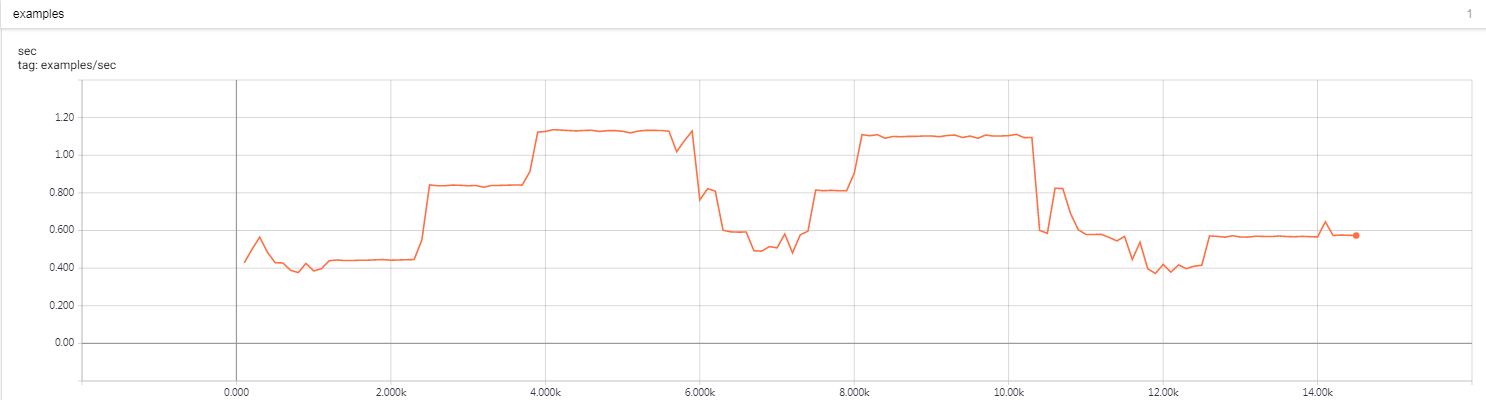
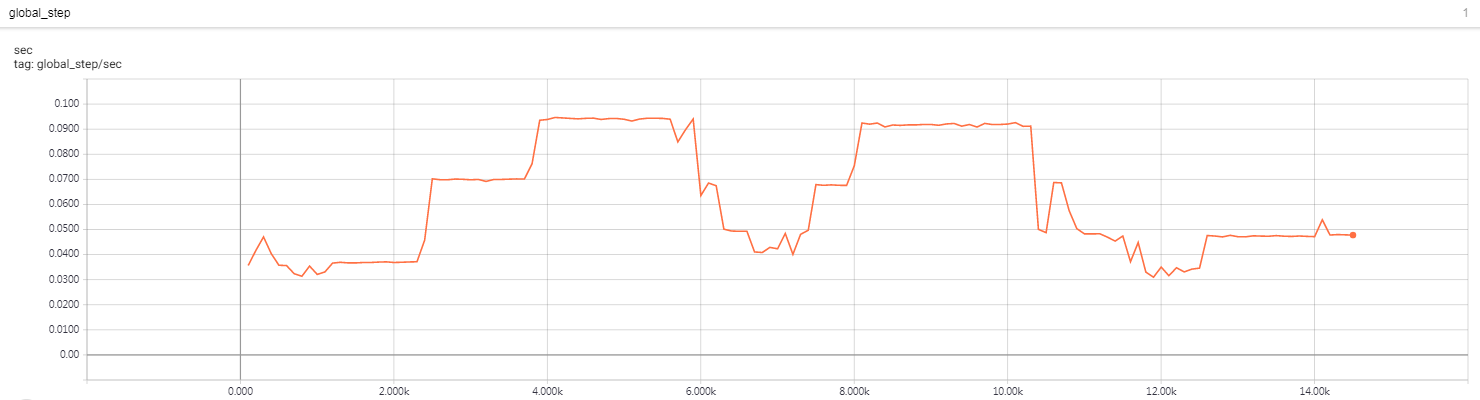
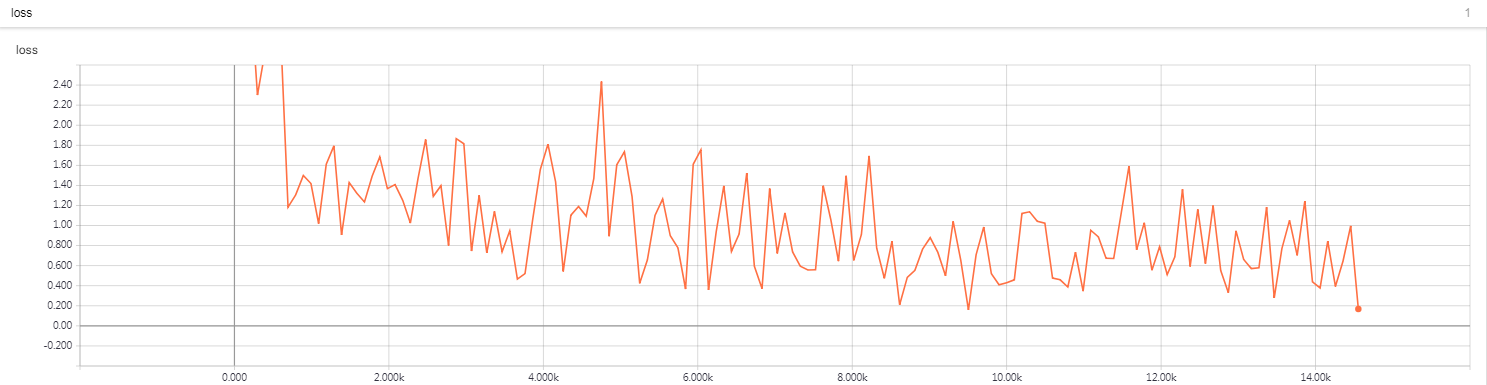
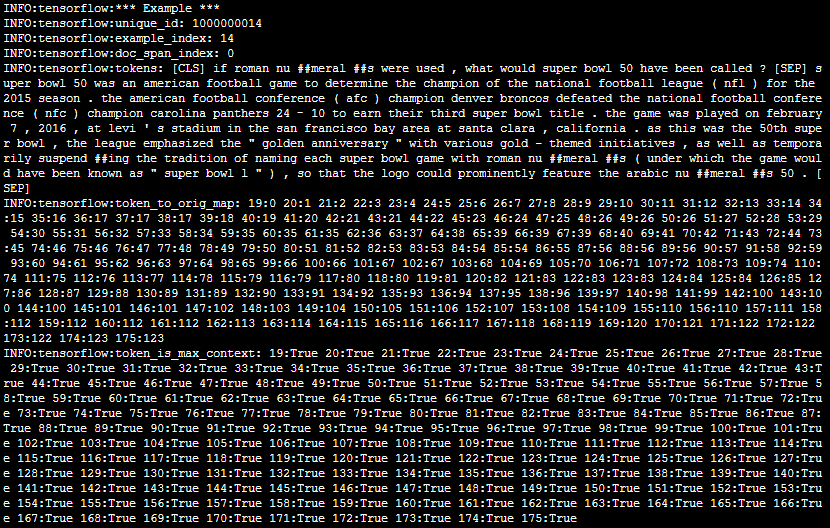
‘’’ a paragraphs in original SQUAD DATA {‘paragraphs’: [{‘context’: ‘Architecturally, the school has a Catholic ‘ “character. Atop the Main Building’s gold dome is “ ‘a golden statue of the Virgin Mary. Immediately ‘ ‘in front of the Main Building and facing it, is a ‘ ‘copper statue of Christ with arms upraised with ‘ ‘the legend “Venite Ad Me Omnes”. Next to the Main ‘ ‘Building is the Basilica of the Sacred Heart. ‘ ‘Immediately behind the basilica is the Grotto, a ‘ ‘Marian place of prayer and reflection. It is a ‘ ‘replica of the grotto at Lourdes, France where ‘ ‘the Virgin Mary reputedly appeared to Saint ‘ ‘Bernadette Soubirous in 1858. At the end of the ‘ ‘main drive (and in a direct line that connects ‘ ‘through 3 statues and the Gold Dome), is a ‘ ‘simple, modern stone statue of Mary.’, ‘qas’: [{‘answers’: [{‘answer_start’: 515, ‘text’: ‘Saint Bernadette Soubirous’}], ‘id’: ‘5733be284776f41900661182’, ‘question’: ‘To whom did the Virgin Mary allegedly ‘ ‘appear in 1858 in Lourdes France?’}, {‘answers’: [{‘answer_start’: 188, ‘text’: ‘a copper statue of Christ’}], ‘id’: ‘5733be284776f4190066117f’, ‘question’: ‘What is in front of the Notre Dame Main ‘ ‘Building?’