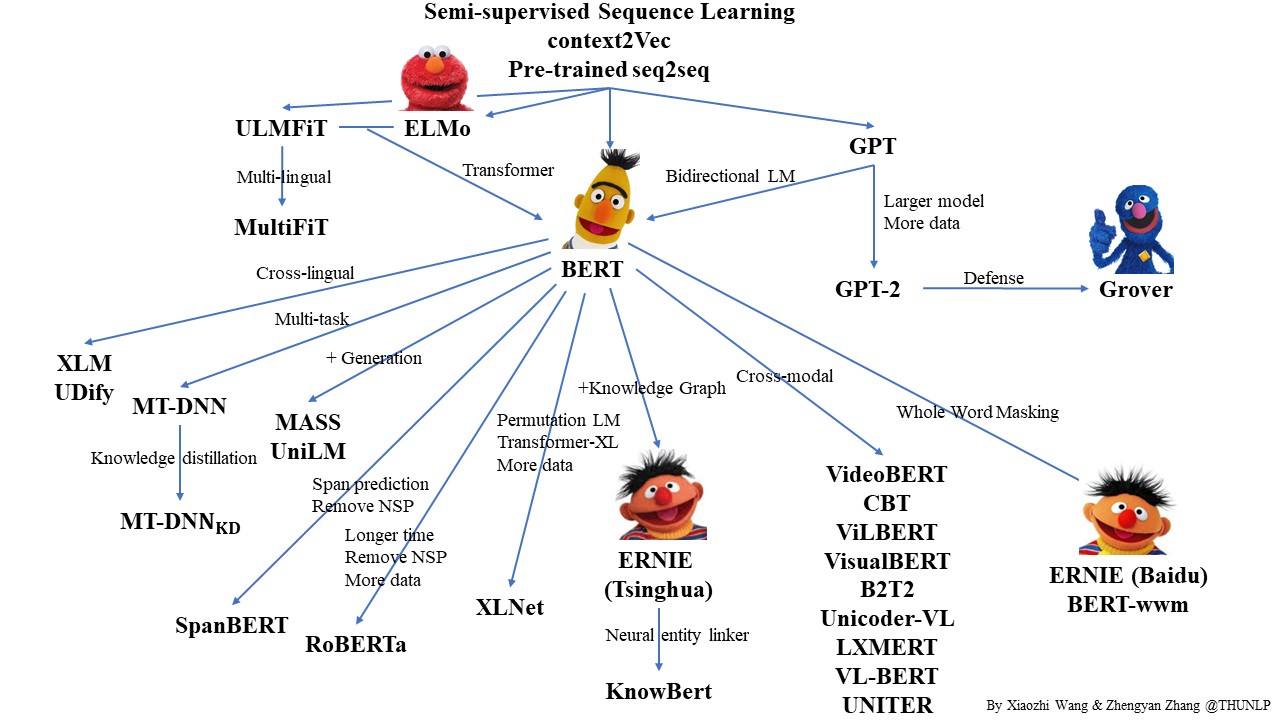
必读语言模型推荐
Github PLMpapers
Must-read Papers on pre-trained language models.
