中英文本纠错的差异
英文的拼写错误,大致可以分为两类:一类是英文单词拼写不合法(Non-Word Errors),造成错误的“词”在词典里没有对应的单词(Word),比如把artificial拼成artificel;还有一类是单词拼写合法,但在语境中错误(Real-Word Errors),比如把be interested in写成be interest in。与拼写不合法相比,这类错误更难被纠正。前者一般使用上下文无关(Context-Independent Methods)的方法解决,后者则通常使用上下文相关(Context-Dependent Methods)的方法识别。
在中文领域,纠错仍然是一道险关,因为很多中文的错误情况并不会在英文语境中发生。这是因为,英文是输入单个字母,组成词汇和句子,没有“输入法”的概念,最小处理单元是一个“单词”;而对于中文而言,我们依赖输入法来打字,而计算机显示的汉字字形都是预先设置好的,不会存在字形“无中生有”的情况,因此纠错处理单元针对的中文“词”,相当于英语的“词组(Phrase)”。中文语境出现的错误,错法往往千奇百怪:有输入法联想错误导致输入其他同音词,由此出现的搭配不当;有发音不准导致拼音输错;还有形近字、几乎约定俗成的错字等等,很难有成熟的规律一网打尽。汉语的表达主观且多样,如果没有海量语料来训练模型,则试验很难取得成效。因此,可以说,汉语的文本纠错难度要大大高于英语。
开源文本纠错工具pycorrector
中文文本纠错工具。音似、形似错字(或变体字)纠正,可用于中文拼音、笔画输入法的错误纠正。python3开发。pycorrector依据语言模型检测错别字位置,通过拼音音似特征、笔画五笔编辑距离特征及语言模型困惑度特征纠正错别字。
问题
中文文本纠错任务,常见错误类型包括:
- 谐音字词,如 配副眼睛-配副眼镜
- 混淆音字词,如 流浪织女-牛郎织女
- 字词顺序颠倒,如 伍迪艾伦-艾伦伍迪
- 字词补全,如 爱有天意-假如爱有天意
- 形似字错误,如 高梁-高粱
- 中文拼音全拼,如 xingfu-幸福
- 中文拼音缩写,如 sz-深圳
- 语法错误,如 想象难以-难以想象
当然,针对不同业务场景,这些问题并不一定全部存在,比如输入法中需要处理前四种,搜索引擎需要处理所有类型,语音识别后文本纠错只需要处理前两种, 其中’形似字错误’主要针对五笔或者笔画手写输入等。
解决方案
规则的解决思路
- 中文纠错分为两步走,第一步是错误检测,第二步是错误纠正;
- 错误检测部分先通过结巴中文分词器切词,由于句子中含有错别字,所以切词结果往往会有切分错误的情况,这样从字粒度和词粒度两方面检测错误, 整合这两种粒度的疑似错误结果,形成疑似错误位置候选集;
- 错误纠正部分,是遍历所有的疑似错误位置,并使用音似、形似词典替换错误位置的词,然后通过语言模型计算句子困惑度,对所有候选集结果比较并排序,得到最优纠正词。
深度模型的解决思路
- 端到端的深度模型可以避免人工提取特征,减少人工工作量,RNN序列模型对文本任务拟合能力强,rnn_attention在英文文本纠错比赛中取得第一名成绩,证明应用效果不错;
- CRF会计算全局最优输出节点的条件概率,对句子中特定错误类型的检测,会根据整句话判定该错误,阿里参赛2016中文语法纠错任务并取得第一名,证明应用效果不错;
- seq2seq模型是使用encoder-decoder结构解决序列转换问题,目前在序列转换任务中(如机器翻译、对话生成、文本摘要、图像描述)使用最广泛、效果最好的模型之一。
pycorrector文本纠错库中含有的神经网络模型举例
- kenlm:kenlm统计语言模型工具
- rnn_lm:TensorFlow、PaddlePaddle均有实现栈式双向LSTM的语言模型
- rnn_attention模型:参考Stanford University的nlc模型,该模型是参加2014英文文本纠错比赛并取得第一名的方法
- rnn_crf模型:参考阿里巴巴2016参赛中文语法纠错比赛CGED2018并取得第一名的方法
- seq2seq_attention模型:在seq2seq模型加上attention机制,对于长文本效果更好,模型更容易收敛,但容易过拟合
- transformer模型:全attention的结构代替了lstm用于解决sequence to sequence问题,语义特征提取效果更好
- bert模型:中文fine-tuned模型,使用MASK特征纠正错字
- conv_seq2seq模型:基于Facebook出品的fairseq,北京语言大学团队改进ConvS2S模型用于中文纠错,在NLPCC-2018的中文语法纠错比赛中,是唯一使用单模型并取得第三名的成绩
中文文本纠错方法举例
参见 中文汉字错别字纠错方法 CSDN
使用语言模型计算句子合法的概率,当概率值小于指定阈值时认为句子非法,即句子可能存在错误。中文文本的错别字存在局部性,即我们只需要选取合理的滑动窗口来检查是否存在错别字,下面举一个例子:
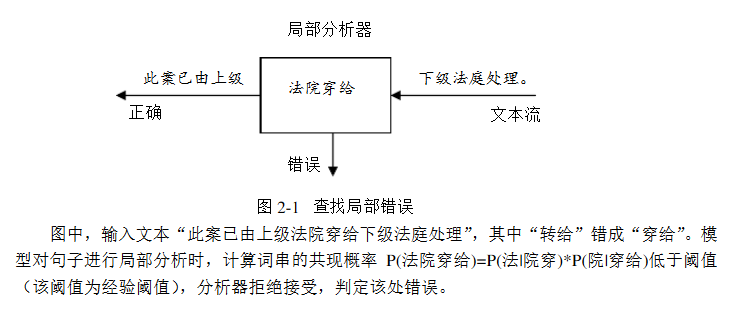
现实生活中也存在汉字拼音没打错,是词语选错了;或者n-gram检查合理但词语不存在。例如:
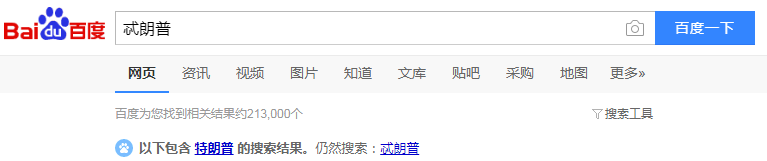
这时就用到最短编辑距离了,对于这种热搜词,我们仅需记录n-Top,然后用最短编辑距离计算相似度,提供相似度最高的那个候选项就可以了。编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
现有商用文本纠错技术探究
体验:

