原文链接:CHAPTER 4 A visual proof that neural nets can compute any function
神经网络的一个最显著的事实就是它可以计算任何的函数。不管这个函数是什么样的,总会确保有一个神经网络能够对任何可能的输入 $x$,其值 $f(x)$ (或者某个足够准确的近似)是网络的输出。 表明神经网络拥有一种普遍性。不论我们想要计算什么样的函数,我们都确信存在一个神经网络可以计算它。 而且,这个普遍性定理甚至在我们限制了神经网络只在输入层和输出层之间存在一个中间层的情况下成立。所以即使是很简单的网络架构都极其强大。普遍性定理在使用神经网络的人群中是众所周知的。但是它为何正确却不被广泛地理解。现有的大多数的解释都具有很强的技术性。
如果你是数学家,这个证明应该不大难理解,但对于大多数人还是很困难的。这不得不算是一种遗憾,因为这个普遍性背后的原理其实是简单而美妙的。在这一章,我给出这个普遍性定理的简单且大部分为可视化的解释。我们会一步步深入背后的思想。你会理解为何神经网络可以计算任何的函数。你会理解到这个结论的一些局限。并且你还会理解这些结论如何和深度神经网络关联的。
神经网络拥有强大的算法来学习函数。学习算法和普遍性的结合是一种有趣的混合。直到现在,本书一直是着重谈学习算法。到了本章,我们来看看普遍性,看看它究竟意味着什么。
两个预先声明
在解释为何普遍性定理成立前,我想要提下关于非正式的表述“神经网络可以计算任何函数”的两个预先声明。
第一点,这句话不是说一个网络可以被用来准确地计算任何函数。而是说,我们可以获得尽可能好的一个近似。通过增加隐藏元的数量,我们可以提升近似的精度。为了让这个表述更加准确,假设我们给定一个需要按照目标精度 $\epsilon > 0$ 的函数 $f(x)$。通过使用足够多的隐藏神经元使得神经网络的输出 $g(x)$ 对所有的 $x$,满足 $|g(x) - f(x)| < \epsilon$ 从而实现近似计算。换言之,近似对每个可能的输入都是限制在目标准确度范围内的。
第二点,就是可以按照上面的方式近似的函数类其实是连续函数。如果函数不是连续的,也就是会有突然、极陡的跳跃,那么一般来说无法使用一个神经网络进行近似。这并不意外,因为神经网络计算的就是输入的连续函数。然而,即使那些我们真的想要计算的函数是不连续的,一般来说连续的近似其实也足够的好了。如果这样的话,我们就可以用神经网络来近似了。实践中,这通常不是一个严重的限制。
总结一下,更加准确的关于普遍性定理的表述是包含一个隐藏层的神经网络可以被用来按照任意给定的精度来近似任何连续函数。
本章可视化证明的说明
我们会使用了两个隐藏层的网络来证明这个结果的弱化版本。然后我将简要介绍如何通过一些微调把这个解释适应于只使用一个隐藏层的网络的证明。
我们使用 S 型神经元作为神经网络的激活函数,在后面我们可以推广到其它激活函数。
证明的理论准备
S 型神经元作为神经网络的激活函数非常普遍,但是为了方便我们的证明,我们对 S 型神经元做一点点处理,把它变成阶跃函数(感知器)。实际上处理阶跃函数比一般的 S 型函数更加容易。原因是在输出层我们把所有隐藏神经元的贡献值加在一起。分析一串阶跃函数的和是容易的,相反,思考把一串 S 形状的曲线加起来是什么则要更困难些。所以假设我们的隐藏神经元输出阶跃函数会使事情更容易。更具体些,我们把权重 $w$ 固定在一个大的值,然后通过修改偏置设置阶跃函数的位置。当然,把输出作为一个阶跃函数处理只是一个近似,但是它是一个非常好的近似,现在我们把它看作是精确的。稍后我会再讨论偏离这种近似的影响。关于 S 型神经元和感知器的关系分析见 使用神经网络识别手写数字——感知器。
S 型函数变阶跃函数过程
S 型神经元的代数形式是,
其中,$z = w \cdot x+b$
S 型神经元的函数图形是,
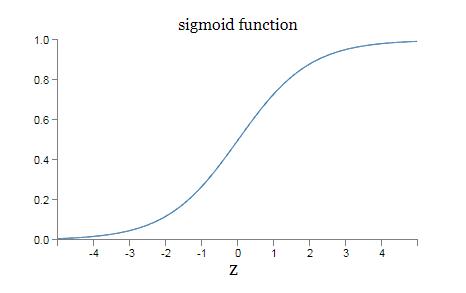
$x$ 取何值时阶跃会发生呢?换种方式,阶跃的位置如何取决于权重和偏置?
