信息抽取引言
2017-2018 基于神经网络的实体识别和关系抽取联合学习
本文关注的任务是从无结构的文本中抽取实体以及实体之间的关系(实体1-关系-实体2,三元组),这里的关系是我们预定义好的关系类型。例如下图,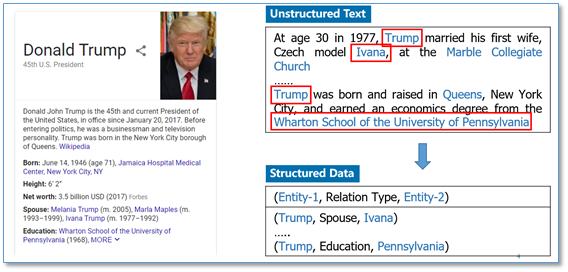
Multiple relations extraction among multiple entities in unstructured text
To the best of our knowledge, our proposed model is the first one to extract multiple relations among multiple entities.
Relations extraction is a widely researched topic in nature language processing. However, most of the work in the literature concentrate on the methods that are dealing with single relation between two named entities. In the task of multiple relations extraction, traditional statistic-based methods have difficulties in selecting features and improving the performance of extraction model. In this paper, we presented formal definitions of multiple entities and multiple relations and put forward three labeling methods which were used to label entity categories, relation categories and relation conditions. We also proposed a novel relation extraction model which is based on dynamic long short-term memory network. To train our model, entity feature, entity position feature and part of speech feature are used together. These features are used to describe complex relations and improve the performance of relation extraction model. In the experiments, we classified the corpus into three sets which are composed of 0–20 words, 20–35 words and 35+ words sentences. On conll04.corp, the final precision, recall rate and F-measure reached 72.9, 70.8 and 67.9% respectively.
关系提取是自然语言处理中广泛研究的主题。但是,文献中的大多数工作都集中在处理两个命名实体之间单一关系的方法上。在多关系提取的任务中,传统的基于统计的方法在选择特征和提高提取模型的性能方面存在困难。在本文中,我们提出了多个实体和多个关系的正式定义,并提出了三种标记方法,用于标记实体类别,关系类别和关系条件。我们还提出了一种基于动态长短期记忆网络的新型关系提取模型。为了训练我们的模型,实体特征,实体位置特征和词性特征一起使用。这些特征用于描述复杂关系并改善关系提取模型的性能。在实验中,我们将语料库分为三组,由0-20个单词,20-35个单词和35个单词组成。在conll04.corp上,最终的精确度,召回率和F-指数分别达到72.9%,70.8%和67.9%。
Joint entity recognition and relation extraction as a multi-head selection problem
Abstract
State-of-the-art models for joint entity recognition and relation extraction strongly rely on external natural language processing (NLP) tools such as POS (part-of-speech) taggers and dependency parsers. Thus, the performance of such joint models depends on the quality of the features obtained from these NLP tools. However, these features are not always accurate for various languages and contexts. In this paper, we propose a joint neural model which performs entity recognition and relation extraction simultaneously, without the need of any manually extracted features or the use of any external tool. Specifically, we model the entity recognition task using a CRF (Conditional Random Fields) layer and the relation extraction task as a multi-head selection problem (i.e., potentially identify multiple relations for each entity). We present an extensive experimental setup, to demonstrate the effectiveness of our method using datasets from various contexts (i.e., news, biomedical, real estate) and languages (i.e., English, Dutch). Our model outperforms the previous neural models that use automatically extracted features, while it performs within a reasonable margin of feature-based neural models, or even beats them.