词语嵌入和语言模型基本概念
动手体验词嵌入 http://projector.tensorflow.org/
为什么要使用Word Embedding
在信号处理领域,图像和音频信号的输入往往是表示成高维度、密集的向量形式,在图像和音频的应用系统中,如何对输入信息进行编码(Encoding)显得非常重要和关键,这将直接决定了系统的质量。然而,在自然语言处理领域中,传统的做法是将词表示成离散的符号,例如将 [cat] 表示为 [Id537],而 [dog] 表示为 [Id143]。这样做的缺点在于,没有提供足够的信息来体现词语之间的某种关联,例如尽管cat和dog不是同一个词,但是却应该有着某种的联系(如都是属于动物种类)。由于这种一元表示法(One-hot Representation)使得词向量过于稀疏,所以往往需要大量的语料数据才能训练出一个令人满意的模型。而Word Embedding技术则可以解决上述传统方法带来的问题。
推荐阅读Word2vec的文章 The Illustrated Word2vec
对比表示文本的各种方法
机器学习模型将矢量(数字数组)作为输入。在处理文本时,我们必须做的第一件事就是在将字符串转换为数字之前将字符串转换为数字(或“向量化”文本),然后再将其提供给模型。在本节中,我们将介绍这样做的三种策略。
One-hot encodings
作为第一个想法,我们可能会“One-hot”地编码我们词汇表中的每个单词。考虑句子“The cat sat on the mat”。 这句话中的词汇(或唯一的单词)是(cat,mat,on,sat,the)。为了表示每个单词,我们将创建一个长度等于词汇表的零向量,然后在与该单词对应的索引中设置为一。 此方法如下图所示。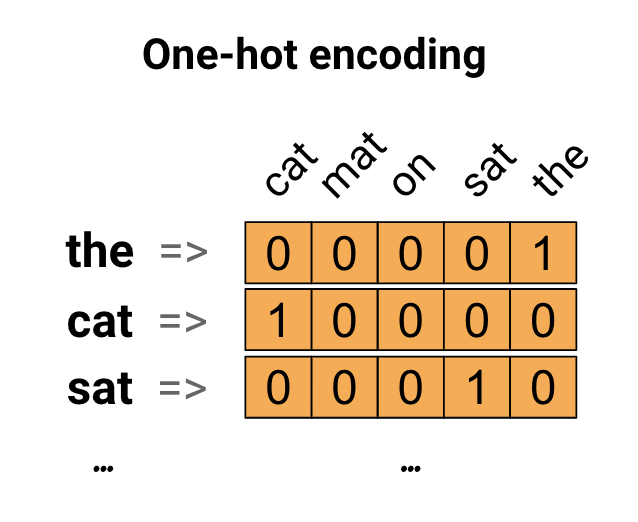
为了创建包含句子编码的向量,我们可以连接每个单词的One-hot向量。
缺点:这种方法效率低下。 One-hot编码矢量是稀疏的(意味着,大多数indicices为零)。想象一下,我们在词汇表中有10,000个单词。为了对每个单词进行One-hot编码,我们将创建一个向量,其中99.99%的元素为零。
使用唯一编号对每个单词进行编码
我们可能尝试的第二种方法是使用唯一编号对每个单词进行编码。继续上面的例子,我们可以将1分配给“cat”,将2分配给“mat”,依此类推。然后我们可以将句子“The cat sat on the mat”编码为像[5,1,4,3,5,2]这样的密集向量。这个应用程序是有效的。我们现在有一个密集的(所有元素都已满),而不是稀疏的向量。
但是,这种方法有两个缺点:
- 整数编码是任意的(它不捕获单词之间的任何关系)。
- 对于要解释的模型,整数编码可能具有挑战性。例如,线性分类器为每个特征学习单个权重。因为任何两个单词的相似性与其编码的相似性之间没有关系,所以这个特征-权重组合没有意义。
Word embeddings 词嵌入
词嵌入为我们提供了一种使用高效,密集表示的方法,其中类似的单词具有相似的编码。 重要的是,我们不必手动指定此编码。 嵌入是浮点值的密集向量(向量的长度是您指定的参数)。它们不是手动指定嵌入的值,而是可训练的参数(在训练期间由模型学习的权重,与模型学习密集层的权重的方式相同)。通常会看到8维(对于小数据集)的单词嵌入,在处理大型数据集时最多可达1024维。 更高维度的嵌入可以捕获单词之间的细粒度关系,但需要更多的数据来学习。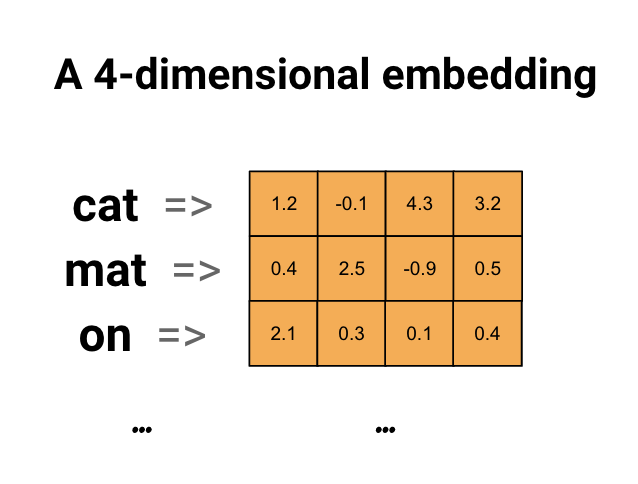