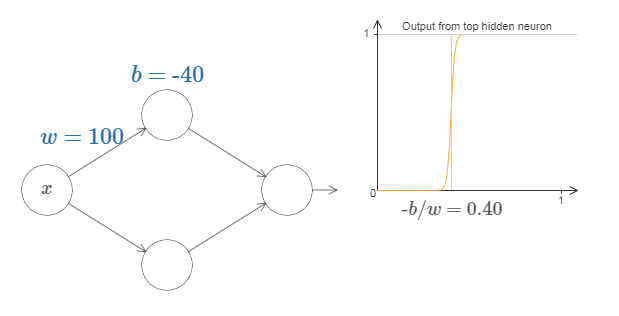
- 因为 $z = w \cdot x+b$ 是一个直线方程, $w$ 是直线的斜率, $b$ 是直线的截距,直线与 $x$ 轴的交点是 $(-b/w, 0)$,令 $s=-b/w$。
- 假设 $z \equiv w \cdot x + b$ 是一个很大的正数。那么 $e^{-z} \approx 0$ 而 $\sigma(z) \approx 1$。即,当 $z = w \cdot x+b$ 很大并且为正, S 型神经元的输出近似为 $1$,正好和感知器一样。相反地,假设 $z = w \cdot x+b$ 是一个很大的负数。那么$e^{-z} \rightarrow \infty$,$\sigma(z) \approx 0$。所以当 $z = w \cdot x +b$ 是一个很大的负数。
根据上面两点可以知道,当 $|w|$ 的值很大时,$x$ 就能直接决定 S 型神经元的函数结果为零还是为一,根据第一点还可以知道 $s=-b/w$ 就是阶跃的分界点。当 $x>s$ 时 S 型函数取 1,当 $x<s$时 S 型函数取 0。注意,$s=-b/w$ 时我们将在后文修补阶跃函数中讨论。
S 型神经元的函数变成阶跃函数图形是:
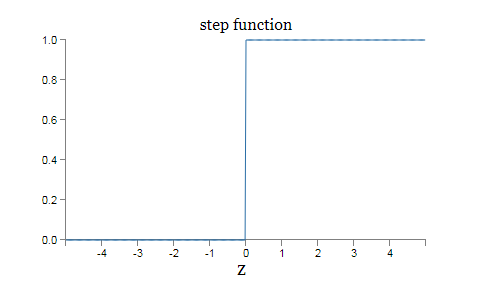
下面的证明中,我们总是让 $|w|$ 的值很大,也就是说我们将一直使用变成阶跃函数的 S 型神经元。并且用 $s$ 表示阶跃函数阶跃的位置。这将用仅仅一个参数 $s$ 来极大简化我们描述隐藏神经元的方式,这就是阶跃位置,$s =-b/w$。
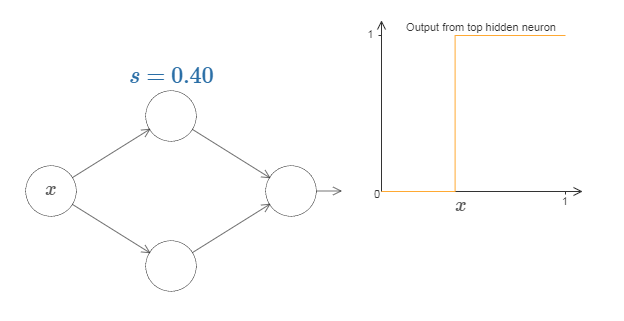
一个输入和一个输出的普遍性
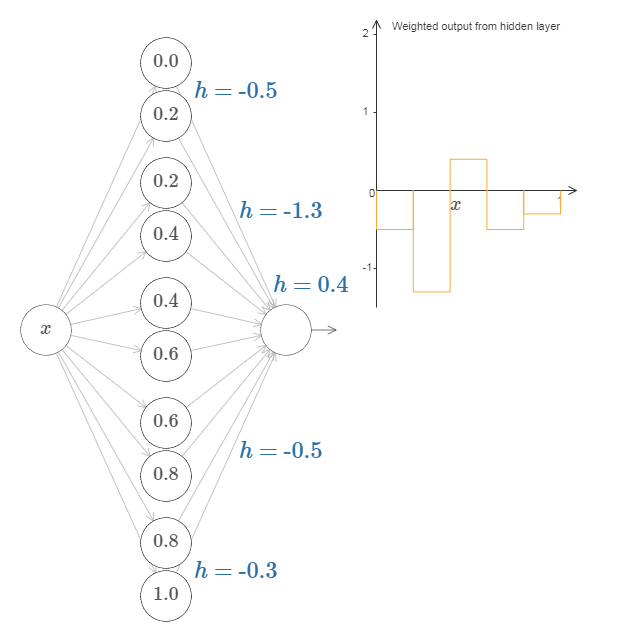
目前为止我们专注于仅仅从顶部隐藏神经元输出。让我们看看整个网络的行为。尤其,我们假设隐藏神经元在计算以阶跃点 $s_1$ (顶部神经元)和 $s_2$ (底部神经元)参数化的节约函数。它们各自有输出权重 $w_1$ 和 $w_2$。是这样的网络:
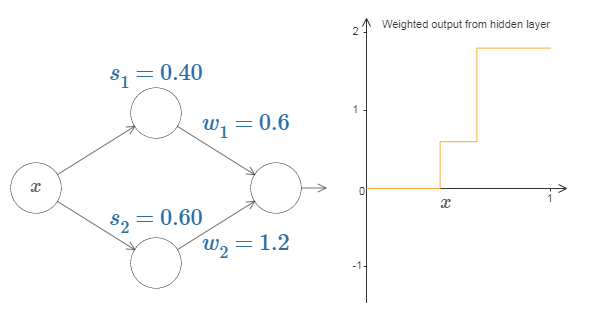
右边的绘图是隐藏层的加权输出 $w_1 a_1 + w_2 a_2$。这里 $a_1$ 和 $a_2$ 各自是顶部和底部神经元的输出。这些输出由 $a$ 表示,是因为它们通常被称为神经元的激活值。注意,注意整个网络的输出是 $\sigma(w_1 a_1+w_2 a_2 + b)$,其中 $b$ 是隐藏层的偏置。很明显,这不同于隐藏层加权后的输出,也就是我们这里的绘图。我们现在打算专注于隐藏层的加权输出,不一会就会考虑如何把它关联到整个网络的输出。
