原文 Auto-classification of NAVER Shopping Product Categories using TensorFlow
背景
NAVER Shopping是NAVER提供的购物门户服务。 NAVER Shopping将产品与类别相匹配,以便系统地组织产品并允许更轻松地搜索用户。 当然,每天将超过2000万个新注册产品与大约5,000个类别相匹配的任务是不可能手动完成的。
本文介绍了使用TensorFlow自动匹配NAVER购物产品类别的过程,并解释了我们如何解决在将机器学习应用于我们的服务所使用的实际数据的过程中出现的一些问题。
NAVER购物和产品类别
NAVER Shopping是一个购物门户服务,提供产品搜索,类别分类,价格比较和购物内容,以便用户可以轻松访问在NAVER Shopping上注册的卖家以及NAVER Smart Store中的产品。
NAVER Shopping系统地组织产品并将产品分类,以便更轻松地搜索用户。类别分为上类>中类>下类,例如时尚商品>女鞋>平底鞋>休闲鞋。
目前,NAVER Shopping管理的大约5,000个类别。当用户输入关键字以在NAVER Shopping上搜索产品时,它识别输入的关键字的类别,然后根据搜索逻辑列出与关键字类别匹配的产品。为了使用户能够快速找到产品并获得所需的搜索结果,产品应与相应的类别相匹配。
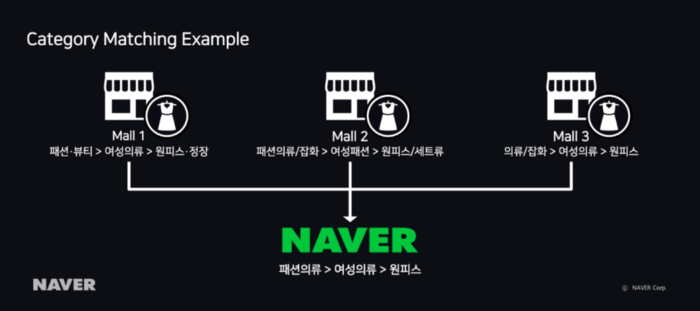
在NAVER Shopping上注册的卖家在测试文件中创建各种产品信息,包括根据EP(引擎页面)指南的卖家类别信息,这是NAVER Shopping上产品注册的数据表格,并将其发送给NAVER Shopping。
在发送给NAVER Shopping的各种产品信息中,卖家使用的类别系统可能会有所不同。因此,如上面的类别匹配示例所示,相同的服装可以具有非常不同的类别信息。
为了通过提高搜索准确度来提高购物搜索质量,有必要将卖家使用的类别与适合NAVER购物的类别相匹配。问题是,一个人不可能逐个将新产品与500个NAVER购物类别相匹配。
虽然我们还使用了基于规则的类别匹配,例如卖家的“桌面硬盘”类别如何映射到NAVER Shopping的“HDD”类别,但随着卖家和产品数量的增加,我们再也无法使用基于规则的类别,并且因为NAVER Shopping中的类别经常被重组。相反,可以通过应用自然语言处理(NLP)和计算机视觉等技术来自动化类别匹配。
