We introduce Recurrent Neural Networks and how they are able to feed in a sequence and predict either a fixed target (categorical/numerical) or another sequence (sequence to sequence).
Here, we implement a Siamese RNN to predict the similarity of addresses and use it for record matching. Using RNNs for record matching is very versatile, as we do not have a fixed set of target categories and can use the trained model to predict similarities across new addresses.
This script implements an RNN in TensorFlow to predict spam/ham from texts.
We start by loading the necessary libraries and initializing a computation graph in TensorFlow.
1 2 3 4 5 6 7 8 9 10 11 12
import os import re import io import requests import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from zipfile import ZipFile from tensorflow.python.framework import ops ops.reset_default_graph() # Start a graph sess = tf.Session()
We download and save the data next. First we check if we have saved it before and load it locally, if not, we load it from the internet (UCI machine learning data repository).
# Download or open data data_dir = 'temp' data_file = 'text_data.txt' ifnot os.path.exists(data_dir): os.makedirs(data_dir)
ifnot os.path.isfile(os.path.join(data_dir, data_file)): zip_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip' r = requests.get(zip_url) z = ZipFile(io.BytesIO(r.content)) file = z.read('SMSSpamCollection') # Format Data text_data = file.decode() text_data = text_data.encode('ascii', errors='ignore') text_data = text_data.decode().split('\n')
# Save data to text file with open(os.path.join(data_dir, data_file), 'w') as file_conn: for text in text_data: file_conn.write("{}\n".format(text)) else: # Open data from text file text_data = [] with open(os.path.join(data_dir, data_file), 'r') as file_conn: for row in file_conn: text_data.append(row) text_data = text_data[:-1]
text_data = [x.split('\t') for x in text_data if len(x) >= 1] [text_data_target, text_data_train] = [list(x) for x in zip(*text_data)]
Next, we process the texts and turn them into numeric representations (words —> indices).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# Create a text cleaning function defclean_text(text_string): text_string = re.sub(r'([^\s\w]|_|[0-9])+', '', text_string) text_string = " ".join(text_string.split()) text_string = text_string.lower() return text_string
# Clean texts text_data_train = [clean_text(x) for x in text_data_train]
Vocabulary Size: 933
80-20 Train Test split: 4459 -- 1115
Here we can define our RNN model. We create the placeholders for the data, word embedding matrices (and embedding lookups), and define the rest of the model.
The rest of the RNN model will create a dynamic RNN cell (regular RNN type), which will vary the number of RNNs needed for variable input length (different amount of words for input texts), and then output into a fully connected logistic layer to predict spam or ham as output.
# Define the RNN cell # tensorflow change >= 1.0, rnn is put into tensorflow.contrib directory. Prior version not test. if tf.__version__[0] >= '1': cell = tf.contrib.rnn.BasicRNNCell(num_units=rnn_size) else: cell = tf.nn.rnn_cell.BasicRNNCell(num_units=rnn_size)
output, state = tf.nn.dynamic_rnn(cell, embedding_output, dtype=tf.float32) output = tf.nn.dropout(output, dropout_keep_prob)
# Get output of RNN sequence #output = tf.transpose(output, [1, 0, 2]) #last = tf.gather(output, int(output.get_shape()[0]) - 1)
You may ignore the warning, as the texts are small and our batch size is only 100. If you increase the batch size and/or have longer sequences of texts, this model may consume too much memory.
Next we initialize the variables in the computational graph.