思考增加和减少每一个输出权重。注意,这如何调整从各自的隐藏神经元的贡献值。当一个权重是 0 时会发生什么?
最后,试着设置 $w_1$ 为 $0.8$,$w_2$ 为 $-0.8$。你得到一个“凸起”的函数,它从点 $s_1$ 开始,到点 $s_2$ 结束,高为 $0.8$。例如,加权后的输出可能看起来像这样:
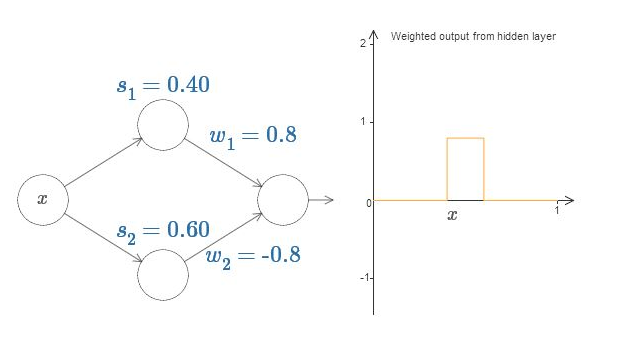
当然,我们可以调整为任意的凸起高度。让我们用一个参数,$h$,来表示高度。为了减少混乱我也会移除“$s_1 = \ldots$”和“$w_1 = \ldots$”的标记。
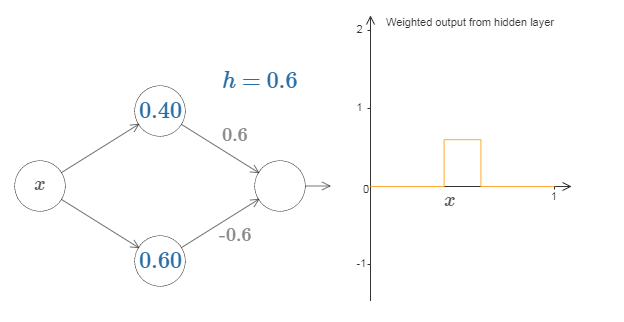
试着将 $h$ 值改大或改小,看看凸起的高度如何改变。试着把高度值改为负数,观察发生了什么。并且试着改变阶跃点来看看如何改变凸起的形状。我们可以用凸起制作的技巧来得到两个凸起,通过把两对隐藏神经元一起填充进同一个网络:
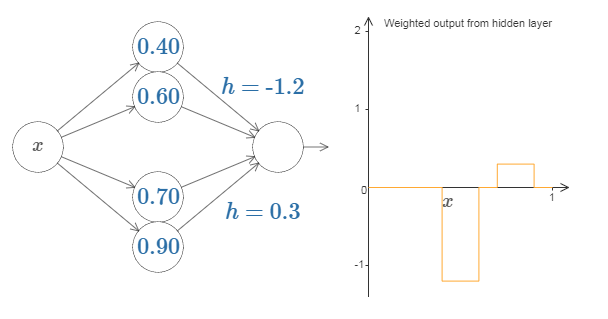
这里我抑制了权重,只是简单地在每对隐藏神经元上写了 $h$ 的值。试着增加和减少两个 $h$ 值,观察它如何改变图形。通过修改节点来移动凸起。更普遍地,我们可以利用这个思想来取得我们想要的任何高度的峰值。
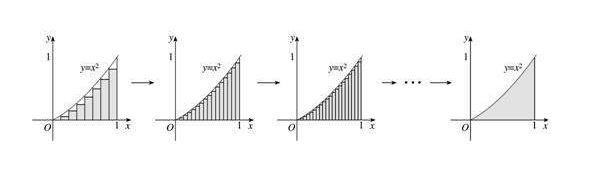
其实到这里我们可以说已经证明了神经网络在一个输入和一个输出上的普遍性,因为从微积分的观点来看,只需要增加“凸起”的个数,众多“凸起”合在一起的图形就可更加接近需要近似的函数图形。无限多个“凸起”就能无限逼近于目标函数。一个示意的例子如下,
让我快速总结一下那是如何工作的。
第一层的权重都有一些大的,恒定的值,比如:$w = 1000$。
隐藏神经元上的偏置只是 $b = -w s$。例如,对于第二个隐藏神经元 $s = 0.2$ 变成了 $b = -1000 \times 0.2 = -200$。
最后一层的权重由 $h$ 值决定。例如,我们上面已经选择的第一个 $h$,$h = -0.5$,意味着顶部两个隐藏神经元的相应的输出权重是 $-0.5$ 和 $0.5$。如此等等,确定整个层的输出权重。
最后,输出神经元的偏置为 $0$。
这是所有要做的事情:现在我们有了一个可以很好计算我们原始目标函数的神经网络的完整的描述。而且我们理解如何通过提高隐层神经元的数目来提高近似的质量。
在本质上,我们使用我们的单层神经网络来建立一个函数的查找表。我们将能够建立这个思想,以提供普遍性的一般性证明。
多个输入变量的普遍性
让我们把结果扩展到有很多个输入变量的情况下。这听上去挺复杂,但是所有我们需要的概念都可以在两个输入的情况下被理解。所以让我们处理两个输入的情况。我们从考虑当一个神经元有两个输入会发生什么开始:
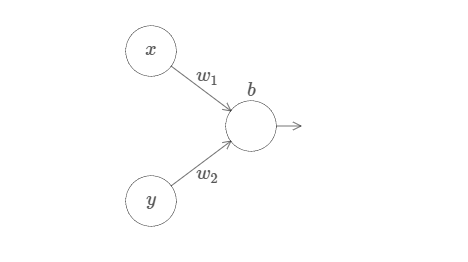
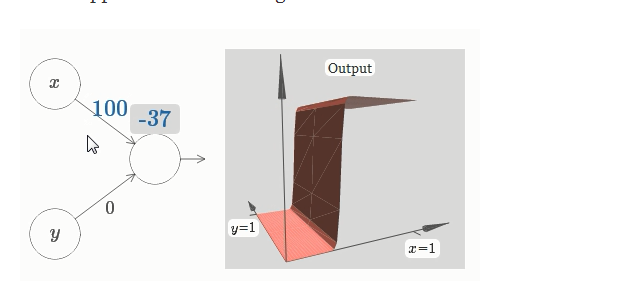
这里,我们有输入 $x$ 和 $y$,分别对应于权重 $w_1$ 和 $w_2$,以及一个神经元上的偏置 $b$。让我们把权重 $w_2$ 设置为 $0$,然后反复琢磨第一个权重 $w_1$ 和偏置 $b$,看看他们如何影响神经元的输出:
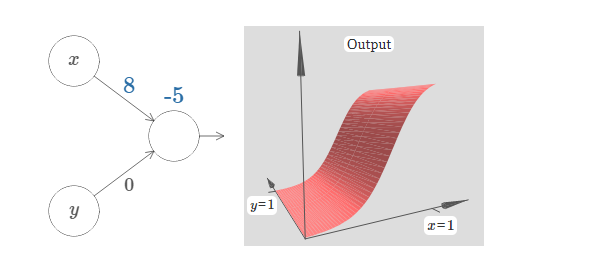
正如我们前面讨论的那样,随着输入权重变大,输出接近一个阶跃函数。不同的是,现在的阶跃函数是在三个维度。也如以前一样,我们可以通过改变偏置的位置来移动阶跃点的位置。阶跃点的实际位置是 $s_x \equiv -b / w_1$。
我们可以用我们刚刚构造的阶跃函数来计算一个三维的凹凸函数。为此,我们使用两个神经元,每个计算一个$x$ 方向的阶跃函数。然后我们用相应的权重 $h$ 和 $-h$ 将这两个阶跃函数混合,这里 $h$ 是凸起的期望高度。所有这些在下面图示中说明:
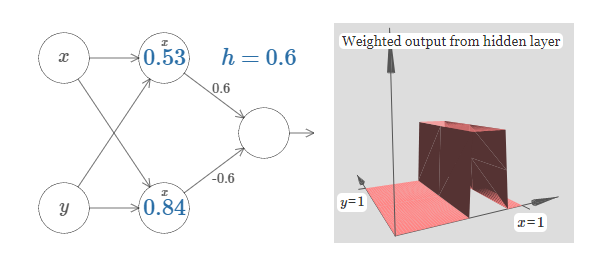
试着改变高度 $h$ 的值。观察它如何和网络中的权重关联。并看看它如何改变右边凹凸函数的高度。
我们已经解决了如何制造一个 $x$ 方向的凹凸函数。当然,我们可以很容易地制造一个$y$ 方向的凹凸函数,通过使用 $y$ 方向的两个阶跃函数。回想一下,我们通过使 $y$输入的权重变大,$x$ 输入的权重为 $0$ 来这样做。这是结果:
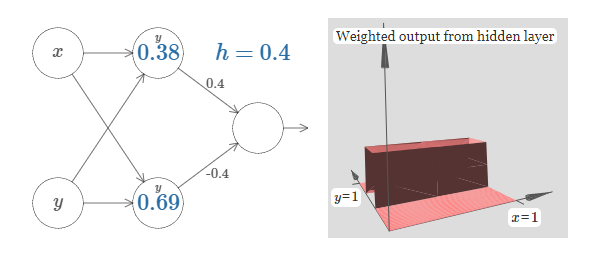
这看上去和前面的网络一模一样!唯一的明显改变的是在我们的隐藏神经元上现在标记有一个小的 $y$。那提醒我们它们在产生 $y$ 方向的阶跃函数,不是 $x$ 方向的,并且 $y$上输入的权重变得非常大,$x$ 上的输入为 $0$,而不是相反。正如前面,我决定不去明确显示它,以避免图形杂乱。
让我们考虑当我们叠加两个凹凸函数时会发生什么,一个沿 $x$ 方向,另一个沿 $y$ 方向,两者都有高度 $h$:
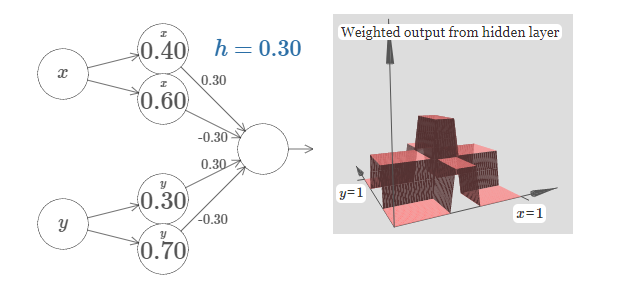
为了简化图形,我丢掉了权重为 $0$ 的连接。现在,我在隐藏神经元上留下了 $x$ 和 $y$的标记,来提醒你凹凸函数在哪个方向上被计算。后面我们甚至为丢掉这些标记,因为它们已经由输入变量说明了。试着改变参数 $h$。正如你能看到,这引起输出权重的变化,以及 $x$ 和 $y$ 上凹凸函数的高度。
我们构建的有点像是一个塔型函数,如果我们能构建这样的塔型函数,那么我们能使用它们来近似任意的函数。