在为Naver购物服务调整NLP时,很少有事情需要考虑。在大多数情况下,当使用现成的软件时,产品的属性(例如300ml / 500GB)或代码名称(例如SL-M2029,PIXMA-MX922)被归类为停用词并在此过程中被忽略。但是,这些术语对商业服务有意义。为了分析这些词,应该定制NLP过程以满足服务的需要。
类别自动匹配系统架构
目前,NAVER Shopping在类别自动匹配系统中使用如下架构进行学习和分类。
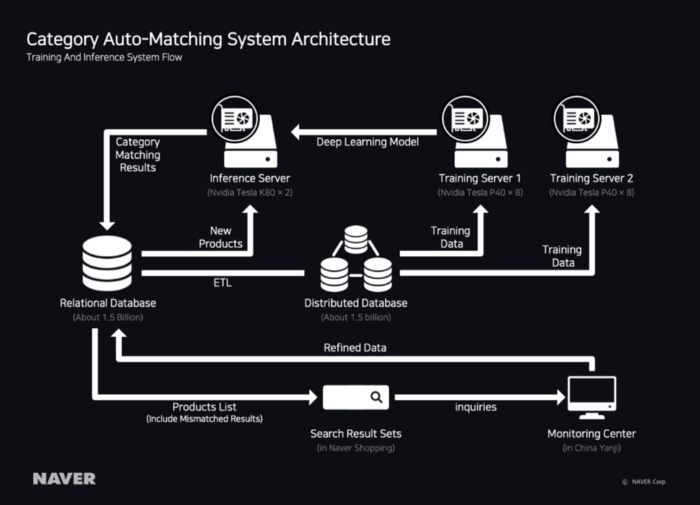
关系数据库中大约15亿条产品信息作为搜索结果集提供给用户。监控中心在搜索结果中查找与错误类别匹配的产品,并将其与正确的类别相匹配。由于监控中心匹配的产品的数据由人检查,因此将其视为精炼数据,然后从分布式数据库中提取为学习数据。除了精炼数据之外,还通过考虑产品的各种特征来提取学习数据。
训练服务器通过从分布式数据库读取数据来训练模型,并将增强模型分发到推理服务器。推理服务器每天读取大约2000万个产品的信息(尚未与NAVER类别匹配的产品)以匹配类别,然后更新到数据库。
类别自动匹配模型
NAVER Shopping的类别自动匹配模型分析产品数据的特征并通过以下过程训练模型。
- 发现产品的特征:从产品信息中寻找有用的特征。
- 形态分析:从产品信息中分析和提取术语。
- Word嵌入:将产品功能转换为矢量。
- CNN-LSTM 模型 - 产品名称:将CNN-LSTM型号应用于产品名称。
- MobileNetV2 - 产品图片:将MobileNetV2模型应用于产品图片。
- 多输入模型:通过产品中的各种数据连接模型以提高准确性。
产品特征
下图中标记的部分是用于自动匹配类别的特征。
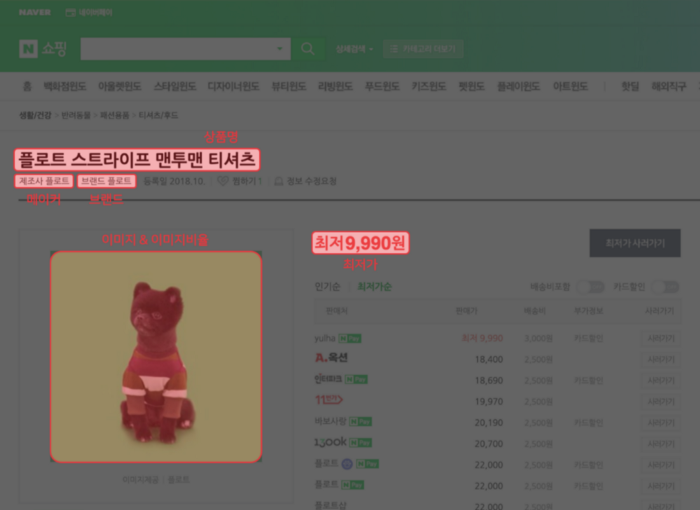
从上面的例子中,产品名称没有提到它是女性的T恤还是其他类别的T恤。但是,通过查看图像很容易看到,“产品名称”和“图像”是用户在购买产品时首先看到的元素。当从搜索结果中找到具有不正确类别匹配的产品时,监控中心应仔细查看产品名称和图像,以将产品移动到正确的类别。
因此,产品名称和图像也用作类别自动匹配的主要特征。不仅产品名称和图像,而且卖家使用的类别,产品的最低价格,品牌,制造商,原始图像比例也被用作卖家提供的数十条产品信息中的附加特征。
形态分析
