话语权肯定要高于其他两位学生。
我们把上面的这种思路应用到张三的问题上,其实相当于我们让所有计算机系的学生参与回答这个问题,之后把他们的答案进行汇总并得出最终的答案。如果我们知道每一位学生的话语权(权重),这个汇总的过程是确定性(deterministic)。 但每一位学生的话语权(权重)怎么得到呢? 这就是贝叶斯估计做的事情!
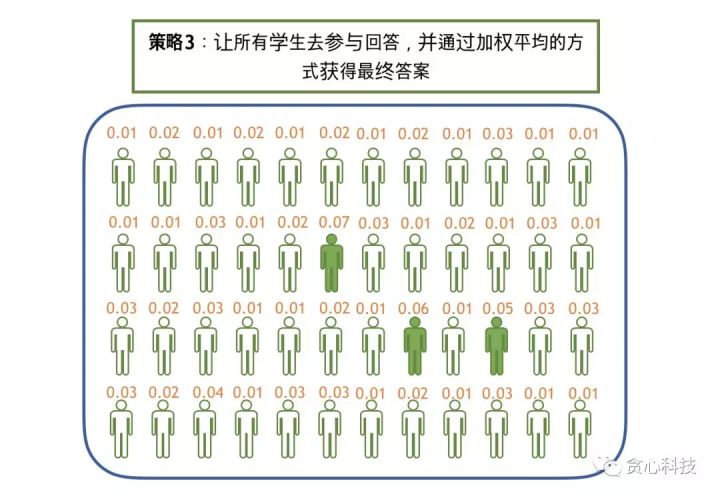
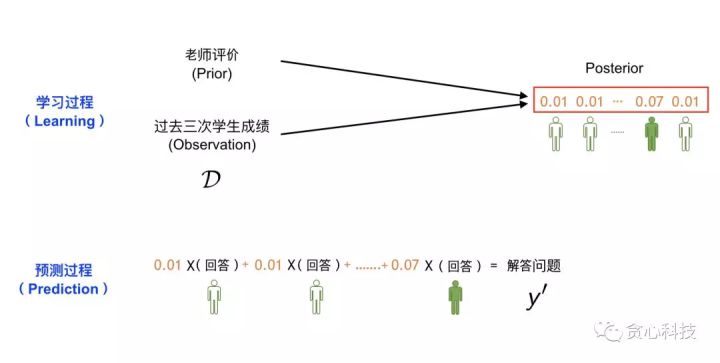
我们用下面的一幅图来讲述贝叶斯估计和预测的整个过程。跟MAP类似,我们已知每一位学生过去三次考试考试成绩(D)以及老师的评价(Prior)。 但跟MAP不同的是, 我们这里的目标不再是- “选出最优秀的学生”,而是通过观测数据(D)去获得每一位学生的发言权(权重), 而且这些权重全部加起来要等于1, 相当于是一个valid分布(distribution)。
总结起来,在第三种策略之下,给定过去考试成绩(D)和老师的评价(Prior), 我们的目标是估计学生权重的分布,也称之为Posterior Distribution。 那这个分布具体怎么去估计呢? 这部分就是贝叶斯估计做的事情,有很多种方法可以做这件事情,比如MCMC, Variational Method等等,但这并不是本文章的重点,所以不在这里进一步解释,有兴趣的读者可以关注之后关于贝叶斯的专栏文章。从直观的角度思考,因为我们知道每一位学生过往的成绩,所以我们很容易了解到他们的能力水平进而估计出每一位学生的话语权(权重)。
一旦我们获得了这个分布(也就是每一位学生的权重),接下来就可以通过类似于加权平均的方式做预测了,那些权重高的学生话语权自然就越大。
以上是对MLE, MAP以及贝叶斯估计的基本讲解。下面我们试图去回答两个常见的问题。
Q: 随着我们观测到越来越多的数据,MAP估计逐步逼近MLE,这句话怎么理解?
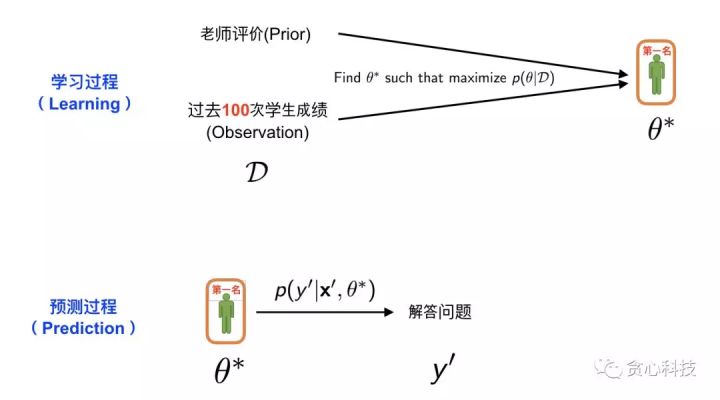
我们接着使用之前MAP(第二种策略)的例子。在这里,我们对原来的问题稍作改变。在之前的例子里我们假设能够得到每一位学生过去三次考试中的成绩。但在这里,我们进一步假定可以获得每一位学生过去100次考试中的成绩。
那这样的修改会带来什么样的变化呢? 如果仔细想一想,其实也很容易想得到。我们设想一下这样的两种场景。假设我们知道某一位学生过去三次的考试成绩比较优异,但老师却告诉我们这位学生能力其实不怎么样,那这时候我们很可能就去相信老师了,毕竟仅仅通过三次考试的成绩很难对一个学生有全面的了解。但相反,假设我们了解到这位学生在过去100次考试中全部获得了班里第一名,但同时老师又告诉我们这位学生的能力其实不怎么样,那这时候我们会有什么样的反应? 两三次考试或许可以算做是运气,但连续100次都是第一名这件事情很难再跟运气画等号吧? 我们甚至可能会去怀疑老师的品德,是不是故意污蔑人家?