缺点:词嵌入没有上下文的概念,一个词语与一个词嵌入向量一一对应,无法解决一词多义问题。
词嵌入资源
| 标题 | 说明 |
|---|---|
| Tencent AI Lab Embedding Corpus for Chinese Words and Phrases | This corpus provides 200-dimension vector representations, a.k.a. embeddings, for over 8 million Chinese words and phrases, which are pre-trained on large-scale high-quality data. These vectors, capturing semantic meanings for Chinese words and phrases, can be widely applied in many downstream Chinese processing tasks (e.g., named entity recognition and text classification) and in further research.腾讯AI Lab开源大规模高质量中文词向量数据,800万中文词随你用 |
| awesome-embedding-models | 精选的嵌入模型教程,项目和社区的精选列表。 |
向量空间模型
向量空间模型(Vector space models, VSMs)将词语表示为一个连续的词向量,并且语义接近的词语对应的词向量在空间上也是接近的。VSMs在NLP中拥有很长的历史,但是所有的方法在某种程度上都是基于一种分布式假说,该假说的思想是如果两个词的上下文(context)相同,那么这两个词所表达的语义也是一样的;换言之,两个词的语义是否相同或相似,取决于两个词的上下文内容,上下文相同表示两个词是可以等价替换的。
基于分布式假说理论的词向量生成方法主要分两大类:计数法(count-based methods, e.g. Latent Semantic Analysis)和预测法(predictive methods, e.g. neural probabilistic language models)。Baroni等人详细论述了这两种方法的区别,简而言之,计数法是在大型语料中统计词语及邻近的词的共现频率,然后将之为每个词都映射为一个稠密的向量表示;预测法是直接利用词语的邻近词信息来得到预测词的词向量(词向量通常作为模型的训练参数)。
文本问题
机器学习这样的技术比较喜欢被定义好的固定长度的输入和输出,因此不固定输入输出是文本建模的一个问题。
机器学习算法不能直接处理原始文本,文本必须转换成数字。具体来说,是数字的向量。
“在语言处理中,向量x是由文本数据派生而来的,以反映文本的各种语言属性。”在自然语言处理中神经网络方法,2017年。
这被称为特征提取或特征编码。这是一种流行的、简单的文本数据提取方法被称为文本的词汇模型。
词袋模型
词袋模型下,像是句子或是文件这样的文字可以用一个袋子装着这些词的方式表现,这种表现方式不考虑文法以及词的顺序。最近词袋模型也被应用在电脑视觉领域 。
词袋模型被广泛应用在文件分类,词出现的频率可以用来当作训练分类器的特征。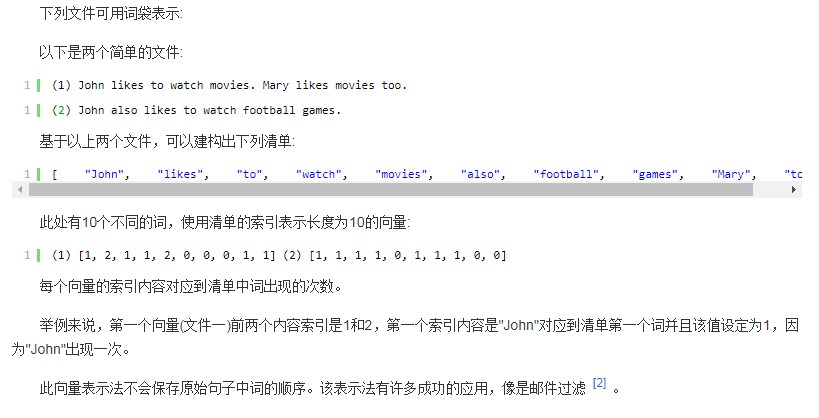
词向量模型
词向量
