对抗训练基础知识
对抗样本定义

对抗样本是使得机器学习的算法产生误判的样本,如上图所示,原有的模型以57.7%的置信度判定图片为熊猫,但添加微小的扰动后,模型以99.3%的置信度认为扰动后的图片是长臂猿。
产生对抗样本的方法
基于梯度的方法
$J(\theta;x;y)$是模型的损失函数,其中负梯度方向$-\nabla J_x(\theta;x;y)$是模型损失下降最快的方向,为了使$\hat x$对模型输出产生最大的改变,正梯度方向为扰动最大的方向,在该方向上进行扰动,可以快速产生对抗样本,该方法称为“快速符号梯度法”(fast gradient sign medthod,FGSM),见Ian J. Goodfellow 在2014发表的论文Explaining and Harnessing Adversarial Examples。
基于超平面分类
Deepfool是基于超平面分类思想的一种对抗样本生成方法。众所周知,在二分类问题中,超平面是实现分类的基础 ,那么要改变某个样本 x 的分类,最小的扰动就是将 x 挪到超平面上,这个距离的代价最小。多分类的问题也是类似。
显然我们希望模型可以变得更加鲁棒。一个最简单的方法,就是生成这些数据,并且把这些数据加入到训练数据中。这样模型就会正视这些数据,并且尽可能地拟合这些数据,最终完成了模型拟合,这些盲区也就覆盖住了。将对抗样本和原有数据一起进行训练,对抗样本产生的损失作为原损失的一部分,即在不修改原模型结构的情况下增加模型的损失,产生正则化的效果。
对抗攻击
对抗攻击指的是在模型原始输入上添加对抗扰动构建对抗样本从而使模型产生错误判断的过程。而在这一过程中,对抗扰动的选择和产生是关键。对抗扰动指的是在模型输入上添加能够误导模型输出的微小变。
虽然不同的文章对于对抗扰动的定义略有不同,但是一般来说对抗扰动具有两个特点:
- 扰动是微小的甚至是肉眼难以观测到的;
- 添加的扰动必须有能力使得模型产生错误的输出。
对抗攻击的分类
| 分类标准 | 名称 | 说明 |
|---|---|---|
| 按对原始模型的访问权限不同 | 黑盒攻击与白盒攻击 | 白盒攻击指的是攻击者可以完全访问目标模型,他们可以了解模型的架构,参数和权重。黑盒攻击指的是攻击者很少或根本没有关于目标模型的知识,他们无法对其进行探测。在这种情况下,攻击者通常训练自己的模型并利用对抗性样本的可转移性来进行攻击。当然,白盒和黑盒攻击都无法改变模型和训练数据。在实际应用中,这两者的区别体现为:通过模型A来生成对抗样本,进而攻击模型B。当模型A与模型B是一个模型时,为白盒攻击;当模型A与模型B不为一个模型时,则为黑盒攻击。 |
| 按攻击目的 | 目标攻击和非目标攻击 | 目标攻击指的是生成的对抗样本希望被模型错分到某个特定的类别上。非目标攻击指的是对抗样本只要能让模型分错就行,不论错分到哪个类别都可以。 |
常见对抗样本防御方法
由于目前防御方法仍然没有一个权威的分类方式,故笔者将目前看到过的一些防御方法大致分为以下四类:对抗训练、梯度掩码、随机化、去噪等。
- 对抗训练:对抗训练旨在从随机初始化的权重中训练一个鲁棒的模型,其训练集由真实数据集和加入了对抗扰动的数据集组成,因此叫做对抗训练。
- 梯度掩码:由于当前的许多对抗样本生成方法都是基于梯度去生成的,所以如果将模型的原始梯度隐藏起来,就可以达到抵御对抗样本攻击的效果。
- 随机化:向原始模型引入随机层或者随机变量。使模型具有一定随机性,全面提高模型的鲁棒性,使其对噪声的容忍度变高。
- 去噪:在输入模型进行判定之前,先对当前对抗样本进行去噪,剔除其中造成扰动的信息,使其不能对模型造成攻击。
对抗训练
对抗训练是 Ian J. Goodfellow 在 Explaining and Harnessing Adversarial Examples 最早提出来的一个对抗样本的防御方法。它的主要思想是:在模型训练过程中,训练样本不再只是原始样本,而是原始样本加上对抗样本,就相当于把产生的对抗样本当作新的训练样本加入到训练集中,对它们一视同仁,那么随着模型越来越多的训练,一方面原始图片的准确率会增加,另一方面,模型对对抗样本的鲁棒性也会增加。
Adversarial training for multi-context joint entity and relation extraction 内容:
Adversarial training (AT) (Goodfellow et al., 2015) has been proposed to make classifiers more robust to input perturbations in the context of image recognition. In the context of NLP, several variants have been proposed for different tasks such as text classification (Miyato et al., 2017), relation extraction (Wu et al., 2017) and POS tagging (Yasunaga et al., 2018). AT is considered as a regularization method. Unlike other regu- larization methods (i.e., dropout (Srivastava et al., 2014), word dropout (Iyyer et al., 2015)) that introduce random noise, AT generates perturbations that are variations of examples easily misclassified by the model.