这就是说,当我们观测到的数据越来越多的时候,我们从数据中获取的信息的置信度是越高的,相反老师提供的反馈(Prior)的重要性就会逐渐降低。理想情况下,当我们拥有无穷多的数据样本时,MAP会逼近MLE估计,道理都是一样的。
Q: 为什么贝叶斯估计会比MLE, MAP难?
回顾一下,MLE 和MAP都是在寻找一个最优秀的学生。贝叶斯估计则是在估计每一位学生的权重。第一种情况下,为了寻找最优秀的学生,我们只需知道学生之间的“相对”优秀程度。这个怎么理解呢? 比如一个班里有三个学生A,B,C,我们知道学生A比B优秀,同时知道B比C优秀,那这时候就可以推断出学生A是最优秀的,我们并不需要明确知道A的成绩是多少,B的成绩是多少…..
但在贝叶斯估计模式下,我们必须要知道每一个学生的绝对权重,因为最后我们获得的答案是所有学生给出的答案的加权平均,而且所有学生的权重加起来要保证等于1(任何一个分布的积分和必须要等于1)。 假设我们知道每一位学生的能力值,a1, a2,…. an,这个能作为权重吗? 显然不能。为了获得权重,有一种最简单的方法就是先求和,然后再求权重。比如先计算 a1+…+an = S, 再用a1/S 作为权重。这貌似看起来也不难啊,只不过多做了一个加法操作?
我们很容易看出这个加法操作的时间复杂度是O(n),依赖于总体学生的数量。如果我们的假设空间只有几百名学生,这个是不成问题的。 但实际中,比如我们假设我们的模型用的是支持向量机,然后把假设空间里的每一个可行解比喻成学生,那这个假设空间里有多少个学生呢? 是无数个!!, 也就是说需要对无穷多个数做这种加法操作。 当然,这种加法操作会以积分(integeral)的方式存在,但问题是这种积分通常没有一个closed-form的解,你必须要去近似地估计才可以,这就是MCMC或者Variational方法做的事情,不在这里多做解释。
本文几点重要的Take-aways:
- 每一个模型定义了一个假设空间,一般假设空间都包含无穷的可行解;
- MLE不考虑先验(prior),MAP和贝叶斯估计则考虑先验(prior);
- MLE、MAP是选择相对最好的一个模型(point estimation), 贝叶斯方法则是通过观测数据来估计后验分布(posterior distribution),并通过后验分布做群体决策,所以后者的目标并不是在去选择某一个最好的模型;
- 当样本个数无穷多的时候,MAP理论上会逼近MLE;
- 贝叶斯估计复杂度大,通常用MCMC等近似算法来近似;
最后贴一张总结的图:

理论分析
一、机器学习
核心思想是从past experience中学习出规则,从而对新的事物进行预测。对于监督学习来说,有用的样本数目越多,训练越准确。
用下图来表示机器学习的过程及包含的知识:

简单来说就是:
- 首先要定义我们的假设空间(Model assumption):如线性分类,线性回归,逻辑回归,SVM,深度学习网络等。
- 如何衡量我们学出来的模型的好坏?定义损失函数(目标函数),lost function,如square loss
- 如何对假设的模型做优化,及optimization过程。简单说,就是选择一种算法(如:梯度下降,牛顿法等),对目标函数进行优化,最终得到最优解;
- 不同的模型使用不同的算法,如逻辑回归通常用梯度下降法解决,神经网络用反向传播算法解决,贝叶斯模型则用MCMC来解决。
- 机器学习 = 模型 + 优化(不同算法)
- 还有一个问题,模型的复杂度怎么衡量?因为复杂的模型容易出现过拟合(overfitting)。解决过拟合的方就是加入正则项(regularization)
- 以上问题都解决之后,我们怎么判断这个解就是真的好的呢?用 交叉验证(cross-validation) 来验证一下。
二、ML vs MAP vs Bayesian

- ML(最大似然估计):就是给定一个模型的参数,然后试着最大化p(D|参数)。即给定参数的情况下,看到样本集的概率。目标是找到使前面概率最大的参数。
- 逻辑回归都是基于ML做的;
- 缺点:不会把我们的先验知识加入模型中。
- MAP(最大后验估计):最大化p(参数|D)。
- Bayesian:我们的预测是考虑了所有可能的参数,即所有的参数空间(参数的分布)。
- ML和MAP都属于同一个范畴,称为(freqentist),最后的目标都是一样的:找到一个最优解,然后用最优解做预测。
三、ML

我们需要去最大化p(D|参数),这部分优化我们通常可以用把导数设置为0的方式去得到。然而,ML估计不会把先验知识考虑进去,而且很容易造成过拟合现象。
举个例子,比如对癌症的估计,一个医生一天可能接到了100名患者,但最终被诊断出癌症的患者为5个人,在ML估计的模式下我们得到的得到癌症的概率为0.05。
这显然是不太切合实际的,因为我们根据已有的经验,我们知道这种概率会低很多。然而ML估计并没有把这种知识融入到模型里。
四、MAP


通过上面的推导我们可以发现,MAP与ML最大的不同在于p(参数)项,所以可以说MAP是正好可以解决ML缺乏先验知识的缺点,将先验知识加入后,优化损失函数。
其实p(参数)项正好起到了正则化的作用。如:如果假设p(参数)服从高斯分布,则相当于加了一个L2 norm;如果假设p(参数)服从拉普拉斯分布,则相当于加了一个L1 norm。
五、Bayesian

再次强调一下: ML和MAP只会给出一个最优的解, 然而贝叶斯模型会给出对参数的一个分布,比如对模型的参数, 假定参数空间里有参数1,参数2, 参数3,…参数N,贝叶斯模型学出来的就是这些参数的重要性(也就是分布),然后当我们对新的样本预测的时候,就会让所有的模型一起去预测,但每个模型会有自己的权重(权重就是学出来的分布)。最终的决策由所有的估计根据其权重做出决策。
模型的ensemble的却大的优点为它可以reduce variance, 这根投资很类似,比如我们投资多种不同类型的股票,总比投资某一个股票时的风险会低。
六、上面提到了frequentist和bayesian,两者之间的区别是什么?

用一个简答的例子来再总结一下。 比如你是班里的班长,你有个问题想知道答案,你可以问所有的班里的学生。 一种方案是,问一个学习最好的同学。 另一种方案是,问所有的同学,然后把答案综合起来,但综合的时候,会按照每个同学的成绩好坏来做个权重。 第一种方案的思想类似于ML,MAP,第二种方案类似于贝叶斯模型。
七、Bayesian的难点