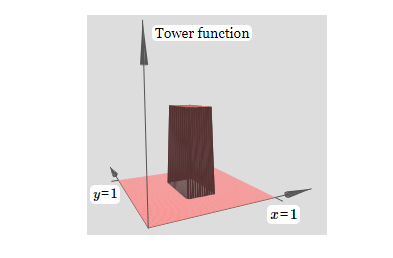
如果我们选择适当的阈值,比如,$3h/2$,这是高原的高度和中央塔的高度中间的值 ——我们可以把高原下降到零,并且依旧矗立着塔。
你能明白怎么做吗?试着用下面的网络做实验来解决。请注意, 我们现在正在绘制整个网络的输出,而不是只从隐藏层的加权输出。这意味着我们增加了一个偏置项到隐藏层的加权输出,并应用 S 型函数。 你能找到 $h$ 和 $b$ 的值,能产生一个塔型吗?这有点难,所以如果你想了一会儿还是困住,这是有两个提示:(1)为了让输出神经元显示正确的行为,我们需要输入的权重(所有 $h$ 或 $-h$)变得很大;(2)$b$ 的值决定了阈值的大小。
这是它看起来的样子,我们使用 $h = 10$:
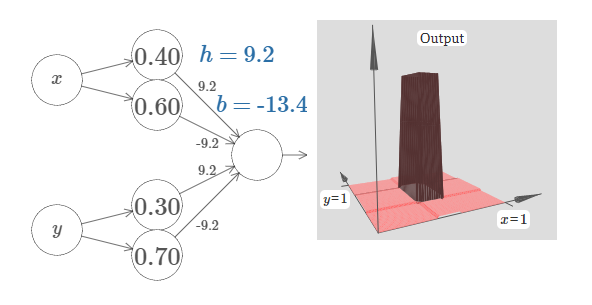
甚至对于这个相对适中的 $h$ 值,我们得到了一个相当好的塔型函数。当然,我们可以通过更进一步增加 $h$ 并保持偏置$b = -3h/2$ 来使它如我们所希望的那样。
让我们尝试将两个这样的网络组合在一起,来计算两个不同的塔型函数。为了使这两个子网络更清楚,我把它们放在如下所示的分开的方形区域:每个方块计算一个塔型函数,使用上面描述的技术。图上显示了第二个隐藏层的加权输出,即,它是一个加权组合的塔型函数。
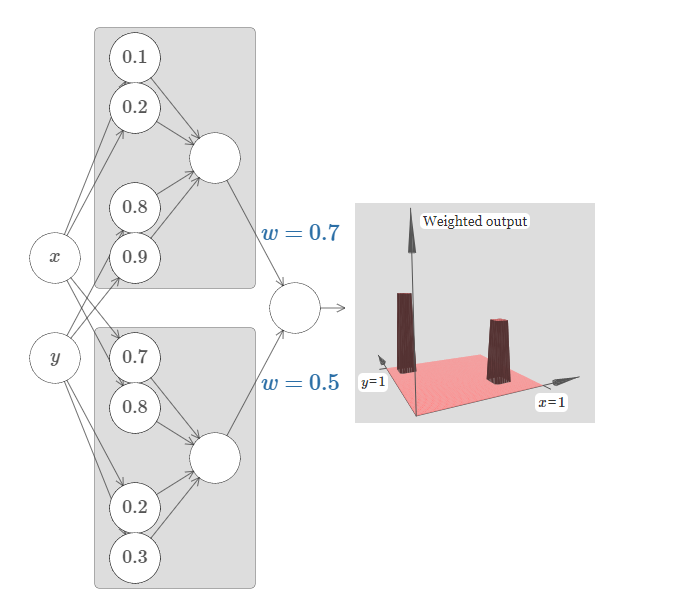
尤其你能看到通过修改最终层的权重能改变输出塔型的高度。同样的想法可以用在计算我们想要的任意多的塔型。我们也可以让它们变得任意细,任意高。通过使第二个隐藏层的加权输出为 $\sigma^{-1} \circ f$ 的近似,我们可以确保网络的输出可以是任意期望函数 $f$ 的近似。
让我们试试三个变量 $x_1, x_2, x_3$。下面的网络可以用来计算一个四维的塔型函数:
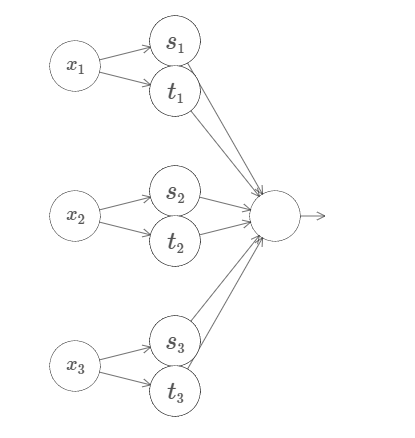
这里,$x_1, x_2, x_3$ 表示网络的输入。$s_1, t_1$ 等等是神经元的阶跃点~——~即,第一层中所有的权重是很大的,而偏置被设置为给出阶跃点 $s_1, t_1, s_2, \ldots$。第二层中的权重交替设置为 $+h, -h$,其中 $h$ 是一个非常大的数。输出偏置为 $-5h/2$。
这个网络计算这样一个函数,当三个条件满足时:$x_1$ 在 $s_1$ 和 $t_1$ 之间;$x_2$在$s_2$ 和 $t_2$ 之间;$x_3$ 在 $s_3$ 和 $t_3$ 之间,输出为 $1$。其它情况网络输出为 $0$。即,这个塔型在输入空间的一个小的区域输出为 $1$,其它情况输出 $0$。
