Amazing! This box of cereal gave me a perfectly balanced breakfast, as all things should be. In only ate half of it but will definitely be buying again!
我们会重点关注其中的一些词,对它们进行处理
Amazing! This box of cereal gave me a perfectly balanced breakfast, as all things should be. In only ate half of it but will definitely be buying again!
“””Module implementing RNN Cells. This module provides a number of basic commonly used RNN cells, such as LSTM (Long Short Term Memory) or GRU (Gated Recurrent Unit), and a number of operators that allow adding dropouts, projections, or embeddings for inputs. Constructing multi-layer cells is supported by the class MultiRNNCell, or by calling the rnn ops several times. “””
class RNNCell(base_layer.Layer)
重点:
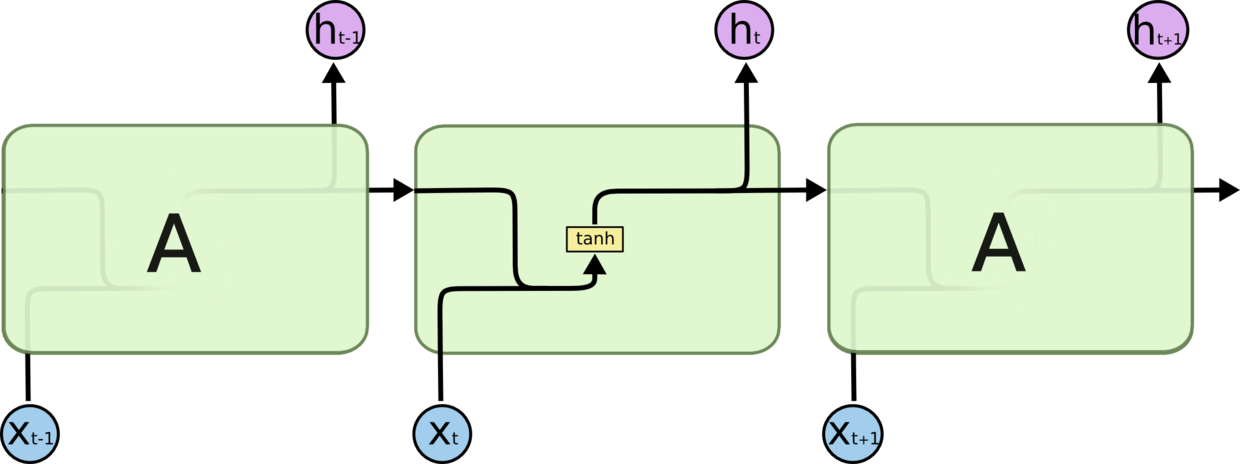
Every RNNCell must have the properties below and implement call with the signature (output, next_state) = call(input, state).
An RNN cell, in the most abstract setting, is anything that has a state and performs some operation that takes a matrix of inputs.This operation results in an output matrix with self.output_size columns.