所以整个贝叶斯领域的核心技术就是要近似的计算 p($\theta$|D),我们称之为 bayesian inference ,说白了,这里的核心问题就是要近似这个复杂的积分(integral), 一种解决方案就是使用蒙特卡洛算法。比如我想计算一个公司所有员工的平均身高,这个时候最简答粗暴的方法就是让行政去一个一个去测量,然后计算平均值。但想计算所有中国人的平均身高,怎么做?(显然一个个测量是不可能的)
即采样。我们随机的选取一些人测量他们的身高,然后根据他们的身高来估计全国人民的审稿。当然采样的数目越多越准确,采样的数据越有代表性越准确。这就是蒙特卡洛算法的管家思想。
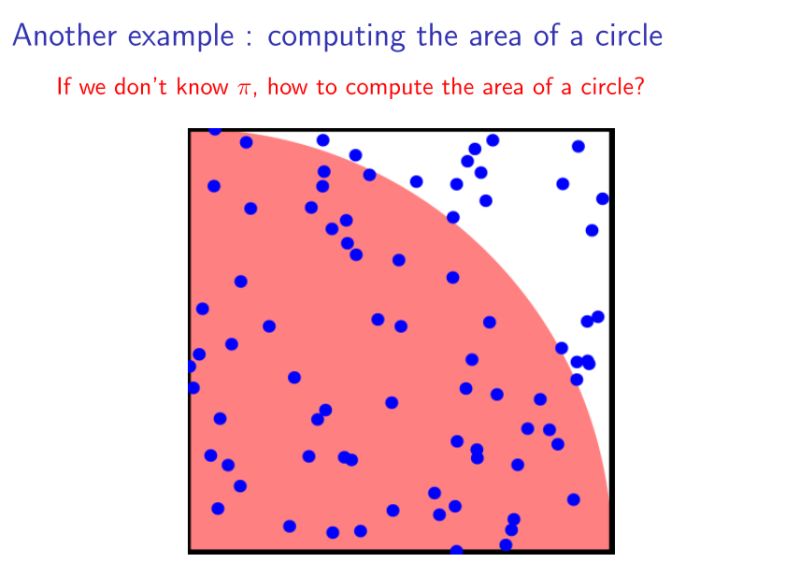
再例:
假设我们不知道π,但是想计算圆的面积。也可以通过采样的方法近似得到。随机再下图所示的正方形中撒入一些点,记落入红色区域的点的个数为n1,落入白色区域的个数为n2,则四分之一圆的面积就为n1/(n1+n2).——蒙特卡洛思想
那么,如何对连续函数估计呢?采样n多个数据,逼近最后的积分值。

假设我们要计算 f(x)的期望值, 我们也有p(x)这种分布,这个时候我们就可以不断的从p(x)这个分布里做一些采样,比如 x1,x2,…xn, 然后用这些采样的值去算f(x), 所以最后得到的结果就是 (f(x1) + f(x2),, + f(xn))/ n
然鹅,上面例子中提到的采样都是独立的。也就是每个样本跟其他的样本都是独立的,不影响彼此之间的采样。然而,在现实问题上,有些时候我们想加快有效样本的采样速度。这个问题讨论的就是怎么优化采样过程了,也是机器学习里一个比较大的话题了。
重申一下,用上面提到的采样方式我们可以去近似估计复杂的积分,也可以计算圆的面积,也可以计算全国人口的平均身高。但这个采样方式是独立的,有些时候,我们希望我们用更少的样本去更准确的近似某一个目标,所以就出现了sampling这种一个领域的研究,就是在研究以什么样的方式优化整个采样过程,使得过程更加高效。

MCMC这种采样方法,全称为markov chain monte carlo采样方法,就是每个采样的样本都是互相有关联性的。
但是MCMC算法需要在整个数据集上计算。也就是说为了得到一个样本,需要用所有的数据做迭代。这样当N很大时,显然不适用。而且限制了贝叶斯方法发展的主要原因就是计算复杂度太高。因此现在贝爷第领域人们最关心的问题是:怎么去优化采样,让它能够在大数据环境下学习出贝叶斯模型?
降低迭代复杂度的一个实例:
对于逻辑回归,使用梯度下降法更新参数时,有批量梯度下降法(即使用整个数据集去更新参数),为了降低计算复杂度,人们使用了随机梯度下降法,即随机从数据集中选取样本来更新参数。
所以,能否将此思想用于MCMC采样中呢?
Yes!langevin dynamic(MCMC算法中的一种),和stochastic optimizaiton(比如随机梯度下降法)可以结合在一起用。这样,我们就可以通过少量的样本去做采样,这个时候采样的效率就不在依赖于N了,而是依赖于m, m是远远小于N。
参考文献
[1] 贪心科技. 机器学习中的MLE、MAP和贝叶斯估计[DB/OL]. https://zhuanlan.zhihu.com/p/37543542, 2018-06-20.
[2] 江湖小妞. 贝叶斯思想以及与最大似然估计、最大后验估计的区别[DB/OL].
http://www.cnblogs.com/little-YTMM/p/5399532.html, 2018-06-20.

