Conditional Image Synthesis with Auxiliary Classifier GANs
Conditional Image Synthesis With Auxiliary Classifier GANs
Augustus Odena, Christopher Olah, Jonathon Shlens
(Submitted on 30 Oct 2016 (v1), last revised 20 Jul 2017 (this version, v4))
Synthesizing high resolution photorealistic images has been a long-standing challenge in machine learning. In this paper we introduce new methods for the improved training of generative adversarial networks (GANs) for image synthesis. We construct a variant of GANs employing label conditioning that results in 128x128 resolution image samples exhibiting global coherence. We expand on previous work for image quality assessment to provide two new analyses for assessing the discriminability and diversity of samples from class-conditional image synthesis models. These analyses demonstrate that high resolution samples provide class information not present in low resolution samples. Across 1000 ImageNet classes, 128x128 samples are more than twice as discriminable as artificially resized 32x32 samples. In addition, 84.7% of the classes have samples exhibiting diversity comparable to real ImageNet data.
合成高分辨率照片级真实感图像一直是机器学习中的长期挑战。 在本文中,我们介绍了用于图像合成的改进生成对抗网络(GAN)训练的新方法。 我们构建了采用标签调节的GAN变体,其产生128x128分辨率的图像样本,表现出全局一致性。 我们扩展了以前的图像质量评估工作,为评估类条件图像合成模型中样本的可辨性和多样性提供了两个新的分析。 这些分析表明,高分辨率样品提供了低分辨率样品中不存在的类信息。 在1000个ImageNet类中,128x128样本的差异是人工调整大小的32x32样本的两倍多。 此外,84.7%的类别的样本具有与真实ImageNet数据相当的多样性。
Subjects: Machine Learning (stat.ML); Computer Vision and Pattern Recognition (cs.CV)
Cite as: arXiv:1610.09585 [stat.ML]
(or arXiv:1610.09585v4 [stat.ML] for this version)
以下内容参考谷歌翻译
摘要
在本文中,我们介绍了用于图像合成的改进生成对抗网络(GAN)训练的新方法。我们构建了采用标签调节的GAN变体,其产生了展示全局一致性的 128 × 128 分辨率图像样本。我们扩展了以前的图像质量评估工作,为评估类条件图像合成模型中样本的可辨性和多样性提供了两个新的分析。这些分析表明,高分辨率样品提供了低分辨率样品中不存在的类信息。在1000个ImageNet类中,128 × 128 个样本比人工调整大小的 32 × 32 可辨别两倍多样本。此外,84.7%的类别的样本具有与真实ImageNet数据相当的多样性。