@tf_export("nn.rnn_cell.RNNCell") classRNNCell(base_layer.Layer): """Abstract object representing an RNN cell. Every `RNNCell` must have the properties below and implement `call` with the signature `(output, next_state) = call(input, state)`. The optional third input argument, `scope`, is allowed for backwards compatibility purposes; but should be left off for new subclasses. This definition of cell differs from the definition used in the literature. In the literature, 'cell' refers to an object with a single scalar output. This definition refers to a horizontal array of such units. An RNN cell, in the most abstract setting, is anything that has a state and performs some operation that takes a matrix of inputs. This operation results in an output matrix with `self.output_size` columns. If `self.state_size` is an integer, this operation also results in a new state matrix with `self.state_size` columns. If `self.state_size` is a (possibly nested tuple of) TensorShape object(s), then it should return a matching structure of Tensors having shape `[batch_size].concatenate(s)` for each `s` in `self.batch_size`. """
def__init__(self, trainable=True, name=None, dtype=None, **kwargs): super(RNNCell, self).__init__( trainable=trainable, name=name, dtype=dtype, **kwargs) # Attribute that indicates whether the cell is a TF RNN cell, due the slight # difference between TF and Keras RNN cell. self._is_tf_rnn_cell = True
def__call__(self, inputs, state, scope=None): """Run this RNN cell on inputs, starting from the given state. Args: inputs: `2-D` tensor with shape `[batch_size, input_size]`. state: if `self.state_size` is an integer, this should be a `2-D Tensor` with shape `[batch_size, self.state_size]`. Otherwise, if `self.state_size` is a tuple of integers, this should be a tuple with shapes `[batch_size, s] for s in self.state_size`. scope: VariableScope for the created subgraph; defaults to class name. Returns: A pair containing: - Output: A `2-D` tensor with shape `[batch_size, self.output_size]`. - New state: Either a single `2-D` tensor, or a tuple of tensors matching the arity and shapes of `state`. """ if scope isnotNone: with vs.variable_scope(scope, custom_getter=self._rnn_get_variable) as scope: return super(RNNCell, self).__call__(inputs, state, scope=scope) else: scope_attrname = "rnncell_scope" scope = getattr(self, scope_attrname, None) if scope isNone: scope = vs.variable_scope(vs.get_variable_scope(), custom_getter=self._rnn_get_variable) setattr(self, scope_attrname, scope) with scope: return super(RNNCell, self).__call__(inputs, state)
def_rnn_get_variable(self, getter, *args, **kwargs): variable = getter(*args, **kwargs) if context.executing_eagerly(): trainable = variable._trainable # pylint: disable=protected-access else: trainable = ( variable in tf_variables.trainable_variables() or (isinstance(variable, tf_variables.PartitionedVariable) and list(variable)[0] in tf_variables.trainable_variables())) if trainable and variable notin self._trainable_weights: self._trainable_weights.append(variable) elifnot trainable and variable notin self._non_trainable_weights: self._non_trainable_weights.append(variable) return variable
@property defstate_size(self): """size(s) of state(s) used by this cell. It can be represented by an Integer, a TensorShape or a tuple of Integers or TensorShapes. """ raise NotImplementedError("Abstract method")
@property defoutput_size(self): """Integer or TensorShape: size of outputs produced by this cell.""" raise NotImplementedError("Abstract method")
defbuild(self, _): # This tells the parent Layer object that it's OK to call # self.add_variable() inside the call() method. pass