词向量具有良好的语义特性,是表示词语特征的常用方式。词向量每一维的值代表一个具有一定的语义和语法上解释的特征。所以,可以将词向量的每一维称为一个词语特征。词向量具有多种形式,distributed representation 是其中一种。一个 distributed representation 是一个稠密、低维的实值向量。distributed representation 的每一维表示词语的一个潜在特征,该特 征捕获了有用的句法和语义特性。可见 ,distributed representation 中的 distributed 一词体现了词向量这样一个特点:将词语的不同句法和语义特征分布到它的每一个维度去表示 。
自然语言是一套用来表达含义的复杂系统。在这套系统中,词是表义的基本单元。顾名思义,词向量是用来表示词的向量,也可被认为是词的特征向量。
这通常需要把维数为词典大小的高维空间嵌入到一个更低维数的连续向量空间。把词映射为实数域上向量的技术也叫词嵌入(word embedding)。近年来,词向量已逐渐成为自然语言处理的基础知识。
语言模型旨在为语句的联合概率函数P(w1,…,wT)建模, 其中wi表示句子中的第i个词。语言模型的目标是,希望模型对有意义的句子赋予大概率,对没意义的句子赋予小概率。 这样的模型可以应用于很多领域,如机器翻译、语音识别、信息检索、词性标注、手写识别等,它们都希望能得到一个连续序列的概率。
统计语言模型

基于神经网络的分布表示
由于神经网络较为灵活,这类方法的最大优势在于可以表示复杂的上下文。更主要的原因是NNLM不再去老老实实地统计词频,而是通过模型拟合的方式逼近真实分布。在前面基于矩阵的分布表示方法中,最常用的上下文是词。如果使用包含词序信息的 n-gram 作为上下文,当 n 增加时,n-gram 的总数会呈指数级增长,此时会遇到维数灾难问题。而神经网络在表示 n-gram 时,可以通过一些组合方式对 n 个词进行组合,参数个数仅以线性速度增长。有了这一优势,神经网络模型可以对更复杂的上下文进行建模,在词向量中包含更丰富的语义信息。
基于NN的所有训练方法都是在训练语言模型(LM)的同时,顺便得到词向量的。
Neural net language models
word2vector
| 标题 | 说明 | 附加 |
|---|---|---|
| Efficient Estimation of Word Representations in Vector Space | word2vector 原文 | 20130116 |
| models/tutorials/embedding/word2vec.py | 官方实现 | 20171030 |
传统词嵌入的过程embedding_lookup()
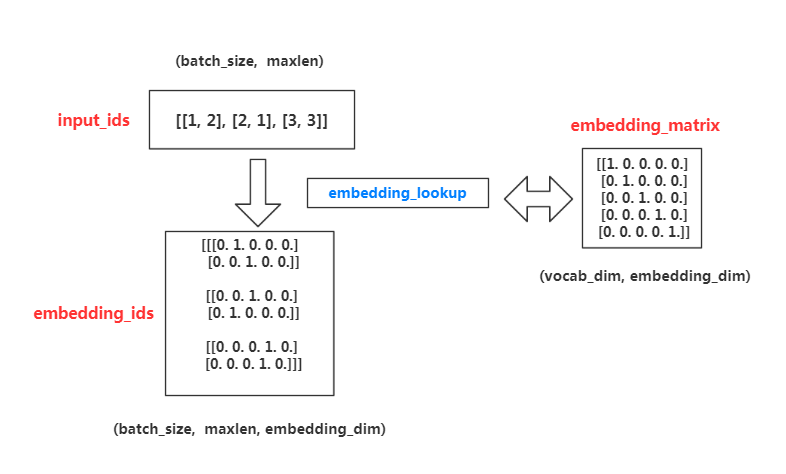
词嵌入的过程,注意其中的维度变化只是一种可能的方式。
1 | import tensorflow as tf |
代码中先使用palceholder定义了一个未知变量input_ids用于存储索引,和一个已知变量embedding,是一个5*5的对角矩阵。运行结果为,1
2
3
4
5
6
7
8
9
10
11
12embedding = [[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
input_embedding = [[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[1. 0. 0. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 1. 0. 0.]
[0. 1. 0. 0. 0.]]