摘要
用于联合实体识别和关系提取的最先进模型强烈依赖于外部自然语言处理(NLP)工具,例如POS(词性)标记器和依赖性解析器。因此,这种联合模型的性能取决于从这些NLP工具获得的特征的质量。但是,对于各种语言和上下文,这些功能并不总是准确的。在本文中,我们提出了一个联合神经模型,它同时执行实体识别和关系提取,无需任何手动提取的功能或使用任何外部工具。具体地,我们使用CRF(条件随机场)层和关系提取任务将实体识别任务建模为多头选择问题(即,潜在地识别每个实体的多个关系)。我们提出了一个广泛的实验设置,以证明我们的方法使用来自各种环境(即新闻,生物医学,房地产)和语言(即英语,荷兰语)的数据集的有效性。我们的模型优于以前使用自动提取特征的神经模型,同时它在基于特征的神经模型的合理范围内执行,甚至胜过它们。

| 标题 | 说明 | 时间 |
|---|---|---|
| Joint entity recognition and relation extraction as a multi-head selection problem | 论文原文 | 2018 |
| multihead_joint_entity_relation_extraction | 论文实现 | 20190429 |
| 对抗训练多头选择的实体识别和关系抽取的联合模型 | 论文解析 | 20181005 |
Adversarial training for multi-context joint entity and relation extraction
本文是 Joint entity recognition and relation extraction as a multi-head selection problem 的姊妹篇,都是同一个多头选择实体关系抽取模型,只是增加了对抗训练这个神经网络正则化方法。
Abstract
Adversarial training (AT) is a regularization method that can be used to improve the robustness of neural network methods by adding small perturbations in the training data. We show how to use AT for the tasks of entity recognition and relation extraction. In particular, we demonstrate that applying AT to a general purpose baseline model for jointly extracting entities and relations, allows improving the state-of-the-art effectiveness on several datasets in different contexts (i.e., news, biomedical, and real estate data) and for different languages (English and Dutch).
摘要
对抗训练(AT)是一种正则化方法,可以通过在训练数据中添加小扰动来提高神经网络方法的鲁棒性。 我们展示了如何将AT用于实体识别和关系提取的任务。 特别是,我们证明将AT应用于通用基线模型以联合提取实体和关系,可以改善不同环境中几个数据集(即新闻,生物医学和房地产数据)的最新效果。 和不同的语言(英语和荷兰语)。
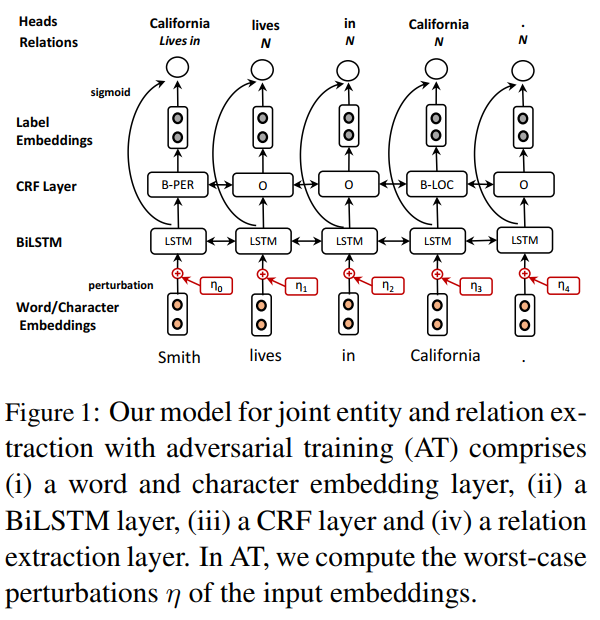
3.2 Adversarial traing (AT)
We exploit the idea of AT (Goodfellow et al., 2015) as a regularization method to make our model robust to input perturbations. Specifically, we generate examples which are variations of the original ones by adding some noise at the level of the concatenated word representation (Miyato et al., 2017). This is similar to the concept introduced by Goodfellow et al. (2015) to improve the robustness of image recognition classifiers. We generate an adversarial example by adding the worst-case perturbation $\eta_{adv}$ to the original embedding w that maximizes the loss function:
where $\hat\theta$ is a copy of the current model parameters. Since Eq. (2) is intractable in neural networks, we use the approximation proposed in Goodfellow et al. (2015) defined as: $\eta_{adv}=\epsilon g/\Vert g \Vert$, with $g=\nabla_wLoss(w;\hat\theta)$, where $\epsilon$ is a small bounded norm treated as a hyperparameter. Similar to Yasunaga et al. (2018), we set $\epsilon$ to be $\alpha\sqrt{D}$ (where $D$ is the dimension of the embeddings). We train on the mixture of original and adversarial examples, so the final loss is computed as: $Loss(w;\hat\theta)+Loss(w+\eta;\hat\theta)$.