defget_initial_state(self, inputs=None, batch_size=None, dtype=None): if inputs isnotNone: # Validate the given batch_size and dtype against inputs if provided. inputs = ops.convert_to_tensor(inputs, name="inputs") if batch_size isnotNone: if tensor_util.is_tensor(batch_size): static_batch_size = tensor_util.constant_value( batch_size, partial=True) else: static_batch_size = batch_size if inputs.shape.dims[0].value != static_batch_size: raise ValueError( "batch size from input tensor is different from the " "input param. Input tensor batch: {}, batch_size: {}".format( inputs.shape.dims[0].value, batch_size))
if dtype isnotNoneand inputs.dtype != dtype: raise ValueError( "dtype from input tensor is different from the " "input param. Input tensor dtype: {}, dtype: {}".format( inputs.dtype, dtype))
batch_size = inputs.shape.dims[0].value or array_ops.shape(inputs)[0] dtype = inputs.dtype ifNonein [batch_size, dtype]: raise ValueError( "batch_size and dtype cannot be None while constructing initial " "state: batch_size={}, dtype={}".format(batch_size, dtype)) return self.zero_state(batch_size, dtype)
defzero_state(self, batch_size, dtype): """Return zero-filled state tensor(s). Args: batch_size: int, float, or unit Tensor representing the batch size. dtype: the data type to use for the state. Returns: If `state_size` is an int or TensorShape, then the return value is a `N-D` tensor of shape `[batch_size, state_size]` filled with zeros. If `state_size` is a nested list or tuple, then the return value is a nested list or tuple (of the same structure) of `2-D` tensors with the shapes `[batch_size, s]` for each s in `state_size`. """ # Try to use the last cached zero_state. This is done to avoid recreating # zeros, especially when eager execution is enabled. state_size = self.state_size is_eager = context.executing_eagerly() if is_eager and hasattr(self, "_last_zero_state"): (last_state_size, last_batch_size, last_dtype, last_output) = getattr(self, "_last_zero_state") if (last_batch_size == batch_size and last_dtype == dtype and last_state_size == state_size): return last_output with ops.name_scope(type(self).__name__ + "ZeroState", values=[batch_size]): output = _zero_state_tensors(state_size, batch_size, dtype) if is_eager: self._last_zero_state = (state_size, batch_size, dtype, output) return output
classLayerRNNCell(RNNCell): """Subclass of RNNCells that act like proper `tf.Layer` objects. For backwards compatibility purposes, most `RNNCell` instances allow their `call` methods to instantiate variables via `tf.get_variable`. The underlying variable scope thus keeps track of any variables, and returning cached versions. This is atypical of `tf.layer` objects, which separate this part of layer building into a `build` method that is only called once. Here we provide a subclass for `RNNCell` objects that act exactly as `Layer` objects do. They must provide a `build` method and their `call` methods do not access Variables `tf.get_variable`. """
def__call__(self, inputs, state, scope=None, *args, **kwargs): """Run this RNN cell on inputs, starting from the given state. Args: inputs: `2-D` tensor with shape `[batch_size, input_size]`. state: if `self.state_size` is an integer, this should be a `2-D Tensor` with shape `[batch_size, self.state_size]`. Otherwise, if `self.state_size` is a tuple of integers, this should be a tuple with shapes `[batch_size, s] for s in self.state_size`. scope: optional cell scope. *args: Additional positional arguments. **kwargs: Additional keyword arguments. Returns: A pair containing: - Output: A `2-D` tensor with shape `[batch_size, self.output_size]`. - New state: Either a single `2-D` tensor, or a tuple of tensors matching the arity and shapes of `state`. """ # Bypass RNNCell's variable capturing semantics for LayerRNNCell. # Instead, it is up to subclasses to provide a proper build # method. See the class docstring for more details. return base_layer.Layer.__call__(self, inputs, state, scope=scope, *args, **kwargs)