简单的讲就是根据input_ids中的id,寻找embedding中的对应元素。比如,input_ids=[1,3,5],则找出embedding中下标为1,3,5的向量组成一个矩阵返回。
如果将input_ids改写成下面的格式:
1 | import tensorflow as tf |
输出结果就会变成如下的格式:1
2
3
4
5
6input_embedding = [[[0 1 0 0 0]
[0 0 1 0 0]]
[[0 0 1 0 0]
[0 1 0 0 0]]
[[0 0 0 1 0]
[0 0 0 1 0]]]
对比上下两个结果不难发现,相当于在np.array中直接采用下标数组获取数据。需要注意的细节是返回的tensor的dtype和传入的被查询的tensor的dtype保持一致;和ids的dtype无关。
字符嵌入
在NLP中,我们通常使用的过滤器会滑过整个矩阵(单词)。因此,过滤器的“宽度(width)”通常与输入矩阵的宽度相同。高度,或区域大小(region size),可能会有所不同,但是滑动窗口一次在2-5个字是典型的。
一个NLP上的卷积实例是下面这样: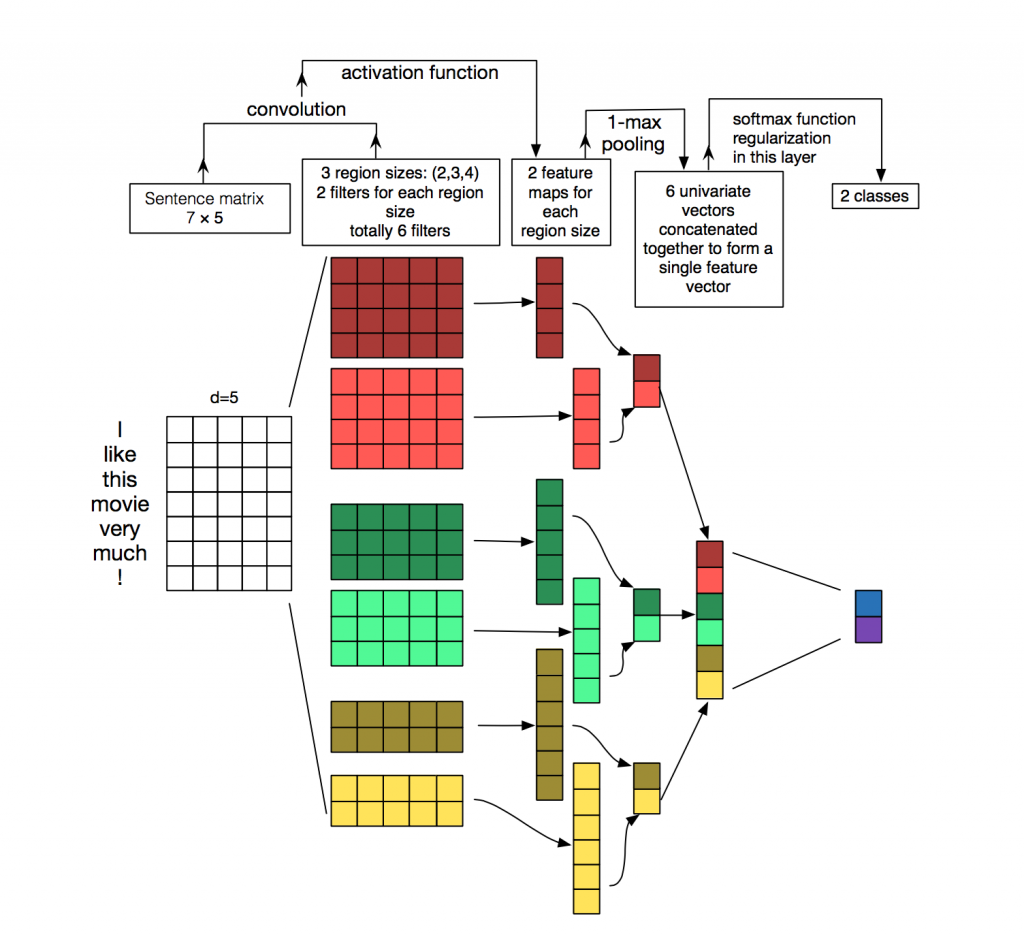
上图展示了CNN在文本分类的使用,使用了2种过滤器(卷积核),每个过滤器有3种高度(区域大小),即有6种卷积结构(左起第2列),所以会产生6中卷积后的结果(左起第3列),经过最大池化层(后面还会提到池化层),每个卷积的结果将变为1个值(左起第4列),最终生成一个向量(左起第5列),最终经过分类器得到一个二分类结果(最后一列)。来自:A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification。
对比Word2vec, Fasttext, Glove, Elmo, Bert, Flair pre-train Word Embedding
Word2vec, Fasttext, Glove, Elmo, Bert, Flair pre-train Word Embedding
词嵌入-2018历史综述 Bornstein
Beyond Word Embeddings Part 1
Beyond Word Embeddings Part 2
Beyond Word Embeddings Part 3
Beyond Word Embeddings Part 4
语言模型词嵌入的过程
| 标题 | 说明 | 附加 |
|---|---|---|
| 词向量技术-从word2vec到ELMo | 20180724 | |
| NLP领域的ImageNet时代到来:词嵌入「已死」,语言模型当立 | 翻译自 NLP’s ImageNet moment has arrived | 20180709 |
| 2018最好的词句嵌入技术概览:从无监督学习到监督、多任务学习 | 翻译自 The Current Best of Universal Word Embeddings and Sentence Embeddings | 20180606 |
| NLP的游戏规则从此改写?从word2vec, ELMo到BERT | 夕小瑶 详细解读 | |
| 神经语言模型的最新进展 | 卡内基梅隆大学博士杨植麟受邀至清华大学计算机系进行主题为「神经语言模型的最新进展」的演讲。 | 20181213 |
| 从word2vec开始,说下GPT庞大的家族系谱 | 本文从从老祖级别的 word2vec 开始,从头到尾梳理了 GPT 的 「家谱」 和 word2vec 领衔的庞大的 NLP「家族集团」。 | 20201004 |
自然语言处理中的语言模型预训练方法
语言模型评价
语言模型构造完成后,如何确定好坏呢? 目前主要有两种评价方法:
实用方法:通过查看该模型在实际应用(如拼写检查、机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观;
理论方法:迷惑度/困惑度/混乱度(preplexity),其基本思想是给测试集的句子赋予较高概率值的语言模型较好,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好。
深度长文:NLP的巨人肩膀(上)
纵览2003-2018年自然语言处理中词语表示的发展史。