用作主要特征的产品名称具有以下特征。
- 产品名称由名词组成;
- 混合韩语和英语的产品名称;
- 包含组合字母和数字的产品/型号代码的产品名称;
- 产品名称包含用于描述产品概念的词语(例如宽松合体);
- 没有空格分隔的产品名称。由于韩国人的特点,即使没有空格分隔也可以理解意义(汉语也具体有该特点)。
为了使产品名称具有适合购物领域的含义,描述概念的单词、模型代码和产品属性不应分开,而不带空格的产品名称则以术语单位提取。
词嵌入
我们尝试使用带有维基百科内容的预训练矢量,但认为产品数据的特征没有用于构建词嵌入。 因此,我们使用Word2vec方法直接构建了包含产品数据特征的字嵌入。是否正确构建嵌入向量(Word2vec的结果)可以使用TensorFlow的可视化工具TensorBoard进行探索。
CNN-LSTM Model — 产品名称
通过按以下顺序应用CNN-LSTM模型来解析产品名称,即文本数据。
- CNN模型:从产品名称中提取特定文本区域的功能。
- LSTM模型:根据长产品名称中的附近单词识别当前单词的含义。
- CNN-LSTM模型:CNN提取的局部特征依次集成在LSTM中。
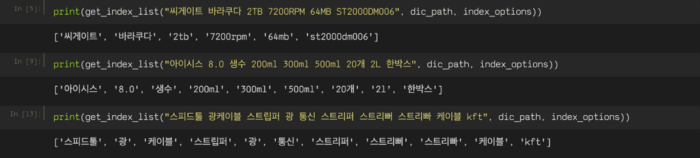
Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model
CNN滤波器可以在图像处理中提取特定图像区域的特征,并在文本处理中提取特定文本区域的特征。在NAVER Shopping的产品名称中,您可以看到出现的产品的主要关键字,无论位置如何。
通常,文本中的单词的含义(例如,反讽)基于附近的单词(单词之前和之后)来理解。既然如此,LSTM模型被称为适合于数据处理的模型,如本文中那样顺序出现。在NAVER Shopping的产品名称中,您可以看到仅在查看周围的关键字时才能进行分类的产品名称。
CNN-LSTM模型表现出更优越的性能。这是一种通过输入字嵌入(矢量)来提取局部特征然后使用LSTM模型顺序地集成特征来通过卷积层和最大池层的方法。
CNN模型可以通过将输入数据划分为多个区域来提取特定的本地信息,但是不能确定长句中的单词之间的依赖性。通过将CNN模型与LSTM模型组合以在句子中顺序地整合本地信息,可以解决这些限制。
MobileNetV2 - 产品图片
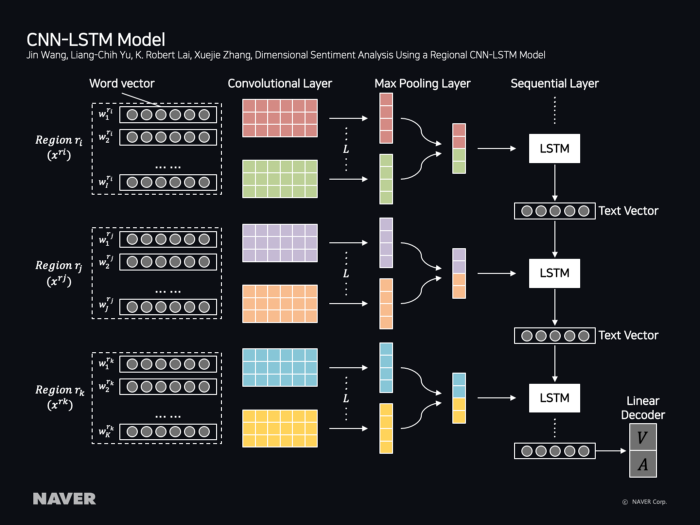