对抗训练指的是在模型的训练过程中构建对抗样本并将对抗样本和原始样本混合一起训练模型的方法,换句话说就是在模型训练的过程中对模型进行对抗攻击从而提升模型对于对抗攻击的鲁棒性(也称为防御能力)。
对抗训练局限性
对抗训练(以及集成对抗训练)确实是防御对抗样本攻击的有效方法,但是它也存在着局限性。对抗训练是通过不断输入新类型的对抗样本进行训练,从而不断提升模型的鲁棒性。为了保证有效性,该方法需要使用高强度的对抗样本,并且网络架构要有充足的表达能力。而且无论添加多少对抗样本,都存在新的对抗样本可以欺骗网络。
对抗攻击例子
Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers 中例子: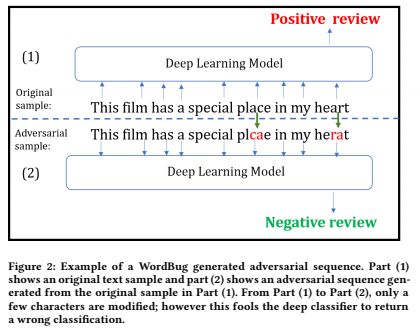
part1 指的是原始的输入文本,part2 指的是对原始数据进行离散扰动后的文本,虽然只有少量字符被修改但是模型产生了完全不同的输出。在文本处理中,对抗扰动的特征 1 要求添加扰动后产生的对抗样本与原样本在语义上保持一致,即添加的扰动应该尽量不改变原始句子的语义。
MNIST 实验
如下是在MNIST数据集上进行对抗训练的实验结果,红色线表示使用了对抗训练数据,蓝色表示没有使用。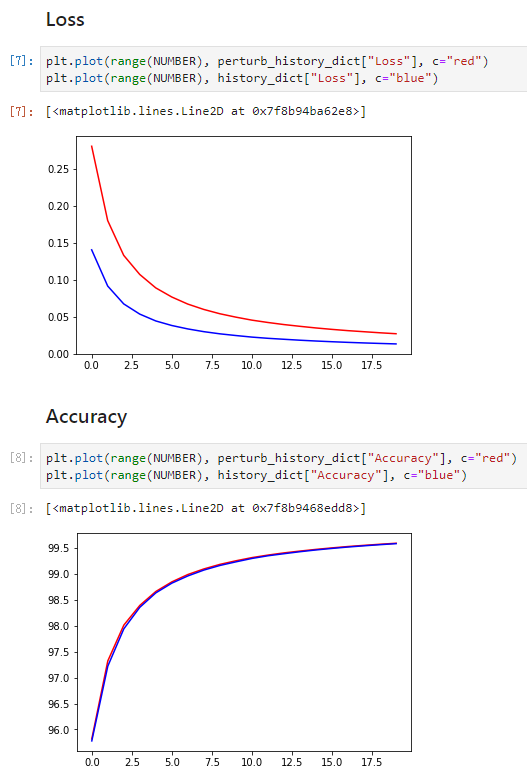
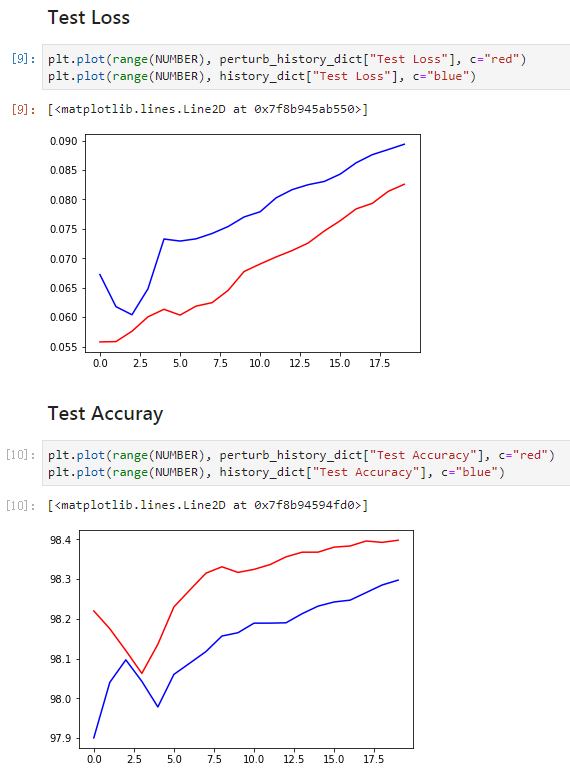
结论:
- 在MNIST训练集上,使用对抗训练会的模型损失增大,但是可以保持准确率与不使用对抗训练模型一致;
- 在MNIST验证集上,使用对抗训练的模型损比不使用对抗训练的模型损失更小、准确率更高。
常见问题解答
对模型正则化以后是不是仍然用原来的对抗样本来做实验?
对模型正则化以后是不是仍然用原来的对抗样本来做实验,如果是那就没有意义,因为模型参数改变了,对抗样本应该重新生成;如果不是,那很难理解,因为模型的线性特性并没有改变,仍然可以找到对抗样本,没有理由错误率会降低。我觉得这里可以这么解释为什么重新生成对抗样本,错误率还是降低了。因为对于强正则化,模型的权重会变得比较小,输入扰动对模型的输出影响不仅取决于它本身,还与模型权重有关,既然加入了惩罚项对样本的扰动进行惩罚,那么模型就会降低权重来减小扰动带来的损失。
实验结果表明对抗训练确实大幅提升了模型对白盒攻击的鲁棒性,但是对于黑盒攻击,甚至出现了比原始模型更高的错误率?
因为对抗训练是针对某一个模型产生的对抗样本进行学习,那么模型势必会更具有针对性,所以就可能在面对其他模型生成的对抗样本攻击时会出现比原始模型更高的错误率。另外,还可以通过实验结果发现各个模型普遍对于对抗模型产生的对抗样本具有好的鲁棒性。这个现象验证了作者提出的一个观点,即对抗训练不仅仅是拟合了对模型有影响的扰动,其同时弱化了单步攻击时需要依赖的模型的线性假设,因此造成了使用单步攻击时的效果变差。