@tf_export(v1=["nn.rnn_cell.BasicRNNCell"]) classBasicRNNCell(LayerRNNCell): """The most basic RNN cell. Note that this cell is not optimized for performance. Please use `tf.contrib.cudnn_rnn.CudnnRNNTanh` for better performance on GPU. Args: num_units: int, The number of units in the RNN cell. activation: Nonlinearity to use. Default: `tanh`. It could also be string that is within Keras activation function names. reuse: (optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raised. name: String, the name of the layer. Layers with the same name will share weights, but to avoid mistakes we require reuse=True in such cases. dtype: Default dtype of the layer (default of `None` means use the type of the first input). Required when `build` is called before `call`. **kwargs: Dict, keyword named properties for common layer attributes, like `trainable` etc when constructing the cell from configs of get_config(). """
@deprecated(None, "This class is equivalent as tf.keras.layers.SimpleRNNCell," " and will be replaced by that in Tensorflow 2.0.") def__init__(self, num_units, activation=None, reuse=None, name=None, dtype=None, **kwargs): super(BasicRNNCell, self).__init__( _reuse=reuse, name=name, dtype=dtype, **kwargs) if context.executing_eagerly() and context.num_gpus() > 0: logging.warn("%s: Note that this cell is not optimized for performance. " "Please use tf.contrib.cudnn_rnn.CudnnRNNTanh for better " "performance on GPU.", self)
# Inputs must be 2-dimensional. self.input_spec = input_spec.InputSpec(ndim=2)
@tf_export(v1=["nn.rnn_cell.GRUCell"]) classGRUCell(LayerRNNCell): """Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078). Note that this cell is not optimized for performance. Please use `tf.contrib.cudnn_rnn.CudnnGRU` for better performance on GPU, or `tf.contrib.rnn.GRUBlockCellV2` for better performance on CPU. Args: num_units: int, The number of units in the GRU cell. activation: Nonlinearity to use. Default: `tanh`. reuse: (optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raised. kernel_initializer: (optional) The initializer to use for the weight and projection matrices. bias_initializer: (optional) The initializer to use for the bias. name: String, the name of the layer. Layers with the same name will share weights, but to avoid mistakes we require reuse=True in such cases. dtype: Default dtype of the layer (default of `None` means use the type of the first input). Required when `build` is called before `call`. **kwargs: Dict, keyword named properties for common layer attributes, like `trainable` etc when constructing the cell from configs of get_config(). """
@deprecated(None, "This class is equivalent as tf.keras.layers.GRUCell," " and will be replaced by that in Tensorflow 2.0.") def__init__(self, num_units, activation=None, reuse=None, kernel_initializer=None, bias_initializer=None, name=None, dtype=None, **kwargs): super(GRUCell, self).__init__( _reuse=reuse, name=name, dtype=dtype, **kwargs)
if context.executing_eagerly() and context.num_gpus() > 0: logging.warn("%s: Note that this cell is not optimized for performance. " "Please use tf.contrib.cudnn_rnn.CudnnGRU for better " "performance on GPU.", self) # Inputs must be 2-dimensional. self.input_spec = input_spec.InputSpec(ndim=2)
@tf_export("nn.rnn_cell.LSTMStateTuple") classLSTMStateTuple(_LSTMStateTuple): """Tuple used by LSTM Cells for `state_size`, `zero_state`, and output state. Stores two elements: `(c, h)`, in that order. Where `c` is the hidden state and `h` is the output. Only used when `state_is_tuple=True`. """ __slots__ = ()
@tf_export(v1=["nn.rnn_cell.BasicLSTMCell"]) classBasicLSTMCell(LayerRNNCell): """DEPRECATED: Please use `tf.nn.rnn_cell.LSTMCell` instead. Basic LSTM recurrent network cell. The implementation is based on: http://arxiv.org/abs/1409.2329. We add forget_bias (default: 1) to the biases of the forget gate in order to reduce the scale of forgetting in the beginning of the training. It does not allow cell clipping, a projection layer, and does not use peep-hole connections: it is the basic baseline. For advanced models, please use the full `tf.nn.rnn_cell.LSTMCell` that follows. Note that this cell is not optimized for performance. Please use `tf.contrib.cudnn_rnn.CudnnLSTM` for better performance on GPU, or `tf.contrib.rnn.LSTMBlockCell` and `tf.contrib.rnn.LSTMBlockFusedCell` for better performance on CPU. """
