弃权(Dropout)的过程
Dropout 的比例可以自己指定,以下仅为例子说明 Dropout率为0.5
弃权是一种相当激进的技术。和规范化不同,弃权技术并不依赖于代价函数的修改。而是,在弃权中,我们改变了网络本身。在介绍它为什么能工作,以及所得到的结果前,让我描述一下弃权(Dropout)基本的工作机制。
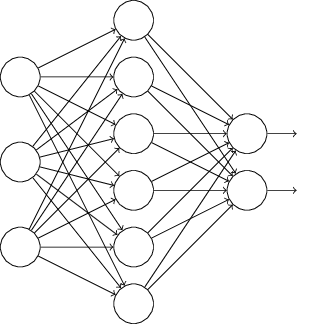
特别地,假设我们有一个训练数据 $x$ 和 对应的目标输出 $y$。通常我们会通过在网络中前向传播 $x$ ,然后进行反向传播来确定对梯度的贡献。使用弃权(Dropout)技术,这个过程就改了。我们会从随机(临时)地删除网络中的一半的隐藏神经元开始,同时让输入层和输出层的神经元保持不变。在此之后,我们会得到最终如下线条所示的网络。注意那些被弃权(Dropout)的神经元,即那些临时被删除的神经元,用虚圈表示在图中:
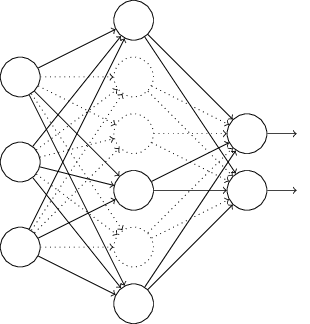
我们前向传播输入 $x$,通过修改后的网络,然后反向传播结果,同样通过这个修改后的网络。在一个小批量数据的若干样本上进行这些步骤后,我们对有关的权重和偏置进行更新。然后重复这个过程,首先重置弃权(Dropout)的神经元,然后选择一个新的随机的隐藏神经元的子集进行删除,估计对一个不同的小批量数据的梯度,然后更新权重和偏置。通过不断地重复,我们的网络会学到一个权重和偏置的集合。当然,这些权重和偏置也是在一半的隐藏神经元被弃权(Dropout)的情形下学到的。当我们实际运行整个网络时,是指两倍的隐藏神经元将会被激活。为了补偿这个,我们将从隐藏神经元出去的权重减半。
为什么弃权(Dropout)有效?
这个弃权(Dropout)过程可能看起来奇怪,像是临时安排的。为什么我们会指望这样的方法能够行正则化呢?为了解释所发生的事,我希望你停下来想一下标准没有弃权(Dropout))的训练方式。特别地,想象一下我们训练几个不同的神经网络,都使用同一个训练数据。当然,网络可能不是从同一初始状态开始的,最终的结果也会有一些差异。出现这种情况时,我们可以使用一些平均或者投票的方式来确定接受哪个输出。例如,如果我们训练了五个网络,其中三个把一个数字分类成 “3”,那很可能它就是“3”。另外两个可能就犯了错误。这种平均的方式通常是一种强大(尽管代价昂贵)的方式来减轻过拟合。原因在于不同的网络可能会以不同的方式过拟合,平均法可能会帮助我们消除那样的过拟合。
那么这和弃权(Dropout)有什么关系呢?启发式地看,当我们弃权(Dropout)掉不同的神经元集合时,有点像我们在训练不同的神经网络。所以,弃权(Dropout)过程就如同大量不同网络的效果的平均那样。不同的网络会以不同的方式过拟合了,所以,弃权(Dropout)过的网络的效果会减轻过拟合。
一个相关的启发式解释在早期使用这项技术的论文中曾经给出:“因为神经元不能依赖其他神经元特定的存在,这个技术其实减少了复杂的互适应的神经元。所以,强制要学习那些在神经元的不同随机子集中更加健壮的特征。” 换言之,如果我们将我们的神经网络看做一个进行预测的模型的话,我们就可以将弃权(Dropout)看做是一种确保模型对于一部分证据丢失健壮的方式。这样看来,弃权(Dropout)和 L1、L2 regularization也是有相似之处的,这也倾向于更小的权重,最后让网络对丢失个体连接的场景更加健壮。
对于弃权的理解
参考文献
[1] Michael Nielsen.CHAPTER 2 Improving the way neural networks learn[DB/OL]. http://neuralnetworksanddeeplearning.com/chap3.html. 2018-06-26.
[2] Zhu Xiaohu. Zhang Freeman.Another Chinese Translation of Neural Networks and Deep Learning[DB/OL]. https://github.com/zhanggyb/nndl/blob/master/chap3.tex, 2018-06-26.
[3] 鹿往森处走. 神经网络之dropout层[DB/OL]. https://www.cnblogs.com/zyber/p/6824980.html, 2018-06-26.