本质上,自然语言理解 NLU 的核心问题其实就是如何从语言文字的表象符号中抽取出来蕴含在文字背后的真实意义,并将其用计算机能够读懂的方式表征出来。当然这通常对应的是数学语言,表征是如此重要,以至于 2012 年的时候 Yoshua Bengio 作为第一作者发表了一篇表征学习的综述 Representation Learning: A Review and New Perspectives,并随后在 2013 年和深度学习三大巨头的另一位巨头 Yann LeCun 牵头创办 ICLR,这一会议至今才过去 5 年时间,如今已是 AI 领域最负盛名的顶级会议之一。可以说,探究 NLP 或 NLU 的历史,同样也是探究文本如何更有效表征的历史。
1954 年 Harris 提出分布假说(distributional hypothesis),这一假说认为:上下文相似的词,其语义也相似,1957 年 Firth 对分布假说进行了进一步阐述和明确:词的语义由其上下文决定(a word is characterized by the company it keeps),30 年后,深度学习 Hinton 也于 1986 年尝试过词的分布式表示。
| 时间 | 词语表示的特征 | 论文 | 解析 |
|---|---|---|---|
| -2003 | 没有统一表示词语的方法,一般采取统计分析模式 | NLP 中并没有一个统一的方法去表示一段文本,各位前辈和大师们发明了许多的方法:从 one-hot 表示一个词到用 bag-of-words 来表示一段文本,从 k-shingles 把一段文本切分成一些文字片段,到汉语中用各种序列标注方法将文本按语义进行分割,从 tf-idf 中用频率的手段来表征词语的重要性,到 text-rank 中借鉴 page-rank 的方法来表征词语的权重,从基于 SVD 纯数学分解词文档矩阵的 LSA,到 pLSA 中用概率手段来表征文档形成过程并将词文档矩阵的求解结果赋予概率含义,再到 LDA 中引入两个共轭分布从而完美引入先验…… | |
| 2003 | 词语的分布式表示 | A Neural Probabilistic Language Model | Bengio 在他的经典论文 A Neural Probabilistic Language Model 中,首次将深度学习的思想融入到语言模型中,并发现将训练得到的 NNLM(Neural Net Language Model,神经网络语言模型)模型的第一层参数当做词的分布式表征时,能够很好地获取词语之间的相似度。NNLM 的最主要贡献是非常有创见性地将模型的第一层特征映射矩阵当做词的分布式表示,从而可以将一个词表征为一个向量形式,这直接启发了后来的 word2vec 的工作。 |
| 2007 | 2007 年 Mnih 和 Hinton 提出的 LBL 以及后续的一系列相关模型,省去了 NNLM 中的激活函数,直接把模型变成了一个线性变换,尤其是后来将 Hierarchical Softmax 引入到 LBL 后,训练效率进一步增强,但是表达能力不如 NNLM 这种神经网络的结构。 | ||
| 2008 | 2008 年 Collobert 和 Weston 提出的 C&W 模型不再利用语言模型的结构,而是将目标文本片段整体当做输入,然后预测这个片段是真实文本的概率,所以它的工作主要是改变了目标输出。由于输出只是一个概率大小,不再是词典大小,因此训练效率大大提升,但由于使用了这种比较“别致”的目标输出,使得它的词向量表征能力有限。 | ||
| 2010 | 2010 年 Mikolov 提出的 RNNLM 主要是为了解决长程依赖关系,时间复杂度问题依然存在。 | ||
| 2013 | word2vec;CBOW 模型;Skip-gram 模型 | Efficient estimation of word representations in vector space;Distributed Representations of Words and Phrases and their Compositionality | 其实 word2vec 只是一个工具,背后的模型是 CBOW 或者 Skip-gram,并且使用了 Hierarchical Softmax 或 Negative Sampling 这些训练的优化方法。word2vec 对于前人的优化,主要是两方面的工作:模型的简化和训练技巧的优化。word2vec 的出现,极大促进了 NLP 的发展,尤其是促进了深度学习在 NLP 中的应用(不过有意思的是,word2vec 算法本身其实并不是一个深度模型,它只有两层全连接),利用预训练好的词向量来初始化网络结构的第一层几乎已经成了标配,尤其是在只有少量监督数据的情况下,如果不拿预训练的 embedding 初始化第一层,几乎可以被认为是在蛮干。 |
