Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的机制(Mechanism),一般称为Attention Mechanism。Attention Mechanism目前非常流行,广泛应用于机器翻译、语音识别、图像标注(Image Caption)等很多领域,之所以它这么受欢迎,是因为Attention给模型赋予了区分辨别的能力,例如,在机器翻译、语音识别应用中,为句子中的每个词赋予不同的权重,使神经网络模型的学习变得更加灵活(soft),同时Attention本身可以做为一种对齐关系,解释翻译输入/输出句子之间的对齐关系,解释模型到底学到了什么知识,为我们打开深度学习的黑箱,提供了一个窗口。
注意,随着研究的深入,注意力的概念已经发生了变化,上述内容只是注意力中的一种而已。
Attention机制中的打分函数

相关资源
| 标题 | 说明 | 时间 |
|---|---|---|
| 注意力的动画解析(以机器翻译为例) | 原文Attn: Illustrated Attention | 20190208 |
| 模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用 | 首推 知乎 | 2017 |
| 目前主流的attention方法都有哪些? | attention机制详解 知乎 | 2017 |
| Neural Machine Translation (seq2seq) Tutorial | GitHub 以机器翻译为例讲解注意力机制 | 长期更新 |
| Attention_Network_With_Keras 注意力模型的代码的实现与分析 | 代码解析 简书 | 20180617 |
| Attention_Network_With_Keras | 代码实现 GitHub | 2018 |
| 各种注意力机制窥探深度学习在NLP中的神威 | 综述 机器之心 | 20181008 |
| Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures | 为什么使用自注意力机制? 实验结果证明:1)自注意力网络和 CNN 在建模长距离主谓一致时性能并不优于 RNN;2)自注意力网络在词义消歧方面显著优于 RNN 和 CNN。 | 20180827 |
| 各种注意力总结 | 本文主要是总结:注意力机制、注意力机制的变体、论文中常见的注意力 | 20180325 |