# Run loss and accuracy for training temp_train_loss, temp_train_acc = sess.run([loss, accuracy], feed_dict=train_dict) train_loss.append(temp_train_loss) train_accuracy.append(temp_train_acc)
# Run Eval Step test_dict = {x_data: x_test, y_output: y_test, dropout_keep_prob:1.0} temp_test_loss, temp_test_acc = sess.run([loss, accuracy], feed_dict=test_dict) test_loss.append(temp_test_loss) test_accuracy.append(temp_test_acc) print('Epoch: {}, Test Loss: {:.2}, Test Acc: {:.2}'.format(epoch+1, temp_test_loss, temp_test_acc))
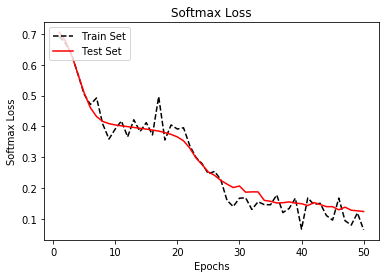
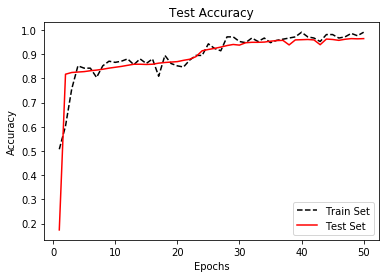
Epoch: 1, Test Loss: 0.71, Test Acc: 0.17
Epoch: 2, Test Loss: 0.68, Test Acc: 0.82
...
Epoch: 50, Test Loss: 0.12, Test Acc: 0.96
Here is matplotlib code to plot the loss and accuracy over the training generations for both the train and test sets.
Here, we show how to use our trained model to evaluate new texts (which may or may not be spam/ham)
1 2 3 4 5
sample_texts = ['Hi, please respond 1111 asap to claim your change to win now!', 'Hey what are you doing for dinner tonight?', 'New offer, show this text for 50% off of our inagural sale!', 'Can you take the dog to the vet tomorrow?', 'Congratulations! You have been randomly selected to receive account credit!']
Now we clean our sample texts.
1 2
clean_texts = [clean_text(text) for text in sample_texts] print(clean_texts)
['hi please respond asap to claim your change to win now', 'hey what are you doing for dinner tonight', 'new offer show this text for off of our inagural sale', 'can you take the dog to the vet tomorrow', 'congratulations you have been randomly selected to receive account credit']
Next, we transform each text as a sequence of words into a sequence of vocabulary indices.
Now we can run each of the texts through our model and get the output logits.
1 2 3 4 5
# Remember to wrap the resulting logits in a softmax to get probabilities eval_feed_dict = {x_data: processed_texts, dropout_keep_prob: 1.0} model_results = sess.run(tf.nn.softmax(logits_out), feed_dict=eval_feed_dict)
Text: Hi, please respond 1111 asap to claim your change to win now!,
Prediction: spam
Text: Hey what are you doing for dinner tonight?,
Prediction: ham
Text: New offer, show this text for 50% off of our inagural sale!,
Prediction: ham
Text: Can you take the dog to the vet tomorrow?,
Prediction: ham
Text: Congratulations! You have been randomly selected to receive account credit!,
Prediction: spam
Here we implement an LSTM model on all a data set of Shakespeare works.
We start by loading the necessary libraries and resetting the default computational graph.
1 2 3 4 5 6 7 8 9 10 11 12
import os import re import string import requests import numpy as np import collections import random import pickle import matplotlib.pyplot as plt import tensorflow as tf from tensorflow.python.framework import ops ops.reset_default_graph()
We start a computational graph session.
1
sess = tf.Session()
Next, it is important to set the algorithm and data processing parameters.
Parameter : Descriptions
min_word_freq: Only attempt to model words that appear at least 5 times.
rnn_size: size of our RNN (equal to the embedding size)
epochs: Number of epochs to cycle through the data
batch_size: How many examples to train on at once
learning_rate: The learning rate or the convergence paramter
training_seq_len: The length of the surrounding word group (e.g. 10 = 5 on each side)
# Set RNN Parameters min_word_freq = 5# Trim the less frequent words off rnn_size = 128# RNN Model size embedding_size = 100# Word embedding size epochs = 10# Number of epochs to cycle through data batch_size = 100# Train on this many examples at once learning_rate = 0.001# Learning rate training_seq_len = 50# how long of a word group to consider #embedding_size = rnn_size save_every = 500# How often to save model checkpoints eval_every = 50# How often to evaluate the test sentences prime_texts = ['thou art more', 'to be or not to', 'wherefore art thou']
# Declare punctuation to remove, everything except hyphens and apostrophes punctuation = string.punctuation punctuation = ''.join([x for x in punctuation if x notin ['-', "'"]])
# Make Model Directory ifnot os.path.exists(full_model_dir): os.makedirs(full_model_dir)
# Make data directory ifnot os.path.exists(data_dir): os.makedirs(data_dir)
Download the data if we don’t have it saved already. The data comes from the Gutenberg Project
print('Loading Shakespeare Data') # Check if file is downloaded. ifnot os.path.isfile(os.path.join(data_dir, data_file)): print('Not found, downloading Shakespeare texts from www.gutenberg.org') shakespeare_url = 'http://www.gutenberg.org/cache/epub/100/pg100.txt' # Get Shakespeare text response = requests.get(shakespeare_url) shakespeare_file = response.content # Decode binary into string s_text = shakespeare_file.decode('utf-8') # Drop first few descriptive paragraphs. s_text = s_text[7675:] # Remove newlines s_text = s_text.replace('\r\n', '') s_text = s_text.replace('\n', '')
# Write to file with open(os.path.join(data_dir, data_file), 'w') as out_conn: out_conn.write(s_text) else: # If file has been saved, load from that file with open(os.path.join(data_dir, data_file), 'r') as file_conn: s_text = file_conn.read().replace('\n', '')
Loading Shakespeare Data
Cleaning Text
Done loading/cleaning.
Define a function to build a word processing dictionary (word -> ix)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Build word vocabulary function defbuild_vocab(text, min_word_freq): word_counts = collections.Counter(text.split(' ')) # limit word counts to those more frequent than cutoff word_counts = {key:val for key, val in word_counts.items() if val>min_word_freq} # Create vocab --> index mapping words = word_counts.keys() vocab_to_ix_dict = {key:(ix+1) for ix, key in enumerate(words)} # Add unknown key --> 0 index vocab_to_ix_dict['unknown']=0 # Create index --> vocab mapping ix_to_vocab_dict = {val:key for key,val in vocab_to_ix_dict.items()}
return(ix_to_vocab_dict, vocab_to_ix_dict)
Now we can build the index-vocabulary from the Shakespeare data.
# Convert text to word vectors s_text_words = s_text.split(' ') s_text_ix = [] for ix, x in enumerate(s_text_words): try: s_text_ix.append(vocab2ix[x]) except: s_text_ix.append(0) s_text_ix = np.array(s_text_ix)
Building Shakespeare Vocab
Vocabulary Length = 8009
We define the LSTM model. The methods of interest are the __init__() method, which defines all the model variables and operations, and the sample() method which takes in a sample word and loops through to generate text.
embedding_output = tf.nn.embedding_lookup(embedding_mat, self.x_data) rnn_inputs = tf.split(axis=1, num_or_size_splits=self.training_seq_len, value=embedding_output) rnn_inputs_trimmed = [tf.squeeze(x, [1]) for x in rnn_inputs]
# If we are inferring (generating text), we add a 'loop' function # Define how to get the i+1 th input from the i th output definferred_loop(prev, count): # Apply hidden layer prev_transformed = tf.matmul(prev, W) + b # Get the index of the output (also don't run the gradient) prev_symbol = tf.stop_gradient(tf.argmax(prev_transformed, 1)) # Get embedded vector output = tf.nn.embedding_lookup(embedding_mat, prev_symbol) return(output)
decoder = tf.contrib.legacy_seq2seq.rnn_decoder outputs, last_state = decoder(rnn_inputs_trimmed, self.initial_state, self.lstm_cell, loop_function=inferred_loop if infer_sample elseNone) # Non inferred outputs output = tf.reshape(tf.concat(axis=1, values=outputs), [-1, self.rnn_size]) # Logits and output self.logit_output = tf.matmul(output, W) + b self.model_output = tf.nn.softmax(self.logit_output)
# Tell TensorFlow we are reusing the scope for the testing with tf.variable_scope(tf.get_variable_scope(), reuse=True): test_lstm_model = LSTM_Model(embedding_size, rnn_size, batch_size, learning_rate, training_seq_len, vocab_size, infer_sample=True)
We need to save the model, so we create a model saving operation.