@deprecated(None, "This class is equivalent as tf.keras.layers.LSTMCell," " and will be replaced by that in Tensorflow 2.0.") def__init__(self, num_units, forget_bias=1.0, state_is_tuple=True, activation=None, reuse=None, name=None, dtype=None, **kwargs): """Initialize the basic LSTM cell. Args: num_units: int, The number of units in the LSTM cell. forget_bias: float, The bias added to forget gates (see above). Must set to `0.0` manually when restoring from CudnnLSTM-trained checkpoints. state_is_tuple: If True, accepted and returned states are 2-tuples of the `c_state` and `m_state`. If False, they are concatenated along the column axis. The latter behavior will soon be deprecated. activation: Activation function of the inner states. Default: `tanh`. It could also be string that is within Keras activation function names. reuse: (optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raised. name: String, the name of the layer. Layers with the same name will share weights, but to avoid mistakes we require reuse=True in such cases. dtype: Default dtype of the layer (default of `None` means use the type of the first input). Required when `build` is called before `call`. **kwargs: Dict, keyword named properties for common layer attributes, like `trainable` etc when constructing the cell from configs of get_config(). When restoring from CudnnLSTM-trained checkpoints, must use `CudnnCompatibleLSTMCell` instead. """ super(BasicLSTMCell, self).__init__( _reuse=reuse, name=name, dtype=dtype, **kwargs) ifnot state_is_tuple: logging.warn("%s: Using a concatenated state is slower and will soon be " "deprecated. Use state_is_tuple=True.", self) if context.executing_eagerly() and context.num_gpus() > 0: logging.warn("%s: Note that this cell is not optimized for performance. " "Please use tf.contrib.cudnn_rnn.CudnnLSTM for better " "performance on GPU.", self)
# Inputs must be 2-dimensional. self.input_spec = input_spec.InputSpec(ndim=2)
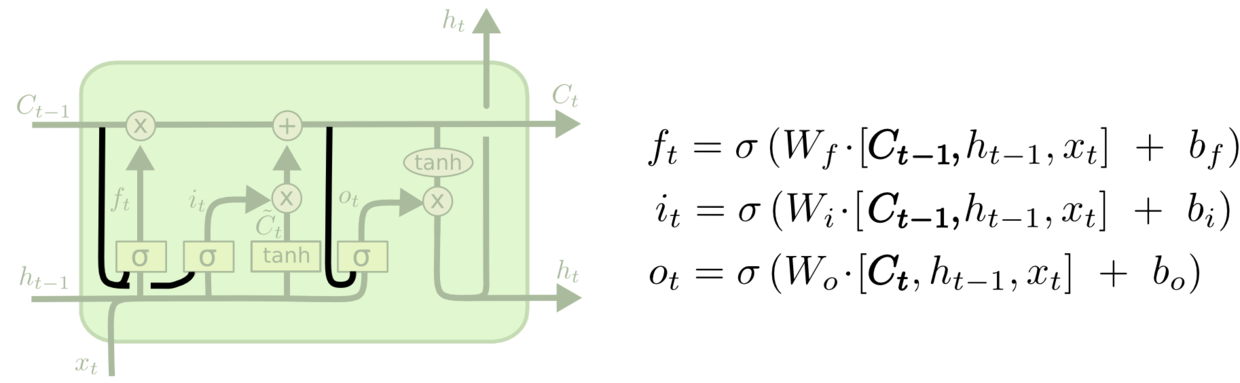
defcall(self, inputs, state): """Long short-term memory cell (LSTM). Args: inputs: `2-D` tensor with shape `[batch_size, input_size]`. state: An `LSTMStateTuple` of state tensors, each shaped `[batch_size, num_units]`, if `state_is_tuple` has been set to `True`. Otherwise, a `Tensor` shaped `[batch_size, 2 * num_units]`. Returns: A pair containing the new hidden state, and the new state (either a `LSTMStateTuple` or a concatenated state, depending on `state_is_tuple`). """ sigmoid = math_ops.sigmoid one = constant_op.constant(1, dtype=dtypes.int32) # Parameters of gates are concatenated into one multiply for efficiency. if self._state_is_tuple: c, h = state else: c, h = array_ops.split(value=state, num_or_size_splits=2, axis=one)
# i = input_gate, j = new_input, f = forget_gate, o = output_gate i, j, f, o = array_ops.split( value=gate_inputs, num_or_size_splits=4, axis=one)
forget_bias_tensor = constant_op.constant(self._forget_bias, dtype=f.dtype) # Note that using `add` and `multiply` instead of `+` and `*` gives a # performance improvement. So using those at the cost of readability. add = math_ops.add multiply = math_ops.multiply new_c = add(multiply(c, sigmoid(add(f, forget_bias_tensor))), multiply(sigmoid(i), self._activation(j))) new_h = multiply(self._activation(new_c), sigmoid(o))
forget_bias 作用 forget_bias: Biases of the forget gate are initialized by default to 1 in order to reduce the scale of forgetting at the beginning of the training. Must set it manually to 0.0 when restoring from CudnnLSTM trained checkpoints.