MobileNet是一种可用于图像分类和对象检测的模型。
与VGG相比,MobileNet的准确性相似。但是,与VGG相比,MobileNet的计算和参数数量为1/10,因此适用于没有GPU设备或需要实时性能的服务的服务器。
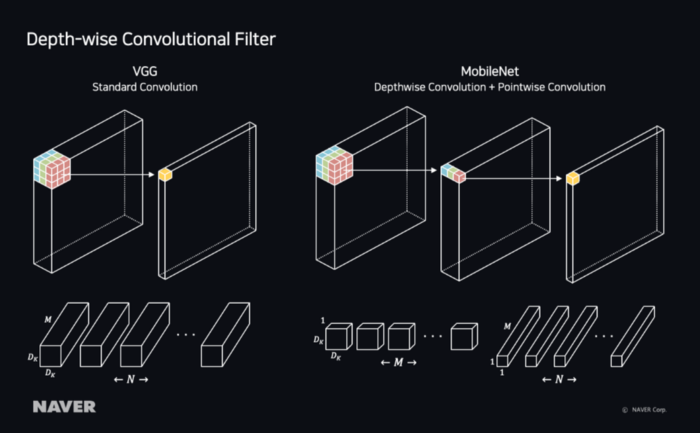
多输入模型 - 产品混合信息
对于类别的自动匹配,可以单独训练使用产品名称的模型和使用产品图像的模型。但是,由于产品名称和图像是单一产品的属性,因此集成训练实际上提高了模型的准确性。
如果您不仅对产品名称和图像进行综合培训,还要对品牌,制造商,原始图像比例,业务运营中使用的类别以及产品的最低价格进行综合培训,如下图所示,然后可以训练与产品相关的属性的相关性。
类别自动匹配和解决方案中发现的问题
将类别自动匹配应用于实际服务数据时发现了一些问题。
特征可视化
在应用类别自动匹配之前,必须有一种方法来验证匹配结果是否已正确分配。如果您上传适合的特征向量和标签到TensorFlow’s embedding projector,则可以轻松检查类别分布和类别之间的距离。通过单击一个点(类别),您可以看到该点附近的点(类似类别)是什么。如果该点位于可视化结果中的附近,但根本不在相关类别中,则表示它是具有错误匹配概率的类别。
数据规范化
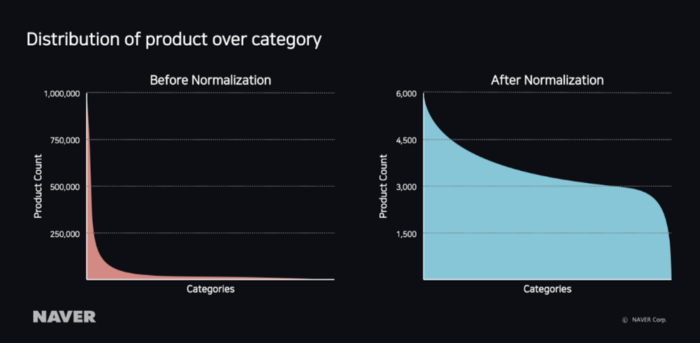
时装>女装>连衣裙的产品数量比率,NAVER购物的热门类别,生活/健康> DVD>文化/纪录片,不是一个流行的类别约1000:1,使数据高度不平衡。如果使用像这样的不平衡产品分布中的学习数据进行训练,则可能导致问题,其中适当的结果偏向具有更多产品的类别以提高整体准确性。
左下图是应用数据标准化之前,按类别的产品分布显示索引函数的形状。因此,我们将以下日志函数应用于数据规范化的学习数据:

通过应用数据规范化,产品数量按类别均匀分布,如右图所示,并且已经解决了偏向流行类别的适当结果的问题。
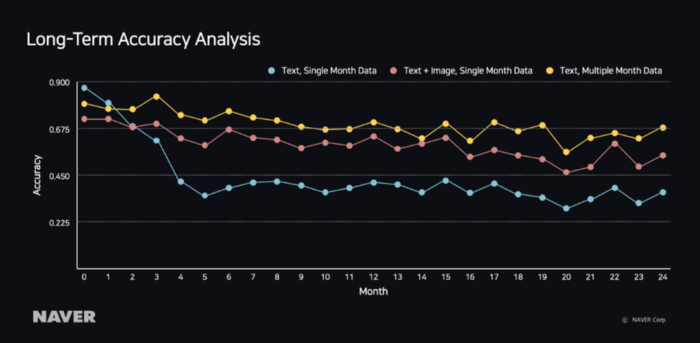
反映趋势
在线购物中心的产品寿命很短,对趋势非常敏感。特别是,由于每个季节都会生产服装等产品,因此存在产品不断被删除和创造的趋势。例如,仅使用文本学习的模型将发现仅在添加新趋势产品时读取单词时难以理解其类别,例如“Anorak”。学习文本和图像的模型可以通过使用图像添加一个名为“Anorak”的新产品时将其分类为夹克。