| 2014 | Glove | GloVe: Global Vectors for Word Representation | 它整个的算法框架都是基于矩阵分解的做法来获取词向量的,本质上和诸如 LSA 这种基于 SVD 的矩阵分解方法没有什么不同,只不过 SVD 分解太过于耗时,运算量巨大,相同点是 LSA 也是输入共现矩阵,不过一般主要以词-文档共现矩阵为主,另外,LSA 中的共现矩阵没有做特殊处理,而 GloVe 考虑到了对距离较远的词对做相应的惩罚等等。然而,相比 word2vec,GloVe 却更加充分的利用了词的共现信息,word2vec 中则是直接粗暴的让两个向量的点乘相比其他词的点乘最大,至少在表面上看来似乎是没有用到词的共现信息,不像 GloVe 这里明确的就是拟合词对的共现频率。 |
| 2015 | Skip-shoughts | Skip-Thought Vectors | 2015 年,多伦多大学的 Kiros 等人提出了一个很有意思的方法叫 Skip-thoughts。同样也是借鉴了 Skip-gram 的思想,但是和 PV-DBOW 中利用文档来预测词的做法不一样的是,Skip-thoughts 直接在句子间进行预测,也就是将 Skip-gram 中以词为基本单位,替换成了以句子为基本单位,具体做法就是选定一个窗口,遍历其中的句子,然后分别利用当前句子去预测和输出它的上一句和下一句。对于句子的建模利用的 RNN 的 sequence 结构,预测上一个和下一个句子时候,也是利用的一个 sequence 的 RNN 来生成句子中的每一个词,所以这个结构本质上就是一个 Encoder-Decoder 框架,只不过和普通框架不一样的是,Skip-thoughts 有两个 Decoder。 |
| 2016 | fasttext | FastText.zip: Compressing text classification models | word2vec 和 GloVe 都不需要人工标记的监督数据,只需要语言内部存在的监督信号即可以完成训练。而与此相对应的,fastText 则是利用带有监督标记的文本分类数据完成训练。在输入数据上,CBOW 输入的是一段区间中除去目标词之外的所有其他词的向量加和或平均,而 fastText 为了利用更多的语序信息,将 bag-of-words 变成了 bag-of-features,也就是下图中的输入 x 不再仅仅是一个词,还可以加上 bigram 或者是 trigram 的信息等等。第二个不同在于,CBOW 预测目标是语境中的一个词,而 fastText 预测目标是当前这段输入文本的类别。fastText 最大的特点在于快。 |
| 2017 | InferSent 框架 | Supervised Learning of Universal Sentence Representations from Natural Language Inference Data | 除了 Skip-thoughts 和 Quick-thoughts 这两种不需要人工标记数据的模型之外,还有一些从监督数据中学习句子表示的方法。比如 2017 年 Facebook 的研究人员 Conneau 等人提出的 InferSent 框架,它的思想特别简单,先设计一个模型在斯坦福的 SNLI(Stanford Natural Language Inference)数据集上训练,而后将训练好的模型当做特征提取器,以此来获得一个句子的向量表示,再将这个句子的表示应用在新的分类任务上,来评估句子向量的优劣。 |
| 2018_2 | ELMo | Deep contextualized word representations | 该研究提出了一种新型深度语境化词表征,可对词使用的复杂特征(如句法和语义)和词使用在语言语境中的变化进行建模(即对多义词进行建模)。这些表征可以轻松添加至已有模型,并在 6 个 NLP 问题中显著提高当前最优性能。 |