介绍
表征自然图像的结构是一项丰富的研究工作。 自然图像遵循内在的不变性,并展示历史上难以量化的多尺度统计结构(Simoncelli&Olshausen, 2001 )。 机器学习的最新进展提供了显着改善图像模型质量的机会。 改进的图像模型推进了图像去噪(Ballé等, 2015 ) ,压缩(Toderici等, 2016 ) ,绘画(van den Oord等, 2016a )和超级图像去噪方面的最新技术。 - 分辨率(Ledig等, 2016 ) 。 更好的自然图像模型也提高了半监督学习任务的性能(Kingma等, 2014 ; Springenberg, 2015 ; Odena, 2016 ; Salimans等, 2016 )和强化学习问题(Blundell等, 2016 ) 。
理解自然图像统计的一种方法是构建从头合成图像的系统。 有几种有前景的方法可用于构建图像合成模型。 变分自动编码器(VAE)最大化训练数据对数似然的变化下界(Kingma&Welling, 2013 ; Rezende等, 2014 ) 。 VAE很容易训练,但引入了关于近似后验分布的潜在限制性假设(但参见(Rezende&Mohamed, 2015 ; Kingma等, 2016 ) )。 自回归模型省去了潜在变量并直接模拟了像素上的条件分布(van den Oord et al。, 2016a , b ) 。 这些模型产生令人信服的样品,但样品成本高,并且不提供潜在的表示。 可逆密度估计器使用一系列限制为可逆的参数化函数直接转换潜在变量(Dinh等, 2016 ) 。 该技术允许精确的对数似然计算和精确推理,但是可逆性约束是限制性的。
生成性对抗网络(GAN)提供了一种独特且有前景的方法,侧重于用于训练图像合成模型的游戏理论公式(Goodfellow等, 2014 ) 。 最近的研究表明,GAN可以在具有低可变性和低分辨率的数据集上生成令人信服的图像样本(Denton等, 2015 ; Radford等, 2015 ) 。 然而,GAN努力生成全局一致的高分辨率样本 - 特别是来自具有高可变性的数据集。 此外,对GAN的理论理解是一个持续的研究课题(Uehara等, 2016 ; Mohamed和Lakshminarayanan, 2016 ) 。

图1:来自在ImageNet数据集上训练的AC-GAN的5个等级的 128×128 分辨率样本。请注意,已选择显示的类以突出显示模型的成功,并且不具有代表性。 来自所有ImageNet类的样本将在本文后面链接。
在这项工作中,我们证明了向GAN潜在空间添加更多结构以及专门的成本函数可以获得更高质量的样本。 我们展示了来自ImageNet数据集各类的 128×128 像素样本(Russakovsky等, 2015 ) ,增强了全局一致性(图1 )。 重要的是,我们定量地证明我们的高分辨率样品不仅仅是对低分辨率样品的天真抑制。 特别是,将 128×128 样本下采样到 32×32 会导致视觉可辨性降低50%。 我们还引入了一个新的度量标准,用于评估图像样本的可变性,并使用该度量标准来证明我们的合成图像显示出与大部分(84.7%)ImageNet类的训练数据相当的多样性。 更详细地说,这项工作是第一个:
- 以128x128空间分辨率(或任何空间分辨率 - 参见第3节)演示所有1000个ImageNet类的图像合成模型。
- 测量图像合成模型实际使用其输出分辨率的程度(第4.1节)。
- 使用快速,易于计算的度量来衡量GAN中的感知变异性和“崩溃”行为(第4.2节)。
- 需要注意的是,大量的类使GAN的ImageNet合成变得困难,并提供了明确的解决方案(第4.6节)。
- 通过实验证明,感性表现良好的GAN不是记忆少数例子的那些(第4.3节)。
- 在不使用任何技术(Salimans等, 2016 ) (第4.4节)的情况下,在CIFAR-10上进行训练时,在初始得分指标上实现最先进的技术水平 。
背景
生成对抗网络(GAN)由两个彼此对立训练的神经网络组成。生成器 G 将随机噪声矢量 z 作为输入,并输出图像 $X_{fake}=G(z)$ 。鉴别器 D 接收来自发生器的训练图像或合成图像作为输入,并输出概率分布 $P(S|X)=D(X)$ 可能的图像源。训练鉴别器以最大化它分配给正确来源的对数似然性:
训练发生器以使等式1中的第二项最小化。
可以使用辅助信息来扩充基本GAN框架。一种策略是为生成器和鉴别器提供类标签,以生成类条件样本(Mirza&Osindero,2014)。类条件合成可以显着提高生成样本的质量(van den Oord等,2016b)。更丰富的辅助信息(如图像标题和边界框定位)可以进一步提高样本质量(Reed等,2016a,b)。
不是将类别信息馈送到鉴别器,而是可以使鉴别器重建类别信息。这是通过修改鉴别器以包含辅助解码器网络来完成的1 输出训练数据的类别标签(Odena,2016 ; Salimans等,2016) 或生成样本的潜在变量的子集(Chen等,2016)。已知迫使模型执行附加任务以改善原始任务的性能(例如(Sutskever等人,2014 ; Szegedy等人,2014 ; Ramsundar等人,2016))。此外,辅助解码器可以利用预先训练的鉴别器(例如图像分类器)来进一步改善合成图像(Nguyen等,2016)。在这些考虑因素的推动下,我们引入了一种模型,该模型结合了利用类别信息的两种策略。也就是说,下面提出的模型是类条件的,但是具有辅助解码器,其负责重建类标签。
AC-GANs
我们提出了GAN架构的变体,我们将其称为辅助分类器GAN(或AC-GAN)。在AC-GAN中,除了噪声
z 之外,每个生成的样本都具有相应的类标签 $c \sim p_{c}$。鉴别器给出了源上的概率分布和类标签上的概率分布 $P(S|X), P(C|X)=D(X)$。目标函数有两个部分:正确源的对数似然,$L_s$ 和正确类的对数似然,$L_c$。
训练 D 使 $L_s + L_c$ 最大化,同时训练 G 使 $L_c - L_s$ 最大化。AC-GAN学习 z 的表示,其独立于类标签(例如(Kingma等, 2014 ) )。
在结构上,该模型与现有模型没有太大差别。 然而,对标准GAN配方的这种修改产生了优异的结果并且似乎稳定了训练。 此外,我们认为AC-GAN模型只是这项工作的技术贡献的一部分,以及我们提出的测量模型利用其给定输出分辨率的程度的方法,测量样品的感知变异性的方法。该模型,以及图像生成模型的全面实验分析,可从所有1000个ImageNet类中创建 128×128 个样本。
早期的实验证明,在固定模型的同时增加训练课程的数量会降低模型输出的质量。 AC-GAN 模型的结构允许按类别将大数据集分成子集,并为每个子集训练生成器和鉴别器。 所有ImageNet实验都是使用100个AC-GAN的集合进行的,每个AC-GAN都采用10级分割进行训练。
结果
我们在ImageNet数据集上训练了几个AC-GAN模型(Russakovsky等, 2015 ) 。 从广义上讲,发生器 G 的结构是一系列“反卷积”层,它们将噪声 z 和类 c 转换为图像(Odena等, 2016 ) 。 我们训练两种模型架构的变体,用于生成 128×128 和 64×64 空间分辨率的图像。 鉴别器 D 是具有Leaky ReLU非线性的深度卷积神经网络(Maas等人, 2013 ) 。 如前所述,我们发现减少所有1000类ImageNet引入的可变性可显着提高培训质量。 我们培训了100个AC-GAN型号 - 每个型号只有10个类别 - 用于50000个100个小批量的批量生产。
由于概率标准的多样性(Theis等, 2015 )以及缺乏感知上有意义的图像相似性度量,评估图像合成模型的质量具有挑战性。 尽管如此,在后面的部分中,我们尝试通过构建图像样本可辨性和多样性的若干临时措施来测量AC-GAN的质量。 我们希望这项工作可以提供可用于辅助图像合成模型的培训和后续开发的量化测量。
生成高分辨率图像可提高可辨别性