为了进一步提升模型对黑盒攻击的鲁棒性,作者将生成对抗样本的模型从单个变成了多个,增加了对抗样本的多样性,削弱对抗训练时对单个模型的过拟合。观察实验结果发现,集成对抗训练对于白盒攻击的鲁棒性不如对抗训练,这是由于对抗训练增强的数据集恰恰就是白盒攻击的数据集,所以对白盒攻击的鲁棒性会更强,如果集成对抗训练使用的模型越多,则对白盒攻击的鲁棒性越差。但是,在黑盒攻击中,集成对抗训练表现出了很强的鲁棒性。
对抗训练相关阅读资料
这部分内容主要是有关对抗学习理论的研究
2014 Explaining and Harnessing Adversarial Examples
Several machine learning models, including neural networks, consistently misclassify adversarial examples—-inputs formed by applying small but intentionally worst-case perturbations to examples from the dataset, such that the perturbed input results in the model outputting an incorrect answer with high confidence. Early attempts at explaining this phenomenon focused on nonlinearity and overfitting. We argue instead that the primary cause of neural networks’ vulnerability to adversarial perturbation is their linear nature. This explanation is supported by new quantitative results while giving the first explanation of the most intriguing fact about them: their generalization across architectures and training sets. Moreover, this view yields a simple and fast method of generating adversarial examples. Using this approach to provide examples for adversarial training, we reduce the test set error of a maxout network on the MNIST dataset.