}, {‘answers’: [{‘answer_start’: 279, ‘text’: ‘the Main Building’}], ‘id’: ‘5733be284776f41900661180’, ‘question’: ‘The Basilica of the Sacred heart at ‘ ‘Notre Dame is beside to which ‘ ‘structure?’}, {‘answers’: [{‘answer_start’: 381, ‘text’: ‘a Marian place of prayer and ‘ ‘reflection’}], ‘id’: ‘5733be284776f41900661181’, ‘question’: ‘What is the Grotto at Notre Dame?’}, {‘answers’: [{‘answer_start’: 92, ‘text’: ‘a golden statue of the Virgin ‘ ‘Mary’}], ‘id’: ‘5733be284776f4190066117e’, ‘question’: ‘What sits on top of the Main Building ‘ ‘at Notre Dame?’}]}, ‘’’
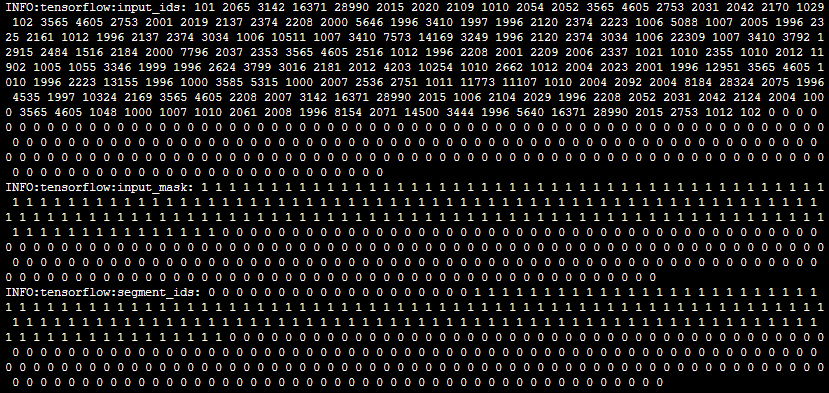
defread_squad_examples(input_file, is_training): """Read a SQuAD json file into a list of SquadExample.""" with tf.gfile.Open(input_file, "r") as reader: input_data = json.load(reader)["data"]
defis_whitespace(c): if c == " "or c == "\t"or c == "\r"or c == "\n"or ord(c) == 0x202F: returnTrue returnFalse
examples = [] for entry in input_data: for paragraph in entry["paragraphs"]: paragraph_text = paragraph["context"] doc_tokens = [] char_to_word_offset = [] prev_is_whitespace = True for c in paragraph_text: if is_whitespace(c): prev_is_whitespace = True else: if prev_is_whitespace: doc_tokens.append(c) else: doc_tokens[-1] += c prev_is_whitespace = False char_to_word_offset.append(len(doc_tokens) - 1)
for qa in paragraph["qas"]: qas_id = qa["id"] question_text = qa["question"] start_position = None end_position = None orig_answer_text = None if is_training: if len(qa["answers"]) != 1: raise ValueError( "For training, each question should have exactly 1 answer.") answer = qa["answers"][0] orig_answer_text = answer["text"] answer_offset = answer["answer_start"] answer_length = len(orig_answer_text) start_position = char_to_word_offset[answer_offset] end_position = char_to_word_offset[answer_offset + answer_length - 1] # Only add answers where the text can be exactly recovered from the # document. If this CAN'T happen it's likely due to weird Unicode # stuff so we will just skip the example. # # Note that this means for training mode, every example is NOT # guaranteed to be preserved. actual_text = " ".join(doc_tokens[start_position:(end_position + 1)]) cleaned_answer_text = " ".join( tokenization.whitespace_tokenize(orig_answer_text)) if actual_text.find(cleaned_answer_text) == -1: tf.logging.warning("Could not find answer: '%s' vs. '%s'", actual_text, cleaned_answer_text) continue
def_check_is_max_context(doc_spans, cur_span_index, position): """Check if this is the 'max context' doc span for the token."""