通过组合许多个这样的网络我们能得到任意多的塔型,如此可近似一个任意的三元函数。对于 $m$ 维可用完全相同的思想。唯一需要改变的是将输出偏置设为 $(-m+1/2)h$,为了得到正确的夹在中间的行为来弄平高原。
好了,所以现在我们知道如何用神经网络来近似一个多元的实值函数。对于 $f(x_1,\ldots, x_m) \in R^n$ 的向量函数怎么样?当然,这样一个函数可以被视为 $n$ 个单独的实值函数: $f^1(x_1, \ldots, x_m)$, $f^2(x_1, \ldots, x_m)$ 等等。所以我们创建一个网络来近似 $f^1$,另一个来近似 $f^2$,如此等等。然后简单地把这些网络都组合起来。 所以这也很容易应付。
思考
我们已经看到如何使用具有两个隐藏层的网络来近似一个任意函数。你能否找到一个证明,证明只有一个隐藏层是可行的?作为一个提示,试着在只有两个输入变量的情况下工作,并证明:(a)可以得到一个不仅仅在 $x$ 和 $y$ 方向,而是在一个任意方向上的阶跃函数;(b)可以通过累加许多的源自(a)的结构,近似出一个塔型的函数,其形状是圆的,而不是方的;(c)使用这些圆形塔,可以近似一个任意函数。对于(c)可以使用本章稍后的一些思想。
S 型神经元的延伸
我们已经证明了由 S 型神经元构成的网络可以计算任何函数。回想下在一个 S 型神经元中,
输入$x_1, x_2, \ldots$ 导致输出 $\sigma(\sum_j w_j x_j + b)$,这里 $w_j$ 是权重,
$b$ 是偏置,而 $\sigma$ 是 S 型函数:
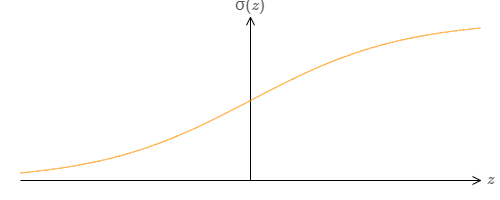
如果我们考虑一个不同类型的神经元,它使用其它激活函数,比如如下的 $s(z)$,会怎样?
更确切地说,我们假定如果神经元有输入 $x_1, x_2, \ldots$,权重 $w_1, w_2, \ldots$和偏置 $b$,那么输出为 $s(\sum_j w_j x_j + b)$。我们可以使用这个激活函数来得到一个阶跃函数,正如用 S 型函数做过的一样。
正如使用 S 型函数的时候,这导致激活函数收缩,并最终变成一个阶跃函数的很好的近似。试着改变偏置,然后你能看到我们可以设置我们想要的阶跃位置。所以我们能使用所有和前面相同的技巧来计算任何期望的函数。
$s(z)$ 需要什么样的性质来满足这样的结果呢?我们确实需要假定 $s(z)$ 在 $z\rightarrow -\infty$ 和 $z \rightarrow \infty$ 时是定义明确的。这两个界限是在我们的阶跃函数上取的两个值。我们也需要假定这两个界限彼此不同。如果它们不是这样,就没有阶跃,只是一个简单的平坦图形!但是如果激活函数 $s(z)$ 满足这些性质,基于这样一个激活函数的神经元可普遍用于计算。