包括神经网络在内的几种机器学习模型始终错误地分类对抗性示例 - 通过对数据集中的示例应用小但有意的最坏情况扰动而形成的输入,使得扰动的输入导致模型以高置信度输出不正确的答案。 早期解释这种现象的尝试集中在非线性和过度拟合上。 我们认为神经网络易受对抗性扰动的主要原因是它们的线性特性。 这个解释得到了新的定量结果的支持,同时首先解释了关于它们的最有趣的事实:它们跨架构和训练集的泛化。 此外,该视图产生了一种生成对抗性示例的简单快速的方法。 使用此方法为对抗训练提供示例,我们减少了MNIST数据集上maxout网络的测试集错误。
| 标题 | 说明 | 时间 |
|---|---|---|
| Explaining and Harnessing Adversarial Examples | 论文原文 | 20141220 |
| 论文阅读:Explaining and Harnessing Adversarial Examples(解释分析对抗样本) | 论文解析 | 20180402 |
2015 Distributional Smoothing with Virtual Adversarial Training
由于文本不同于图片,文本一般转化为Index,通过Embedding后输入到network中,无法对input进行直接的求导,Miyato3 等提出将扰动添加到Embedding层,经过扰动后的Embedding对扰动有更好的鲁棒性。其模型结构为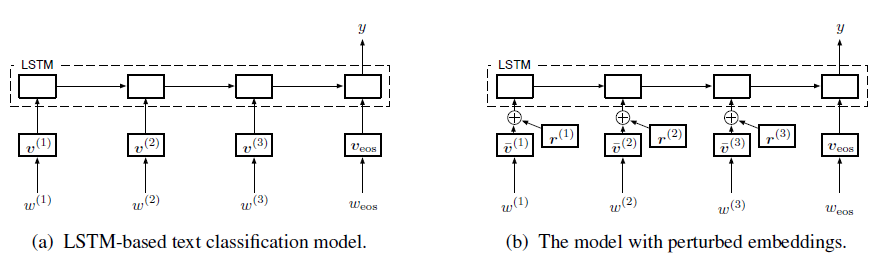
We propose local distributional smoothness (LDS), a new notion of smoothness for statistical model that can be used as a regularization term to promote the smoothness of the model distribution. We named the LDS based regularization as virtual adversarial training (VAT). The LDS of a model at an input datapoint is defined as the KL-divergence based robustness of the model distribution against local perturbation around the datapoint. VAT resembles adversarial training, but distinguishes itself in that it determines the adversarial direction from the model distribution alone without using the label information, making it applicable to semisupervised learning. The computational cost for VAT is relatively low. For neural network, the approximated gradient of the LDS can be computed with no more than three pairs of forward and back propagations. When we applied our technique to supervised and semi-supervised learning for the MNIST dataset, it outperformed all the training methods other than the current state of the art method, which is based on a highly advanced generative model. We also applied our method to SVHN and NORB, and confirmed our method’s superior performance over the current state of the art semi-supervised method applied to these datasets.