# Because of the sliding window approach taken to scoring documents, a single # token can appear in multiple documents. E.g. # Doc: the man went to the store and bought a gallon of milk # Span A: the man went to the # Span B: to the store and bought # Span C: and bought a gallon of # ... # # Now the word 'bought' will have two scores from spans B and C. We only # want to consider the score with "maximum context", which we define as # the *minimum* of its left and right context (the *sum* of left and # right context will always be the same, of course). # # In the example the maximum context for 'bought' would be span C since # it has 1 left context and 3 right context, while span B has 4 left context # and 0 right context. best_score = None best_span_index = None for (span_index, doc_span) in enumerate(doc_spans): end = doc_span.start + doc_span.length - 1 if position < doc_span.start: continue if position > end: continue num_left_context = position - doc_span.start num_right_context = end - position score = min(num_left_context, num_right_context) + 0.01 * doc_span.length if best_score isNoneor score > best_score: best_score = score best_span_index = span_index
with tf.gfile.Open(input_file_path, "r") as reader: input_data = json.load(reader)["data"]
1
a_input_data = input_data[0]
paragraph
1 2 3
for paragraph in a_input_data["paragraphs"][:2]: print('-'*100) pprint.pprint(paragraph)
----------------------------------------------------------------------------------------------------
{'context': 'Architecturally, the school has a Catholic character. Atop the '
"Main Building's gold dome is a golden statue of the Virgin Mary. "
'Immediately in front of the Main Building and facing it, is a '
'copper statue of Christ with arms upraised with the legend '
'"Venite Ad Me Omnes". Next to the Main Building is the Basilica '
'of the Sacred Heart. Immediately behind the basilica is the '
'Grotto, a Marian place of prayer and reflection. It is a replica '
'of the grotto at Lourdes, France where the Virgin Mary reputedly '
'appeared to Saint Bernadette Soubirous in 1858. At the end of the '
'main drive (and in a direct line that connects through 3 statues '
'and the Gold Dome), is a simple, modern stone statue of Mary.',
'qas': [{'answers': [{'answer_start': 515,
'text': 'Saint Bernadette Soubirous'}],
'id': '5733be284776f41900661182',
'question': 'To whom did the Virgin Mary allegedly appear in 1858 in '
'Lourdes France?'},
{'answers': [{'answer_start': 188,
'text': 'a copper statue of Christ'}],
'id': '5733be284776f4190066117f',
'question': 'What is in front of the Notre Dame Main Building?'},
{'answers': [{'answer_start': 279, 'text': 'the Main Building'}],
'id': '5733be284776f41900661180',
'question': 'The Basilica of the Sacred heart at Notre Dame is '
'beside to which structure?'},
{'answers': [{'answer_start': 381,
'text': 'a Marian place of prayer and reflection'}],
'id': '5733be284776f41900661181',
'question': 'What is the Grotto at Notre Dame?'},
{'answers': [{'answer_start': 92,
'text': 'a golden statue of the Virgin Mary'}],
'id': '5733be284776f4190066117e',
'question': 'What sits on top of the Main Building at Notre Dame?'}]}
----------------------------------------------------------------------------------------------------
{'context': "As at most other universities, Notre Dame's students run a number "
'of news media outlets. The nine student-run outlets include three '
'newspapers, both a radio and television station, and several '
'magazines and journals. Begun as a one-page journal in September '
'1876, the Scholastic magazine is issued twice monthly and claims '
'to be the oldest continuous collegiate publication in the United '
'States. The other magazine, The Juggler, is released twice a year '
'and focuses on student literature and artwork. The Dome yearbook '
'is published annually. The newspapers have varying publication '