问题
- 在本书前面我们遇到过其它类型的称为修正线性单元的神经元。解释为什么这样的神经元不满足刚刚给出的普遍性的条件。找到一个普遍性的证明,证明修正线性单元可普遍用于计算。
- 假设我们考虑线性神经元,即具有激活函数 $s(z) = z$ 的神经元。解释为什么线性神经元不满足刚刚给出的普遍性的条件。证明这样的神经元不能用于通用计算。
修补阶跃函数
目前为止,我们假定神经元可以准确生成阶跃函数。这是一个非常好的近似,但也仅仅是近似。实际上,会有一个很窄的故障窗口,如下图说明,在这里函数会表现得和阶跃函数非常不同。
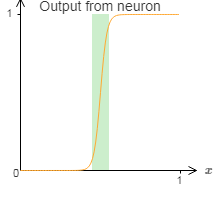
在这些故障窗口中我给出的普遍性的解释会失败。
现在,它不是一个很严重的故障。通过使得输入到神经元的权重为一个足够大的值,我们能把这些故障窗口变得任意小。当然,我们可以把故障窗口窄过我在上面显示的~——~窄得我们的眼睛都看不到。所以也许我们可以不用过于担心这个问题。
尽管如此,有一些方法解决问题是很好的。
实际上,这个问题很容易解决。让我们看看只有一个输入和一个输出的神经网络如何修补其计算函数。同样的想法也可以解决有更多输入和输出的问题。
特别地,假设我们想要我们的网络计算函数 $f$。和以前一样,我们试着设计我们的网络,使得隐藏神经元的加权输出是 $\sigma^{-1} \circ f(x)$:
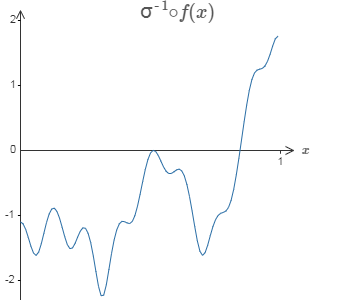
如果我们要使用前面描述的技术做到这一点,我们会使用隐藏神经元产生一系列的凹凸函数:
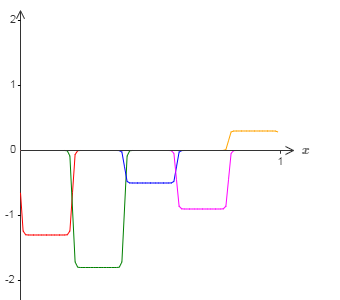
再说一下,我夸大了图上的故障窗口大小,好让它们更容易看到。很明显如果我们把所有这些凹凸函数加起来,我们最终会得到一个合理的 $\sigma^{-1} \circ f(x)$ 的近似,除了那些故障窗口。
假设我们使用一系列隐藏神经元来计算我们最初的目标函数的一半,即 $\sigma^{-1} \circ f(x) / 2$,而不是使用刚刚描述的近似。当然,这看上去就像上一个图像的缩小的版本:
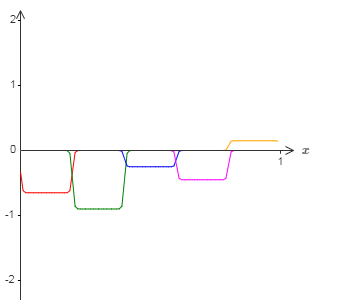
并且假设我们使用另一系列隐藏神经元来计算一个 $\sigma^{-1} \circ f(x) / 2$ 的近似,
但是用将凹凸图形偏移一半宽度:
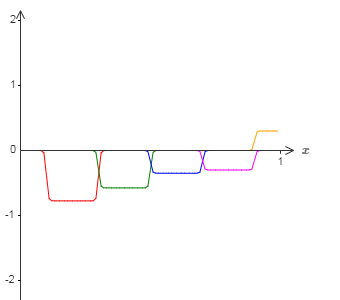
现在我们有两个不同的 $\sigma^{-1} \circ f(x) / 2$ 的近似。如果我们把这两个近似图形加起来,我们会得到一个 $\sigma^{-1} \circ f(x)$ 的整体近似。这个整体的近似仍然在一些小窗口的地方有故障。但是问题比以前要小很多。原因是在一个近似中的故障窗口的点,不会在另一个的故障窗口中。所以在这些窗口中,近似会有 $2$ 倍的因素更好。