@tf_export(v1=["nn.rnn_cell.LSTMCell"]) classLSTMCell(LayerRNNCell): """Long short-term memory unit (LSTM) recurrent network cell. The default non-peephole implementation is based on: https://pdfs.semanticscholar.org/1154/0131eae85b2e11d53df7f1360eeb6476e7f4.pdf Felix Gers, Jurgen Schmidhuber, and Fred Cummins. "Learning to forget: Continual prediction with LSTM." IET, 850-855, 1999. The peephole implementation is based on: https://research.google.com/pubs/archive/43905.pdf Hasim Sak, Andrew Senior, and Francoise Beaufays. "Long short-term memory recurrent neural network architectures for large scale acoustic modeling." INTERSPEECH, 2014. The class uses optional peep-hole connections, optional cell clipping, and an optional projection layer. Note that this cell is not optimized for performance. Please use `tf.contrib.cudnn_rnn.CudnnLSTM` for better performance on GPU, or `tf.contrib.rnn.LSTMBlockCell` and `tf.contrib.rnn.LSTMBlockFusedCell` for better performance on CPU. """
@deprecated(None, "This class is equivalent as tf.keras.layers.LSTMCell," " and will be replaced by that in Tensorflow 2.0.") def__init__(self, num_units, use_peepholes=False, cell_clip=None, initializer=None, num_proj=None, proj_clip=None, num_unit_shards=None, num_proj_shards=None, forget_bias=1.0, state_is_tuple=True, activation=None, reuse=None, name=None, dtype=None, **kwargs): """Initialize the parameters for an LSTM cell. Args: num_units: int, The number of units in the LSTM cell. use_peepholes: bool, set True to enable diagonal/peephole connections. cell_clip: (optional) A float value, if provided the cell state is clipped by this value prior to the cell output activation. initializer: (optional) The initializer to use for the weight and projection matrices. num_proj: (optional) int, The output dimensionality for the projection matrices. If None, no projection is performed. proj_clip: (optional) A float value. If `num_proj > 0` and `proj_clip` is provided, then the projected values are clipped elementwise to within `[-proj_clip, proj_clip]`. num_unit_shards: Deprecated, will be removed by Jan. 2017. Use a variable_scope partitioner instead. num_proj_shards: Deprecated, will be removed by Jan. 2017. Use a variable_scope partitioner instead. forget_bias: Biases of the forget gate are initialized by default to 1 in order to reduce the scale of forgetting at the beginning of the training. Must set it manually to `0.0` when restoring from CudnnLSTM trained checkpoints. state_is_tuple: If True, accepted and returned states are 2-tuples of the `c_state` and `m_state`. If False, they are concatenated along the column axis. This latter behavior will soon be deprecated. activation: Activation function of the inner states. Default: `tanh`. It could also be string that is within Keras activation function names. reuse: (optional) Python boolean describing whether to reuse variables in an existing scope. If not `True`, and the existing scope already has the given variables, an error is raised. name: String, the name of the layer. Layers with the same name will share weights, but to avoid mistakes we require reuse=True in such cases. dtype: Default dtype of the layer (default of `None` means use the type of the first input). Required when `build` is called before `call`. **kwargs: Dict, keyword named properties for common layer attributes, like `trainable` etc when constructing the cell from configs of get_config(). When restoring from CudnnLSTM-trained checkpoints, use `CudnnCompatibleLSTMCell` instead. """ super(LSTMCell, self).__init__( _reuse=reuse, name=name, dtype=dtype, **kwargs) ifnot state_is_tuple: logging.warn("%s: Using a concatenated state is slower and will soon be " "deprecated. Use state_is_tuple=True.", self) if num_unit_shards isnotNoneor num_proj_shards isnotNone: logging.warn( "%s: The num_unit_shards and proj_unit_shards parameters are " "deprecated and will be removed in Jan 2017. " "Use a variable scope with a partitioner instead.", self) if context.executing_eagerly() and context.num_gpus() > 0: logging.warn("%s: Note that this cell is not optimized for performance. " "Please use tf.contrib.cudnn_rnn.CudnnLSTM for better " "performance on GPU.", self)