'interests, with The Observer published daily and mainly reporting '
'university and other news, and staffed by students from both '
"Notre Dame and Saint Mary's College. Unlike Scholastic and The "
'Dome, The Observer is an independent publication and does not '
'have a faculty advisor or any editorial oversight from the '
'University. In 1987, when some students believed that The '
'Observer began to show a conservative bias, a liberal newspaper, '
'Common Sense was published. Likewise, in 2003, when other '
'students believed that the paper showed a liberal bias, the '
'conservative paper Irish Rover went into production. Neither '
'paper is published as often as The Observer; however, all three '
'are distributed to all students. Finally, in Spring 2008 an '
'undergraduate journal for political science research, Beyond '
'Politics, made its debut.',
'qas': [{'answers': [{'answer_start': 248, 'text': 'September 1876'}],
'id': '5733bf84d058e614000b61be',
'question': 'When did the Scholastic Magazine of Notre dame begin '
'publishing?'},
{'answers': [{'answer_start': 441, 'text': 'twice'}],
'id': '5733bf84d058e614000b61bf',
'question': "How often is Notre Dame's the Juggler published?"},
{'answers': [{'answer_start': 598, 'text': 'The Observer'}],
'id': '5733bf84d058e614000b61c0',
'question': 'What is the daily student paper at Notre Dame called?'},
{'answers': [{'answer_start': 126, 'text': 'three'}],
'id': '5733bf84d058e614000b61bd',
'question': 'How many student news papers are found at Notre Dame?'},
{'answers': [{'answer_start': 908, 'text': '1987'}],
'id': '5733bf84d058e614000b61c1',
'question': 'In what year did the student paper Common Sense begin '
'publication at Notre Dame?'}]}
a_paragraph_text = '''Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart.'''
333
Architecturally, the school has a Catholic character. Atop the Main Building's gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
doc_tokens = [] char_to_word_offset = [] prev_is_whitespace = True # for c in paragraph_text: for c in a_paragraph_text: if is_whitespace(c): prev_is_whitespace = True else: if prev_is_whitespace: doc_tokens.append(c) else: doc_tokens[-1] += c prev_is_whitespace = False char_to_word_offset.append(len(doc_tokens) - 1)
‘Architecturally, the school has a Catholic character. Atop the ‘ “Main Building’s gold dome is a golden statue of the Virgin Mary. “ ‘Immediately in front of the Main Building and facing it, is a ‘ ‘copper statue of Christ with arms upraised with the legend ‘ ‘“Venite Ad Me Omnes”. Next to the Main Building is the Basilica ‘ ‘of the Sacred Heart. Immediately behind the basilica is the ‘ ‘Grotto, a Marian place of prayer and reflection. It is a replica ‘ ‘of the grotto at Lourdes, France where the Virgin Mary reputedly ‘ ‘appeared to Saint Bernadette Soubirous in 1858. At the end of the ‘ ‘main drive (and in a direct line that connects through 3 statues ‘ ‘and the Gold Dome), is a simple, modern stone statue of Mary.’,
# The -3 accounts for [CLS], [SEP] and [SEP] #max_tokens_for_doc = max_seq_length - len(query_tokens) - 3 max_tokens_for_doc = 100 - 20-3 doc_stride = 128
# We can have documents that are longer than the maximum sequence length. # To deal with this we do a sliding window approach, where we take chunks # of the up to our max length with a stride of `doc_stride`. _DocSpan = collections.namedtuple( # pylint: disable=invalid-name "DocSpan", ["start", "length"]) doc_spans = [] start_offset = 0 while start_offset < len(all_doc_tokens): length = len(all_doc_tokens) - start_offset if length > max_tokens_for_doc: length = max_tokens_for_doc doc_spans.append(_DocSpan(start=start_offset, length=length)) if start_offset + length == len(all_doc_tokens): break start_offset += min(length, doc_stride) print("max_tokens_for_doc:\t",max_tokens_for_doc) print("doc_spans:\t",doc_spans)