阅读本篇前,最好先阅读多层感知机的反向传播算法。反向传播的基础知识和符号定义都在该文章中。
卷积神经网络:前向传播算法
CNN输入层前向传播到卷积层
输入层的前向传播是CNN前向传播算法的第一步。一般输入层对应的都是卷积层。
阅读本篇前,最好先阅读多层感知机的反向传播算法。反向传播的基础知识和符号定义都在该文章中。
输入层的前向传播是CNN前向传播算法的第一步。一般输入层对应的都是卷积层。
交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。
交叉熵的定义
交叉熵的应用
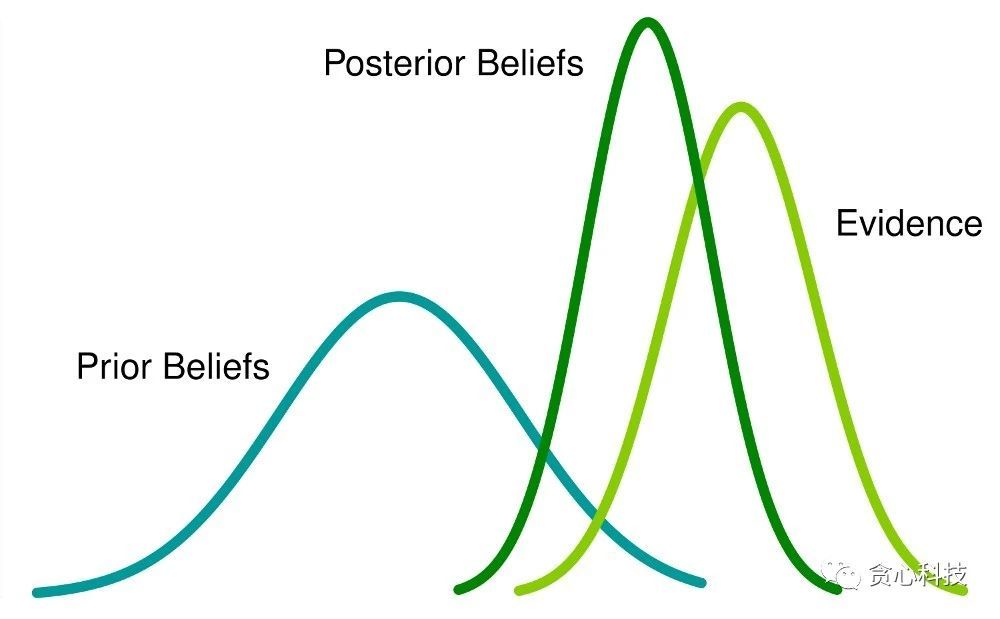
即使学过机器学习的人,对机器学习中的 MLE(极大似然估计)、MAP(最大后验估计)以及贝叶斯估计(Bayesian) 仍有可能一知半解。对于一个基础模型,通常都可以从这三个角度去建模,比如对于逻辑回归(Logistics Regression)来说:
在之前描述 MNIST 数据时,我说它分成了 60,000 个训练图像和 10,000 个测试图像。这是官方的 MNIST 的描述。实际上,我们将用稍微不同的方法对数据进行划分。我们将测试集保持原样,但是将 60,000 个图像的 MNIST 训练集分成两个部分:一部分 50,000 个图像,我们将用来训练我们的神经网络,和一个单独的 10,000 个图像的验证集。在本章中我们不使用验证数据,但是在本书的后面我们将会发现它对于解决如何去设置某些神经网络中的超参数是很有用的,例如学习率等,这些参数不被我们的学习算法直接选择。尽管验证数据不是原始 MNIST 规范的一部分,然而许多人以这种方式使用 MNIST,并且在神经网络中使用验证数据是很普遍的。从现在起当我提到“MNIST 训练数据”时,我指的是我们的 50,000 个图像数据集,而不是原始的 60,000图像数据集
原文链接:CHAPTER 1 Using neural nets to recognize handwritten digits
假设我们有这样的网络:
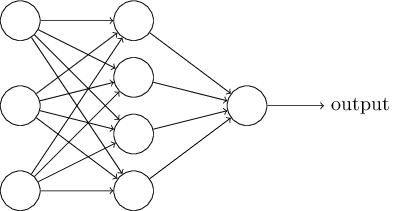
前面提过,这个网络中最左边的称为输入层,其中的神经元称为输入神经元。最右边的,即输出层包含有输出神经元,在本例中,输出层只有一个神经元。中间层,既然这层中的神经元既不是输入也不是输出,则被称为隐藏层。“隐藏”这一术语也许听上去有些神秘,我第一次听到这个词,以为它必然有一些深层的哲学或数学涵意,但它实际上仅仅意味着“既非输入也非输出”。上面的网络仅有一个隐藏层,但有些网络有多个隐藏层。例如,下面的四层网络
有两个隐藏层:
原文链接:CHAPTER 1 Using neural nets to recognize handwritten digits
在传统的编程方法中,我们告诉计算机做什么,把大问题分成许多小的、精确定义的任务,计算机可以很容易地执行。相比之下,在神经网络中,我们不告诉计算机如何解决我们的问题。相反,它从观测数据中学习,找出它自己的解决问题的方法。