1 2
# Create model saver saver = tf.train.Saver(tf.global_variables())
Let’s calculate how many batches are needed for each epoch and split up the data accordingly.
1 2 3 4 5 6
# Create batches for each epoch num_batches = int(len(s_text_ix)/(batch_size * training_seq_len)) + 1 # Split up text indices into subarrays, of equal size batches = np.array_split(s_text_ix, num_batches) # Reshape each split into [batch_size, training_seq_len] batches = [np.resize(x, [batch_size, training_seq_len]) for x in batches]
Initialize all the variables
1 2 3
# Initialize all variables init = tf.global_variables_initializer() sess.run(init)
# Train model train_loss = [] iteration_count = 1 for epoch in range(epochs): # Shuffle word indices random.shuffle(batches) # Create targets from shuffled batches targets = [np.roll(x, -1, axis=1) for x in batches] # Run a through one epoch print('Starting Epoch #{} of {}.'.format(epoch+1, epochs)) # Reset initial LSTM state every epoch state = sess.run(lstm_model.initial_state) for ix, batch in enumerate(batches): training_dict = {lstm_model.x_data: batch, lstm_model.y_output: targets[ix]} c, h = lstm_model.initial_state training_dict[c] = state.c training_dict[h] = state.h
# Print status every 10 gens if iteration_count % 10 == 0: summary_nums = (iteration_count, epoch+1, ix+1, num_batches+1, temp_loss) print('Iteration: {}, Epoch: {}, Batch: {} out of {}, Loss: {:.2f}'.format(*summary_nums))
# Save the model and the vocab if iteration_count % save_every == 0: # Save model model_file_name = os.path.join(full_model_dir, 'model') saver.save(sess, model_file_name, global_step = iteration_count) print('Model Saved To: {}'.format(model_file_name)) # Save vocabulary dictionary_file = os.path.join(full_model_dir, 'vocab.pkl') with open(dictionary_file, 'wb') as dict_file_conn: pickle.dump([vocab2ix, ix2vocab], dict_file_conn)
if iteration_count % eval_every == 0: for sample in prime_texts: print(test_lstm_model.sample(sess, ix2vocab, vocab2ix, num=10, prime_text=sample))
iteration_count += 1
Starting Epoch #1 of 10.
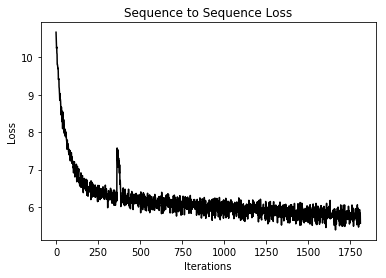
Iteration: 10, Epoch: 1, Batch: 10 out of 182, Loss: 9.73
thou art more curtain show'rs to the
to be or not to the
wherefore art thou art needs to the
...
Iteration: 1800, Epoch: 10, Batch: 171 out of 182, Loss: 5.71
thou art more than a
to be or not to be
wherefore art thou dost wedded not make me a
Iteration: 1810, Epoch: 10, Batch: 181 out of 182, Loss: 5.56
Here is a plot of the training loss across the iterations.
1 2 3 4 5 6
# Plot loss over time plt.plot(train_loss, 'k-') plt.title('Sequence to Sequence Loss') plt.xlabel('Iterations') plt.ylabel('Loss') plt.show()