注意力机制分类
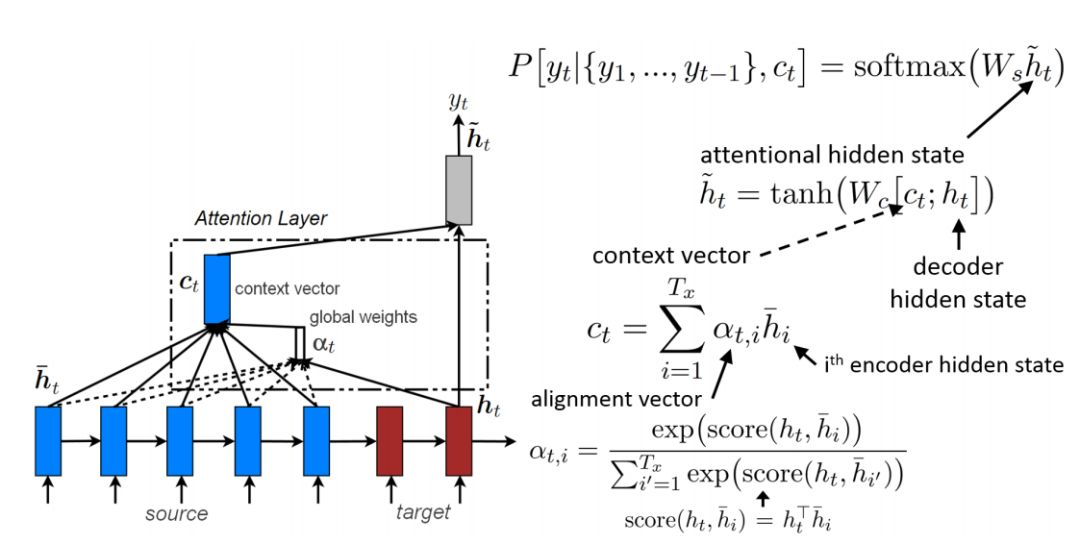
全局注意力机制
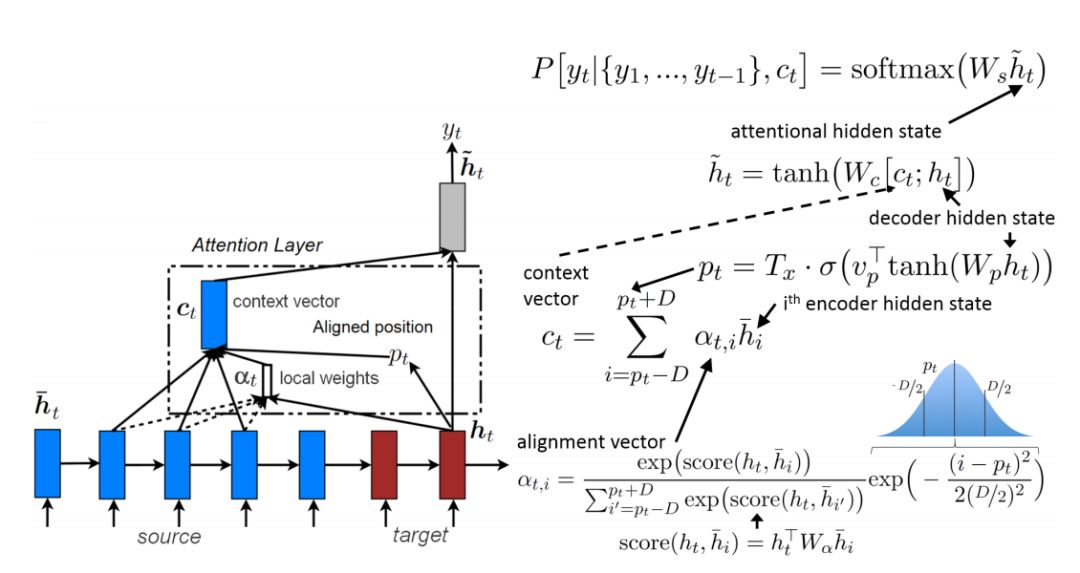
局部注意力机制
自注意力机制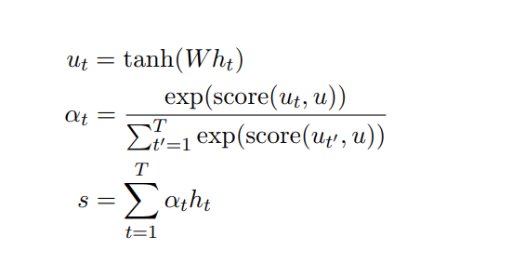
隐藏向量 $h_t$ 首先会传递到全连接层。然后校准系数 $a_t$ 会对比全连接层的输出 $u_t$ 和可训练上下文向量 u(随机初始化),并通过 Softmax 归一化而得出。注意力向量 s 最后可以为所有隐藏向量的加权和。上下文向量可以解释为在平均上表征的最优单词。但模型面临新的样本时,它会使用这一知识以决定哪一个词需要更加注意。在训练中,模型会通过反向传播更新上下文向量,即它会调整内部表征以确定最优词是什么。
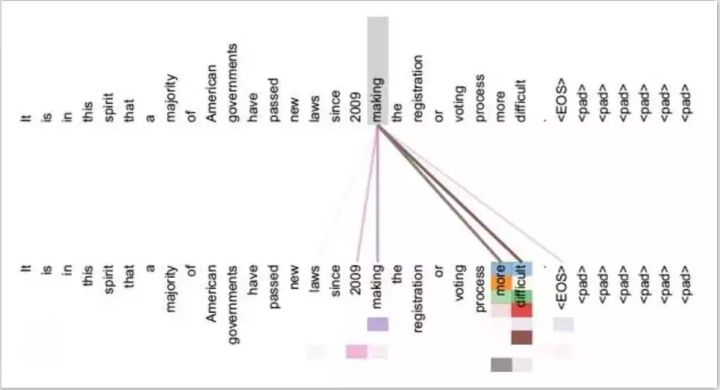
Self Attention与传统的Attention机制非常的不同:传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端的每个词与目标端每个词之间的依赖关系。但Self Attention不同,它分别在source端和target端进行,仅与source input或者target input自身相关的Self Attention,捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self Attention加入到target端得到的Attention中,捕捉source端和target端词与词之间的依赖关系。因此,self Attention Attention比传统的Attention mechanism效果要好,主要原因之一是,传统的Attention机制忽略了源端或目标端句子中词与词之间的依赖关系,相对比,self Attention可以不仅可以得到源端与目标端词与词之间的依赖关系,同时还可以有效获取源端或目标端自身词与词之间的依赖关系
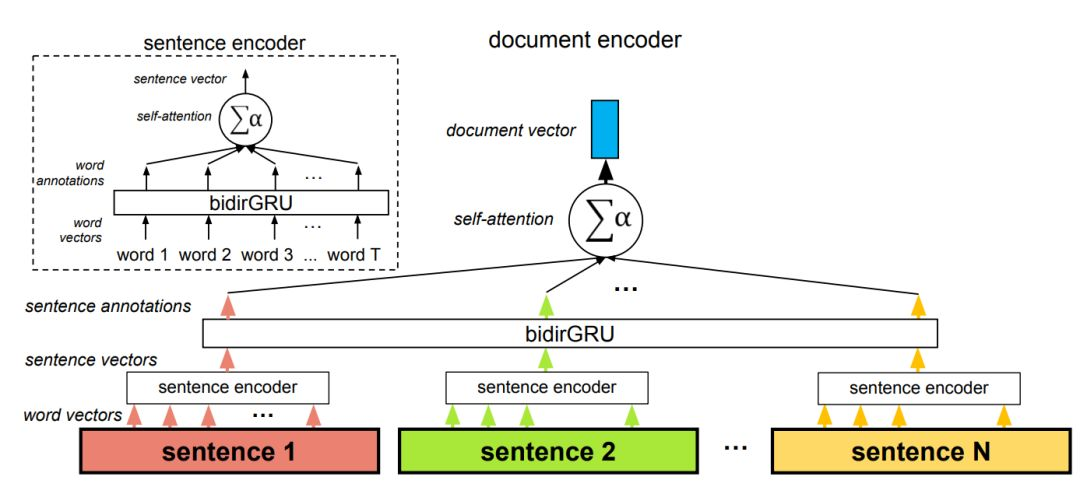
层级注意力机制
在该架构中,自注意力机制共使用了两次:在词层面与在句子层面。该方法因为两个原因而非常重要,首先是它匹配文档的自然层级结构(词——句子——文档)。其次在计算文档编码的过程中,它允许模型首先确定哪些单词在句子中是非常重要的,然后再确定哪个句子在文档中是非常重要的。
相关论文