| 2018_3 | Quick thoughts | An efficient framework for learning sentence representations | 2018 年的时候,在 Skip-thoughts 的基础上,Google Brain 的 Logeswaran 等人将这一思想做了进一步改进,他们认为 Skip-thoughts 的 Decoder 效率太低,且无法在大规模语料上很好的训练(这是 RNN 结构的通病)。所以他们把 Skip-thoughts 的生成任务改进成为了一个分类任务,具体说来就是把同一个上下文窗口中的句子对标记为正例,把不是出现在同一个上下文窗口中的句子对标记为负例,并将这些句子对输入模型,让模型判断这些句子对是否是同一个上下文窗口中,很明显,这是一个分类任务。可以说,仅仅几个月之后的 BERT 正是利用的这种思路。而这些方法都和 Skip-thoughts 一脉相承。 |
| 2018_3 | Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning | 提出了利用四种不同的监督任务来联合学习句子的表征,这四种任务分别是:Natural Language Inference,Skip-thougts,Neural Machine Translation 以及 Constituency Parsing 等。 | |
| 2018_3 | Universal Sentence Encoder | 谷歌的 Daniel Cer 等人在论文 Universal Sentence Encoder 中提出的思路基本和 General Purpose Sentence Representation 的工作一样,只不过作者提出了利用 Transformer 和 DAN(上文提到过的和 CBOW 与 fastText 都神似的 Deep Unordered Composition Rivals Syntactic Methods for Text Classification)两种框架作为句子的 Encoder。 | |
| 2018_6 | openai-GPT | Improving Language Understanding by Generative Pre-Training | OpenAI 最近通过一个与任务无关的可扩展系统在一系列语言任务中获得了当前最优的性能,目前他们已经发布了该系统。OpenAI 表示他们的方法主要结合了两个已存的研究,即 Transformer 和无监督预训练。实验结果提供了非常令人信服的证据,其表明联合监督学习方法和无监督预训练能够得到非常好的性能。这其实是很多研究者过去探索过的领域,OpenAI 也希望他们这次的实验结果能激发更加深入的研究,并在更大和更多的数据集上测试联合监督学习与无监督预训练的性能。 |
| 2018_10 | Google-BERT | BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | 论文介绍了一种新的语言表征模型 BERT,意为来自 Transformer 的双向编码器表征(Bidirectional Encoder Representations from Transformers)。与最近的语言表征模型(Peters et al., 2018; Radford et al., 2018)不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的 BERT 表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推断任务)创建当前最优模型,无需对任务特定架构做出大量修改。BERT 的概念很简单,但实验效果很强大。它刷新了 11 个 NLP 任务的当前最优结果,包括将 GLUE 基准提升至 80.4%(7.6% 的绝对改进)、将 MultiNLI 的准确率提高到 86.7%(5.6% 的绝对改进),以及将 SQuAD v1.1 的问答测试 F1 得分提高至 93.2 分(提高 1.5 分)——比人类表现还高出 2 分。 |
NLP 的巨人肩膀(下):从 CoVe 到 BERT
可视化分析词嵌入
| 标题 | 说明 | 时间 |
|---|---|---|
| 用scikit-learn学习主成分分析(PCA) | 降维基础 | |
| sklearn中PCA的使用方法 | 降维基础 | 20180131 |
| visualizing-elmo-contextual-vectors | 可视化ELMo上下文向量 | 20190417 |

