摘要:迁移学习为计算机视觉带来了巨大改变,但是现有的NLP技术仍需要针对具体任务改进模型,并且从零开始训练。我们提出了一种有效的迁移学习方法,可以应用到NLP领域的任何一种任务上,同时提出的技术对调整语言模型来说非常关键。我们的方法在六种文本分类任务上比现有的技术都要优秀,除此之外,这种方法仅用100个带有标签的样本进行训练,最终的性能就达到了从零开始、拥有上万个训练数据的模型性能。
Universal Language Model Fine-tuning for Text Classification
Jeremy Howard, Sebastian Ruder
(Submitted on 18 Jan 2018 (v1), last revised 23 May 2018 (this version, v5))
Inductive transfer learning has greatly impacted computer vision, but existing approaches in NLP still require task-specific modifications and training from scratch. We propose Universal Language Model Fine-tuning (ULMFiT), an effective transfer learning method that can be applied to any task in NLP, and introduce techniques that are key for fine-tuning a language model. Our method significantly outperforms the state-of-the-art on six text classification tasks, reducing the error by 18-24% on the majority of datasets. Furthermore, with only 100 labeled examples, it matches the performance of training from scratch on 100x more data. We open-source our pretrained models and code.
Comments: ACL 2018, fixed denominator in Equation 3, line 3
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG); Machine Learning (stat.ML)
Cite as: arXiv:1801.06146 [cs.CL]
(or arXiv:1801.06146v5 [cs.CL] for this version)
ULMFiT 相关资源
| 标题 | 说明 | 附加 |
|---|---|---|
| Universal Language Model Fine-tuning for Text Classification | 原始论文 | 20180118 |
| 比word2vec更好的ULMFiT | 解读 | 20180801 |
【NLP】语言模型和迁移学习
本文主要对ELMo、ULMFiT以及OpenAI GPT三种预训练语言模型作简要介绍。
ULMFiT是一种有效的NLP迁移学习方法,核心思想是通过精调预训练的语言模型完成其他NLP任务。文中所用的语言模型参考了Merity et al. 2017a的AWD-LSTM模型,即没有attention或shortcut的三层LSTM模型。
ULMFiT的过程分为三步: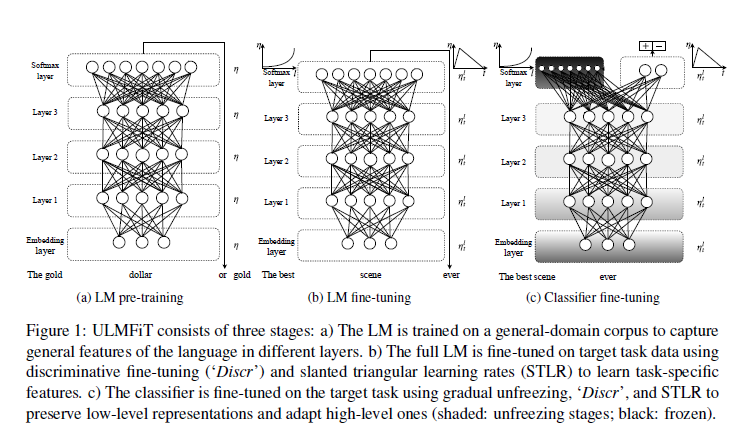
General-domain LM pre-train
在Wikitext-103上进行语言模型的预训练。
预训练的语料要求:large & capture general properties of language
预训练对小数据集十分有效,之后仅有少量样本就可以使模型泛化。
Target task LM fine-tuning
文中介绍了两种fine-tuning方法:
Discriminative fine-tuning
因为网络中不同层可以捕获不同类型的信息,因此在精调时也应该使用不同的learning rate。作者为每一层赋予一个学习率 $\eta^{l}$ ,实验后发现,首先通过精调模型的最后一层L确定学习率 $\eta^{L}$ ,再递推地选择上一层学习率进行精调的效果最好,递推公式为: $\eta^{l-1} = \eta^{l}/2.6$
Slanted triangular learning rates (STLR)
为了针对特定任务选择参数,理想情况下需要在训练开始时让参数快速收敛到一个合适的区域,之后进行精调。为了达到这种效果,作者提出STLR方法,即让LR在训练初期短暂递增,在之后下降。如图b的右上角所示。具体的公式为:
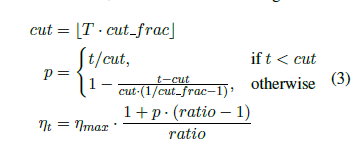
where T is the number of training iterations;cut frac is the fraction of iterations we increase the LR;p is the fraction of the number of iterations we have increased or will decrease the LR respectively, ratio specifies how much smaller the lowest LR is from the maximum LR ηmax, and ηt is the learning rate at iteration t.
We generally use cut frac = 0:1, ratio = 32 and max = 0:01.
简单地说就是在一个训练周期内学习率以 cut 为界呈斜三角变化,在 cut 之前学习率快速升高,在 cut 之后学习率缓慢减小,如下图所示。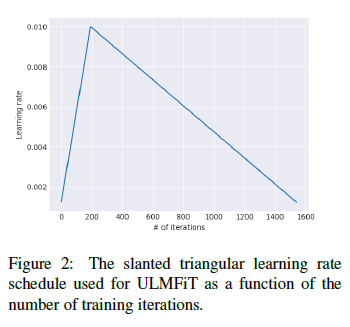
Target task classifier fine-tuning
为了完成分类任务的精调,作者在最后一层添加了两个线性block,每个都有batch-norm和dropout,使用ReLU作为中间层激活函数,最后经过softmax输出分类的概率分布。最后的精调涉及的环节如下:
Concat pooling
第一个线性层的输入是最后一个隐层状态的池化。因为文本分类的关键信息可能在文本的任何地方,所以只是用最后时间步的输出是不够的。作者将最后时间步 h_{T} 与尽可能多的时间步 $H= {h_{1},… , h_{T}} $ 池化后拼接起来,以 $h_{c} = [h_{T}, maxpool(H), meanpool(H)] $ 作为输入。
Gradual unfreezing
由于过度精调会导致模型遗忘之前预训练得到的信息,作者提出逐渐unfreez网络层的方法,从最后一层开始unfreez和精调,由后向前地unfreez并精调所有层。
BPTT for Text Classification (BPT3C)
为了在large documents上进行模型精调,作者将文档分为固定长度为b的batches,并在每个batch训练时记录mean和max池化,梯度会被反向传播到对最终预测有贡献的batches。
Bidirectional language model
在作者的实验中,分别独立地对前向和后向LM做了精调,并将两者的预测结果平均。两者结合后结果有0.5-0.7的提升。
使用 ULMFiT
https://github.com/fastai/fastai/tree/master/courses/dl2/imdb_scripts
更多参见 FAST.AI NLP http://nlp.fast.ai/category/classification.html
fine-tuned language model with gradual unfreezing, discriminative fine-tuning, and slanted triangular learning rates.
Instructions
- Preparing Wikipedia
- Tokenization
- Mapping tokens to ids
- Fine-tune the LM(download the pre-trained models) or Pretrain the Wikipedia language model(from scrach)
- Train the classifier
- Evaluate the classifier
- Try the classifier on text