以2014《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》抛砖引玉
要介绍Attention Mechanism结构和原理,首先需要介绍下Seq2Seq模型的结构。基于RNN的Seq2Seq模型主要由两篇论文介绍,只是采用了不同的RNN模型。Ilya Sutskever等人与2014年在论文《Sequence to Sequence Learning with Neural Networks》中使用LSTM来搭建Seq2Seq模型。随后,2015年,Kyunghyun Cho等人在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》提出了基于GRU的Seq2Seq模型。两篇文章所提出的Seq2Seq模型,想要解决的主要问题是,如何把机器翻译中,变长的输入X映射到一个变长输出Y的问题,其主要结构如图所示。
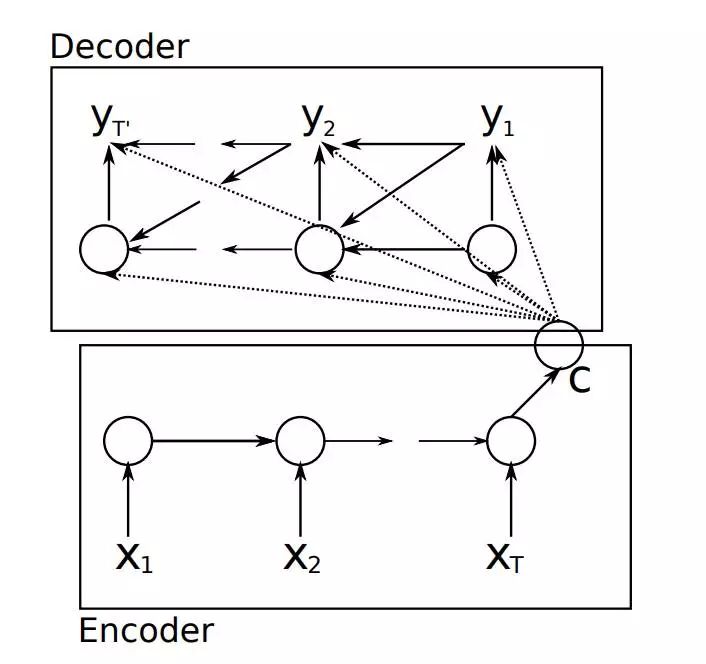
传统的Seq2Seq结构
其中,Encoder把一个变成的输入序列x1,x2,x3….xt编码成一个固定长度隐向量(背景向量,或上下文向量context)c,c有两个作用:1、做为初始向量初始化Decoder的模型,做为decoder模型预测y1的初始向量。2、做为背景向量,指导y序列中每一个step的y的产出。Decoder主要基于背景向量c和上一步的输出yt-1解码得到该时刻t的输出yt,直到碰到结束标志($
如上文所述,传统的Seq2Seq模型对输入序列X缺乏区分度,因此,2015年,Kyunghyun Cho等人在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中,引入了Attention Mechanism来解决这个问题,他们提出的模型结构如图所示。
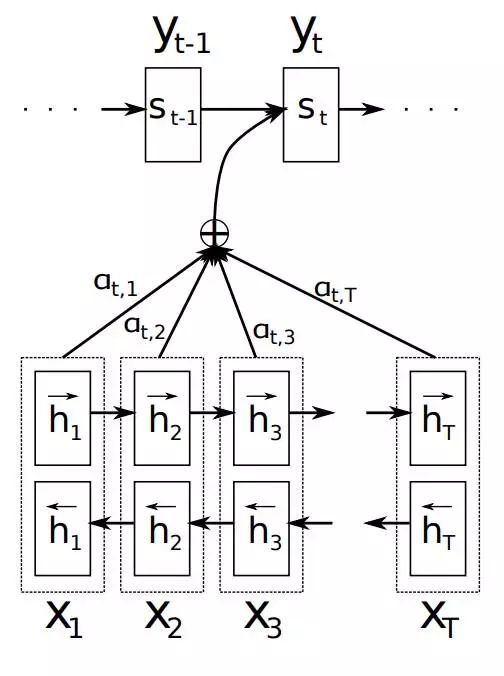
Attention Mechanism模块图解


- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Effective Approaches to Attention-based Neural Machine Translation 中英文对照翻译
可视化神经机器翻译模型
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)