在这种情况下,我们应该分析长期准确性,如下图所示,以验证模型是否能够继续准确地预测,并让它跟随产品的趋势,同时不断更新学习数据和模型以满足趋势。
训练数据管道
通常,为了更新学习数据,我们必须从HDFS中提取SQL语法,将其保存为学习服务器中的文件,然后在代码中加载数据并重新训练模型。在这种通用方法中,随着学习数据变大,保存为文件和加载所花费的时间变得更长,以及占用服务的大量磁盘空间,使其效率低下。
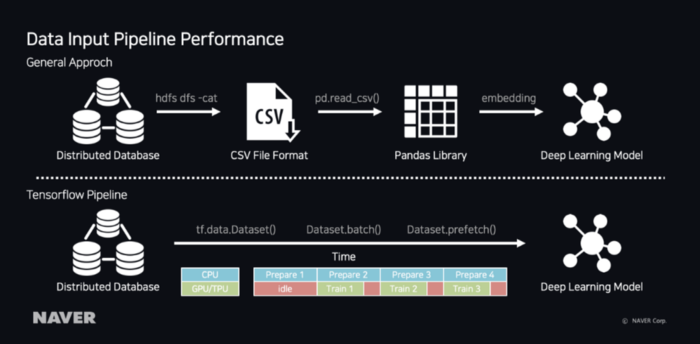
TensorFlow提供了一种使用tf.data管道直接从HDFS读取学习数据的方法。当使用该Dataset.prefetch()方法时,如下面的示例所使用的那样,由于它以块的形式读取数据,因此它可以在学习GPU中的第一个数据的同时在CPU中准备第二个数据,从而减少资源的空闲状态。
模棱两可的分类
NAVER Shopping的类别是为了方便用户而构建的,由于同名的许多较低类别,很难区分上层类别。由于允许模型学习并不是一个好的结构,因此有必要选择需要额外学习的类别来改变模型易于学习的结构,或管理标准类别(例如UNSPSC,联合国标准产品和服务代码)在商业环境中分开并让它学习。
卖家提供的信息不正确
在某些情况下,卖方通过将产品类别与NAVER购物类别进行第一手匹配来发送产品信息。该信息也是用于学习数据的条件,因为它是由人匹配的数据。但是,有时用于学习的主要产品元素包含错误。为了从学习数据中删除错误数据,我们应该使用诸如通过选择发送高质量产品信息的卖家来增加学习重量的方法。
总结
我们已经讨论了在NAVER Shopping中运行的类别自动匹配模型以及相关问题和解决方案。首先,我们从产品中发现了有用的特征,在文本数据的情况下分析了语素,并使用了CNN和LSTM模型。对于图像数据,我们使用MobileNet模型开发了类别自动匹配模型。
此外,我们还研究了使用TensorBoard的数据可视化,以及如何使用数据规范化和TensorFlow管道。
在提供这个项目的过程中,我们能够更全面地理解机器学习和深度学习的问题,在识别存在的其他问题的过程中,而不是仅仅考虑模型的准确性,将模型应用于实际服务环境。
目前,自动匹配的准确率约为85%。我们的目标是通过使用各种方法继续改进模型以实现更高的准确性,例如产品名称的日期细化,图像特征提取的效率和精确的验证集构建。