# Inputs must be 2-dimensional. self.input_spec = input_spec.InputSpec(ndim=2)
defcall(self, inputs, state): """Run one step of LSTM. Args: inputs: input Tensor, must be 2-D, `[batch, input_size]`. state: if `state_is_tuple` is False, this must be a state Tensor, `2-D, [batch, state_size]`. If `state_is_tuple` is True, this must be a tuple of state Tensors, both `2-D`, with column sizes `c_state` and `m_state`. Returns: A tuple containing: - A `2-D, [batch, output_dim]`, Tensor representing the output of the LSTM after reading `inputs` when previous state was `state`. Here output_dim is: num_proj if num_proj was set, num_units otherwise. - Tensor(s) representing the new state of LSTM after reading `inputs` when the previous state was `state`. Same type and shape(s) as `state`. Raises: ValueError: If input size cannot be inferred from inputs via static shape inference. """ num_proj = self._num_units if self._num_proj isNoneelse self._num_proj sigmoid = math_ops.sigmoid
input_size = inputs.get_shape().with_rank(2).dims[1].value if input_size isNone: raise ValueError("Could not infer input size from inputs.get_shape()[-1]")
# i = input_gate, j = new_input, f = forget_gate, o = output_gate lstm_matrix = math_ops.matmul( array_ops.concat([inputs, m_prev], 1), self._kernel) lstm_matrix = nn_ops.bias_add(lstm_matrix, self._bias)
i, j, f, o = array_ops.split( value=lstm_matrix, num_or_size_splits=4, axis=1) # Diagonal connections if self._use_peepholes: c = (sigmoid(f + self._forget_bias + self._w_f_diag * c_prev) * c_prev + sigmoid(i + self._w_i_diag * c_prev) * self._activation(j)) else: c = (sigmoid(f + self._forget_bias) * c_prev + sigmoid(i) * self._activation(j))
if self._cell_clip isnotNone: # pylint: disable=invalid-unary-operand-type c = clip_ops.clip_by_value(c, -self._cell_clip, self._cell_clip) # pylint: enable=invalid-unary-operand-type if self._use_peepholes: m = sigmoid(o + self._w_o_diag * c) * self._activation(c) else: m = sigmoid(o) * self._activation(c)
if self._num_proj isnotNone: m = math_ops.matmul(m, self._proj_kernel)
if self._proj_clip isnotNone: # pylint: disable=invalid-unary-operand-type m = clip_ops.clip_by_value(m, -self._proj_clip, self._proj_clip) # pylint: enable=invalid-unary-operand-type
new_state = (LSTMStateTuple(c, m) if self._state_is_tuple else array_ops.concat([c, m], 1)) return m, new_state
def_enumerated_map_structure_up_to(shallow_structure, map_fn, *args, **kwargs): ix = [0] defenumerated_fn(*inner_args, **inner_kwargs): r = map_fn(ix[0], *inner_args, **inner_kwargs) ix[0] += 1 return r return nest.map_structure_up_to(shallow_structure, enumerated_fn, *args, **kwargs)
def_default_dropout_state_filter_visitor(substate): if isinstance(substate, LSTMStateTuple): # Do not perform dropout on the memory state. return LSTMStateTuple(c=False, h=True) elif isinstance(substate, tensor_array_ops.TensorArray): returnFalse returnTrue
与 BasicLSTMCell 区别 The class uses optional peep-hole connections, optional cell clipping, and an optional projection layer.
if self._use_peepholes: m = sigmoid(o + self._w_o_diag * c) * self._activation(c) else: m = sigmoid(o) * self._activation(c)
class MultiRNNCell(RNNCell)
1 2 3 4 5 6 7 8
@tf_export(v1=["nn.rnn_cell.MultiRNNCell"]) classMultiRNNCell(RNNCell): """RNN cell composed sequentially of multiple simple cells. Example: ```python num_units = [128, 64] cells = [BasicLSTMCell(num_units=n) for n in num_units] stacked_rnn_cell = MultiRNNCell(cells)
"""
@deprecated(None, "This class is equivalent as "
"tf.keras.layers.StackedRNNCells, and will be replaced by "
"that in Tensorflow 2.0.")
def __init__(self, cells, state_is_tuple=True):
"""Create a RNN cell composed sequentially of a number of RNNCells.