我们甚至能通过加入大量的,用 $M$ 表示,重叠的近似 $\sigma^{-1} \circ f(x) / M$来做得更好。假设故障窗口已经足够窄了,其中的点只会在一个故障窗口中。并且假设我们使用一个 $M$ 足够大的重叠近似,结果会是一个非常好的整体近似。
结论
我们已经讨论的对于普遍性的解释当然不是如何使用神经网络计算的切实可行的用法!其更像是 NAND 门或者其它类似的普遍性证明。因为这个原因,我主要专注于让解释更清晰和易于理解,而不是过于挖掘细节。然而,你可以发现如果你能改进这个解释是个很有趣和有教益的练习。
尽管这个结果并不能直接用于解释网络,它还是是很重要的,因为它解开了是否使用一个神经网络可以计算任意特定函数的问题。对这个问题的答案总是“是”。所以需要问的正确问题,并不是是否任意函数可计算,而是计算函数的好的方法是什么。
我们建立的对于普遍性的解释只使用了两个隐藏层来计算一个任意的函数。而且,正如我们已经讨论过的,只使用单个的隐藏层来取得相同的结果是可能的。鉴于此,你可能想知道为什么我们会对深度网络感兴趣,即具有很多隐藏层的网络。我们不能简单地把这些网络用浅层的、单个隐藏层的网络替换吗?
尽管在原理上这是可能的,使用深度网络仍然有实际的原因。正如在第一章中表明过,深度网络有一个分级结构,使其尤其适用于学习分级的知识,这看上去可用于解决现实世界的问题。但是更具体地,当攻克诸如图像识别的问题,使用一个不仅能理解单独的像素,还能理解越来越复杂的概念的系统是有帮助的,这里说的复杂的概念,可以从图像的边缘信息到简单的几何形状,以及所有复杂的、多物体场景的方式。在后面的章节中,我们将看到在学习这样的分级知识时,深度网络要比浅层网络做得更好。总结一下: 普遍性告诉我们神经网络能计算任何函数;而实际经验依据提示深度网络最能适用于学习能够解决许多现实世界问题的函数。
参考文献
[1] Michael Nielsen. CHAPTER 4 A visual proof that neural nets can compute any function[DB/OL]. http://neuralnetworksanddeeplearning.com/chap4.html, 2018-06-29.
[2] Zhu Xiaohu. Zhang Freeman.Another Chinese Translation of Neural Networks and Deep Learning[DB/OL].https://github.com/zhanggyb/nndl/blob/master/chap4.tex, 2018-06-29.