2017 Adversarial Dropout for Supervised and Semi-supervised Learning
Recently, the training with adversarial examples, which are generated by adding a small but worst-case perturbation on input examples, has been proved to improve generalization performance of neural networks. In contrast to the individually biased inputs to enhance the generality, this paper introduces adversarial dropout, which is a minimal set of dropouts that maximize the divergence between the outputs from the network with the dropouts and the training supervisions. The identified adversarial dropout are used to reconfigure the neural network to train, and we demonstrated that training on the reconfigured sub-network improves the generalization performance of supervised and semi-supervised learning tasks on MNIST and CIFAR-10. We analyzed the trained model to reason the performance improvement, and we found that adversarial dropout increases the sparsity of neural networks more than the standard dropout does.
| 标题 | 说明 | 时间 |
|---|---|---|
| Adversarial Dropout for Supervised and Semi-supervised Learning | 论文原文 | 20170712 |
| 对抗训练-Adversarial Training for Supervised and Semi-Supervised Learning(对抗训练在监督和半监督学习上的应用) | 论文解析 | 20181018 |
| 半监督文本分类的对抗训练 | 论文解析 | 20181231 |
2018 Certifying Some Distributional Robustness with Principled Adversarial Training
深度学习顶会“无冕之王”ICLR 2018评审结果出炉,斯坦福大学对抗训练研究得分第一。
Neural networks are vulnerable to adversarial examples and researchers have proposed many heuristic attack and defense mechanisms. We address this problem through the principled lens of distributionally robust optimization, which guarantees performance under adversarial input perturbations. By considering a Lagrangian penalty formulation of perturbing the underlying data distribution in a Wasserstein ball, we provide a training procedure that augments model parameter updates with worst-case perturbations of training data. For smooth losses, our procedure provably achieves moderate levels of robustness with little computational or statistical cost relative to empirical risk minimization. Furthermore, our statistical guarantees allow us to efficiently certify robustness for the population loss. For imperceptible perturbations, our method matches or outperforms heuristic approaches.
神经网络容易受到对抗性的影响,研究人员提出了许多启发式攻击和防御机制。 我们通过分布式鲁棒优化的原理镜头来解决这个问题,这保证了在对抗性输入扰动下的性能。 通过考虑拉格朗日惩罚公式扰乱 Wasserstein balls 的基础数据分布,我们提供了一个训练程序,增加了模型参数更新与最坏情况下的训练数据扰动。 对于平滑损失,我们的程序可证明实现了中等水平的稳健性,与经验风险最小化相比,计算或统计成本很低。 此外,我们的统计保证使我们能够有效地证明 population 损失的稳健性。 对于难以察觉的扰动,我们的方法匹配或优于启发式方法。
2019 Towards a Robust Deep Neural Network in Text Domain A Survey
Deep neural networks (DNNs) have shown an inherent vulnerability to adversarial examples which are maliciously crafted on real examples by attackers, aiming at making target DNNs misbehave. The threats of adversarial examples are widely existed in image, voice, speech, and text recognition and classification. Inspired by the previous work, researches on adversarial attacks and defenses in text domain develop rapidly. In order to make people have a general understanding about the field, this article presents a comprehensive review on adversarial examples in text. We analyze the advantages and shortcomings of recent adversarial examples generation methods and elaborate the efficiency and limitations on countermeasures. Finally, we discuss the challenges in adversarial texts and provide a research direction of this aspect.
深度神经网络(DNN)已显示出对抗性示例的固有漏洞,这些示例是攻击者在真实示例中恶意制作的,旨在使目标DNN行为不端。 对抗性示例的威胁在图像,语音,语音,文本识别和分类中广泛存在。 受以往工作的启发,对文本域中的对抗性攻击和防御的研究迅速发展。 为了使人们对该领域有一个大致的了解,本文对文本中的对抗性例子进行了全面的回顾。 我们分析了近期对抗性实例生成方法的优缺点,并详细阐述了对策的效率和局限性。 最后,我们讨论对抗性文本中的挑战,并提供这方面的研究方向。
这部分内容是对抗训练应用于各个模型
2017 Multi-Domain Adversarial Learning for Slot Filling in Spoken Language Understanding
对抗训练应用槽填充任务,这里使用对抗训练主要是为了训练出一个通用表示的槽填充模型,然后将这个模型的表示与特定领域模型的表示结合起来做预测,作用是减少了特定领域标签数据和提升模型效果。
2018 Adversarial training for multi-context joint entity and relation extraction
本文是 Joint entity recognition and relation extraction as a multi-head selection problem 的姊妹篇,都是同一个多头选择实体关系抽取模型,只是增加了对抗训练这个神经网络正则化方法。

