Convolutional Neural Networks
CIFAR-10 CNN
In this example, we will download the CIFAR-10 images and build a CNN model with dropout and regularization.
CIFAR is composed ot 50k train and 10k test images that are 32x32.
We start by loading the necessary libaries and resetting any default computational graph that already exists.
1 | import os |
Next, start a new graph session and set the default parameters.
List of defaults:
batch_size: this is how many cifar examples to train on in one batch.data_dir: where to store data (check if data exists here, as to not have to download every time).output_every: output training accuracy/loss statistics every X generations/epochs.eval_every: output test accuracy/loss statistics every X generations/epochs.image_height: standardize images to this height.image_width: standardize images to this width.crop_height: random internal crop before training on image - height.crop_width: random internal crop before training on image - width.num_channels: number of color channels of image (greyscale = 1, color = 3).num_targets: number of different target categories. CIFAR-10 has 10.extract_folder: folder to extract downloaded images to.
1 | # Start a graph session |
Set the learning rate, learning rate decay parameters, and extract some of the image-model parameters.
1 | # Exponential Learning Rate Decay Params |
Load the CIFAR-10 data.
1 | # Load data |
Downloading http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz - 100.00%
Next, we define a reading function that will load (and optionally distort the images slightly) for training.
1 | # Define CIFAR reader |
Use the above loading function in our image pipeline function below.
1 | # Create a CIFAR image pipeline from reader |
Create a function that returns our CIFAR-10 model architecture so that we can use it both for training and testing.
1 | # Define the model architecture, this will return logits from images |
Define our loss function. Our loss will be the average cross entropy loss (categorical loss).
1 | # Loss function |
Define our training step. Here we will use exponential decay of the learning rate, declare the optimizer and tell the training step to minimize the loss.
1 | # Train step |
Create an accuracy function that takes in the predicted logits from the model and the actual targets and returns the accuracy for recording statistics on the train/test sets.
1 | # Accuracy function |
Now that we have all our functions we need, let’s use them to create
our data pipeline
our model
the evaluations/accuracy/training operations.
First our data pipeline:
1 | # Get data |
Getting/Transforming Data.
Create our model.
Note: Be careful not to accidentally run the following model-creation code twice without resetting the computational graph. If you do, you will end up with variable-sharing errors. If that is the case, re-run the whole script.
1 | # Declare Model |
Creating the CIFAR10 Model.
Done.
Loss and accuracy functions:
1 | # Declare loss function |
Declare Loss Function.
Next, create the training operations and initialize our model variables.
1 | # Create training operations |
Creating the Training Operation.
Initializing the Variables.
Now, we initialize our data queue. This is an operation that will feed data into our model. Because of this _no placeholders are necessary_!!
1 | # Initialize queue (This queue will feed into the model, so no placeholders necessary) |
[<Thread(QueueRunnerThread-input_producer-input_producer/input_producer_EnqueueMany, started daemon 140554214045440)>,
<Thread(QueueRunnerThread-shuffle_batch/random_shuffle_queue-shuffle_batch/random_shuffle_queue_enqueue, started daemon 140554205652736)>,
<Thread(QueueRunnerThread-input_producer_1-input_producer_1/input_producer_1_EnqueueMany, started daemon 140554176296704)>,
<Thread(QueueRunnerThread-shuffle_batch_1/random_shuffle_queue-shuffle_batch_1/random_shuffle_queue_enqueue, started daemon 140553878501120)>]
Training our CIFAR-10 model.
1 | # Train CIFAR Model |
Starting Training
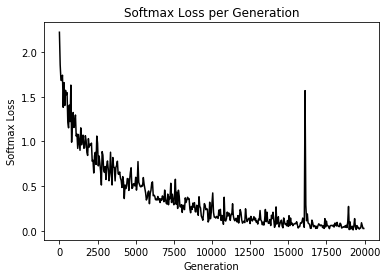
Generation 50: Loss = 2.22219
...
Generation 19950: Loss = 0.02510
Generation 20000: Loss = 0.02570
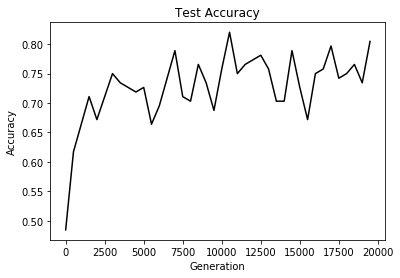
--- Test Accuracy = 80.47%.
Plot the loss and accuracy.
1 | # Print loss and accuracy |