Args:
cells: list of RNNCells that will be composed in this order.
state_is_tuple: If True, accepted and returned states are n-tuples, where
`n = len(cells)`. If False, the states are all
concatenated along the column axis. This latter behavior will soon be
deprecated.
Raises:
ValueError: if cells is empty (not allowed), or at least one of the cells
returns a state tuple but the flag `state_is_tuple` is `False`.
"""
super(MultiRNNCell, self).__init__()
if not cells:
raise ValueError("Must specify at least one cell for MultiRNNCell.")
if not nest.is_sequence(cells):
raise TypeError(
"cells must be a list or tuple, but saw: %s." % cells)
if len(set([id(cell) for cell in cells])) < len(cells):
logging.log_first_n(logging.WARN,
"At least two cells provided to MultiRNNCell "
"are the same object and will share weights.", 1)
self._cells = cells
for cell_number, cell in enumerate(self._cells):
# Add Checkpointable dependencies on these cells so their variables get
# saved with this object when using object-based saving.
if isinstance(cell, checkpointable.CheckpointableBase):
# TODO(allenl): Track down non-Checkpointable callers.
self._track_checkpointable(cell, name="cell-%d" % (cell_number,))
self._state_is_tuple = state_is_tuple
if not state_is_tuple:
if any(nest.is_sequence(c.state_size) for c in self._cells):
raise ValueError("Some cells return tuples of states, but the flag "
"state_is_tuple is not set. State sizes are: %s"
% str([c.state_size for c in self._cells]))
@property
def state_size(self):
if self._state_is_tuple:
return tuple(cell.state_size for cell in self._cells)
else:
return sum(cell.state_size for cell in self._cells)
@property
def output_size(self):
return self._cells[-1].output_size
def zero_state(self, batch_size, dtype):
with ops.name_scope(type(self).__name__ + "ZeroState", values=[batch_size]):
if self._state_is_tuple:
return tuple(cell.zero_state(batch_size, dtype) for cell in self._cells)
else:
# We know here that state_size of each cell is not a tuple and
# presumably does not contain TensorArrays or anything else fancy
return super(MultiRNNCell, self).zero_state(batch_size, dtype)
@property
def trainable_weights(self):
if not self.trainable:
return []
weights = []
for cell in self._cells:
if isinstance(cell, base_layer.Layer):
weights += cell.trainable_weights
return weights
@property
def non_trainable_weights(self):
weights = []
for cell in self._cells:
if isinstance(cell, base_layer.Layer):
weights += cell.non_trainable_weights
if not self.trainable:
trainable_weights = []
for cell in self._cells:
if isinstance(cell, base_layer.Layer):
trainable_weights += cell.trainable_weights
return trainable_weights + weights
return weights
def call(self, inputs, state):
"""Run this multi-layer cell on inputs, starting from state."""
cur_state_pos = 0
cur_inp = inputs
new_states = []
for i, cell in enumerate(self._cells):
with vs.variable_scope("cell_%d" % i):
if self._state_is_tuple:
if not nest.is_sequence(state):
raise ValueError(
"Expected state to be a tuple of length %d, but received: %s" %
(len(self.state_size), state))
cur_state = state[i]
else:
cur_state = array_ops.slice(state, [0, cur_state_pos],
[-1, cell.state_size])
cur_state_pos += cell.state_size
cur_inp, new_state = cell(cur_inp, cur_state)
new_states.append(new_state)
new_states = (tuple(new_states) if self._state_is_tuple else
array_ops.concat(new_states, 1))
return cur_inp, new_states