| 标题 | 说明 | 时间 |
|---|---|---|
| Adversarial training for multi-context joint entity and relation extraction | 论文原文 | 2018 |
| multihead_joint_entity_relation_extraction | 论文实现 | 20190429 |
Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction
Abstract
Most work in relation extraction forms a prediction by looking at a short span of text within a single sentence containing a single entity pair mention. This approach often does not consider interactions across mentions, requires redundant computation for each mention pair, and ignores relationships expressed across sentence boundaries. These problems are exacerbated by the document- (rather than sentence-) level annotation common in biological text. In response, we propose a model which simultaneously predicts relationships between all mention pairs in a document. We form pairwise predictions over entire paper abstracts using an efficient self-attention encoder. All-pairs mention scores allow us to perform multi-instance learning by aggregating over mentions to form entity pair representations. We further adapt to settings without mention-level annotation by jointly training to predict named entities and adding a corpus of weakly labeled data. In experiments on two Biocreative benchmark datasets, we achieve state of the art performance on the Biocreative V Chemical Disease Relation dataset for models without external KB resources. We also introduce a new dataset an order of magnitude larger than existing human-annotated biological information extraction datasets and more accurate than distantly supervised alternatives.
摘要
关系提取中的大多数工作通过查看包含单个实体对提及的单个句子中的短文本来形成预测。这种方法通常不考虑提及的交互,需要对每个提及对进行冗余计算,并忽略跨句子边界表达的关系。生物文本中常见的文档(而不是句子)级别注释加剧了这些问题。作为回应,我们提出了一个模型,它同时预测文档中所有提及对之间的关系。我们使用有效的自我关注编码器在整个纸质摘要上形成成对预测。所有对提及分数允许我们通过聚合提及以形成实体对表示来执行多实例学习。我们通过联合训练来预测命名实体并添加弱标记数据的语料库,从而进一步适应没有提及级别注释的设置。在两个Biocreative基准数据集的实验中,我们在Biocreative V Chemical Disease Relation数据集上获得了没有外部KB资源的模型的最新性能。我们还引入了一个比现有的人类注释生物信息提取数据集大一个数量级的新数据集,并且比远程监督的替代方案更准确。
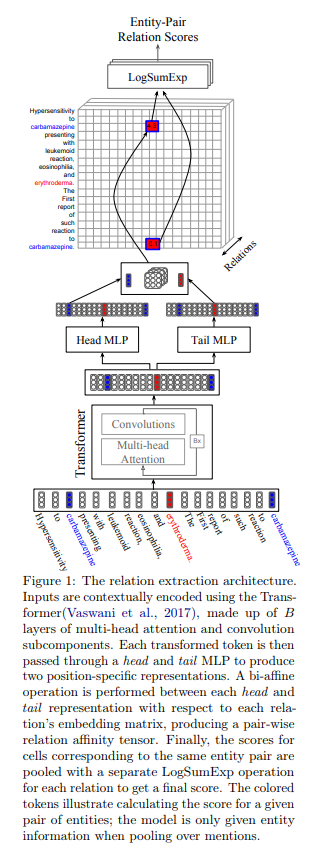
| 标题 | 说明 | 时间 |
|---|---|---|
| Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction | 论文原文 | 2018 |
End-to-end neural relation extraction using deep biaffine attention
We propose a neural network model for joint extraction of named entities and relations between them, without any hand-crafted features. The key contribution of our model is to extend a BiLSTM-CRF-based entity recognition model with a deep biaffine attention layer to model second-order interactions between latent features for relation classification, specifically attending to the role of an entity in a directional relationship. On the benchmark “relation and entity recognition” dataset CoNLL04, experimental results show that our model outperforms previous models, producing new state-of-the-art performances.
我们提出了一种神经网络模型,用于联合提取命名实体及其之间的关系,没有任何手工制作的特征。 我们模型的关键贡献是扩展基于BiLSTM-CRF的实体识别模型,该模型具有深的biaffine注意层,以模拟关系分类的潜在特征之间的二阶相互作用,特别是关注实体在方向关系中的角色。 在基准“关系和实体识别”数据集CoNLL04上,实验结果表明我们的模型优于以前的模型,产生了新的最先进的性能。

A Unified Model for Joint Chinese Word Segmentation and Dependency Parsing
Chinese word segmentation and dependency parsing are two fundamental tasks for Chinese natural language processing. The dependency parsing is defined on word-level, therefore word segmentation is the precondition of dependency parsing, which makes dependency parsing suffers from error propagation. In this paper, we propose a unified model to integrate Chinese word segmentation and dependency parsing. Different from previous joint models, our proposed model is a graph-based model and more concise, which results in fewer efforts of feature engineering. Our joint model achieves better performance than previous joint models. Our joint model achieves the state-of-the-art results in both Chinese word segmentation and dependency parsing.
中文分词和依赖解析是中文自然语言处理的两个基本任务。 依赖性解析是在字级别定义的,因此分词是依赖性解析的前提条件,这使得依赖性解析受到错误传播的影响。 在本文中,我们提出了一个统一的模型来集成中文分词和依赖解析。 与以前的联合模型不同,我们提出的模型是基于图形的模型,更简洁,从而减少了特征工程的工作量。 我们的联合模型比以前的联合模型具有更好的性能。 我们的联合模型在中文分词和依赖分析中实现了最先进的结果。
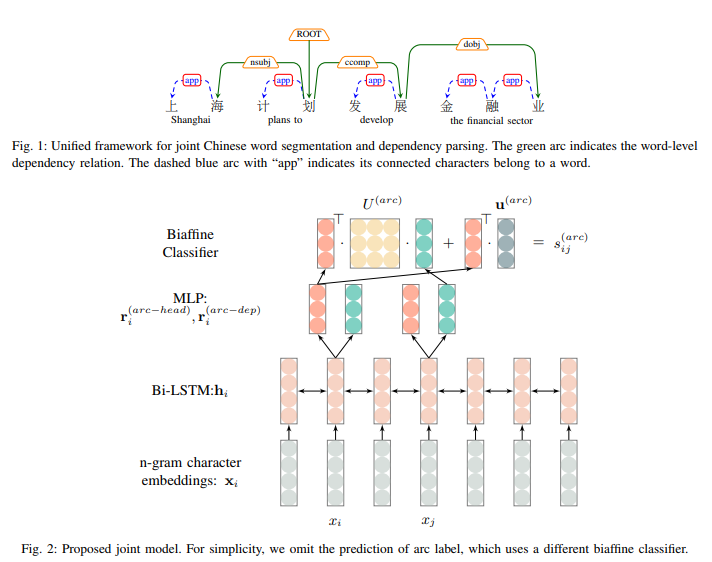
| 标题 | 说明 | 时间 |
|---|---|---|
| A Unified Model for Joint Chinese Word Segmentation and Dependency Parsing | 论文原文 | 20190409 |
| 联合汉语分词和依存句法分析的统一模型:当前效果最佳 | 论文浅析 | 20190427 |
Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers
this work is the first approach that can solve multi-relation extraction (MRE) task accurately to achieve state-of-the-art results and fast (in one-pass).
Abstract
Most approaches to extraction multiple relations from a paragraph require multiple passes over the paragraph. In practice, multiple passes are computationally expensive and this makes difficult to scale to longer paragraphs and larger text corpora. In this work, we focus on the task of multiple relation extraction by encoding the paragraph only once (one-pass). We build our solution on the pre-trained self-attentive (Transformer) models, where we first add a structured prediction layer to handle extraction between multiple entity pairs, then enhance the paragraph embedding to capture multiple relational information associated with each entity with an entity-aware attention technique. We show that our approach is not only scalable but can also perform state-of-the-art on the standard benchmark ACE 2005.
摘要
从段落中提取多个关系的大多数方法都要求在段落上多次传递。 在实践中,多次通过在计算上是昂贵的,并且这使得难以扩展到更长的段落和更大的文本语料库。 在这项工作中,我们通过仅对段落进行一次编码(一次通过)来专注于多关系提取的任务。 我们在预训练的自我关注(Transformer)模型上构建我们的解决方案,我们首先添加结构化预测层来处理多个实体对之间的提取,然后增强段落嵌入以捕获与每个实体关联的多个关系信息与实体 - 注意技术。 我们表明,我们的方法不仅可扩展,而且还可以在标准基准ACE 2005上执行最先进的技术。