图2:生成高分辨率图像可提高可辨性。 上图:来自斑马类的训练数据和合成图像调整为较低的空间分辨率(如上所示),然后人工调整大小为原始分辨率(红线和黑线为 128×128 ;蓝线为 64×64 )。 初始精度显示在相应图像下方。 左下:对于 64×64 和 128×128 模型的训练数据和图像样本,不同空间分辨率的精度总结。 误差棒测量10个图像子集的标准偏差。 虚线突出了模型输出空间分辨率的精度。 训练数据(剪裁)在分辨率分别为32,64,128和256时分别达到24%,54%,81%和81%的精度。 右下:比较 128×128 和 32×32 空间分辨率(分别为 x 和 y 轴)的精度分数。 每个点代表一个ImageNet类。 84.4%的班级低于平等线。 绿点对应斑马类。 我们还将 128×128 和 64×64 图像人工调整为 256×256 ,作为一种健全性检查,以证明简单地增加像素数量不会增加可辨别性。
构建类条件图像合成模型需要测量合成图像看起来属于预期类的程度。 特别是,我们想知道高分辨率样本不仅仅是对低分辨率样本进行天真的调整。 考虑一个简单的实验:假装存在一个合成 32x32 图像的模型。 通过执行双线性插值,可以平凡地增加合成图像的分辨率。 这将产生更高分辨率的图像,但是这些图像将仅是不可辨别的低分辨率图像的模糊版本。 因此,图像合成模型的目标不仅仅是产生高分辨率图像,而是产生比低分辨率图像更易辨别的高分辨率图像。
为了测量可辨性,我们将合成图像提供给预先训练的Inception网络(Szegedy等, 2015 )并报告Inception网络为其分配正确标签的样本部分。 我们计算了一系列真实和合成图像的精度测量值,这些图像的空间分辨率通过双线性插值人为地降低(图2 ,上图)。 请注意,随着空间分辨率的降低,精度会降低 - 表明生成的图像包含较少的类信息(图2 ,顶部面板下方的分数)。 我们在所有1000个ImageNet类中总结了这一发现,包括ImageNet训练数据(黑色),图2中的 128×128 分辨率AC-GAN(红色)和 64x64分辨率AC-GAN(蓝色)(左下图)。 黑色曲线(剪裁)提供了真实图像可辨性的上限。
该分析的目的是表明合成更高分辨率的图像会导致可识别性增加。 128×128 模型的精度达到10.1% ±2.0%,而7.0%±2.0%,样品尺寸调整为 64x64和5.0% ±2.0%,样品尺寸调整为 32x32 。 换句话说,将AC-GAN的输出缩小到 32x32 和 64x64 分别将视觉辨别率降低50%和38%。 此外,84.4%的ImageNet类在 128×128 处具有比在 32x32 处更高的精度(图2 ,左下)。
我们对训练为 64x64空间分辨率的AC-GAN进行了相同的分析。 与 128×128 AC-GAN模型相比,该模型的可辨识性较差。 来自 64x64模型平台的精度在 64x64空间分辨率下与先前的结果一致。 最后, 64x64分辨率模型在64空间分辨率下比 128×128 模型具有更小的可辨识性。
据我们所知,这项工作是第一次尝试测量图像合成模型“利用其给定的输出分辨率”的程度,实际上是第一个完全考虑该问题的工作。 我们认为这是一个重要的贡献,与提出一个合成来自所有1000个ImageNet类的图像的模型相同。 我们注意到,所提出的方法可以应用于任何可以构建“样本质量”度量的图像合成模型。 事实上,这种方法(广泛定义)可以应用于任何类型的合成模型,只要有一个容易计算的样本质量概念和一些“降低分辨率”的方法。 特别是,我们希望可以对音频合成进行类似的处理。
测量生成图像的多样性
如果图像合成模型仅输出一个图像,则它不是很有趣。实际上,众所周知的GAN故障模式是生成器将崩溃并输出单个原型,最大限度地愚弄鉴别器(Goodfellow等, 2014 ; Salimans等, 2016 ) 。 如果每个类只输出一个图像,则图像的类条件模型不是很有趣。 初始精度无法测量模型是否已折叠。 简单地记住每个ImageNet类中的一个示例的模型可以很好地通过该度量。 因此,我们寻求补充度量以明确地评估由AC-GAN生成的样本的类内感知多样性。
存在几种通过尝试预测人类感知相似性判断来定量评估图像相似性的方法。 其中最成功的是多尺度结构相似性(MS-SSIM) (Wang等, 2004b ; Ma等, 2016 )。 MS-SSIM是一种充分表征的感知相似性度量的多尺度变体,其试图折扣对人类感知不重要的图像的方面(Wang等, 2004a ) 。 MS-SSIM值介于0.0和1.0之间; 较高的MS-SSIM值对应于感知上更相似的图像。
作为图像多样性的代理,我们测量给定类别中100个随机选择的图像对之间的MS-SSIM分数。 来自具有较高多样性的类别的样本导致较低的平均MS-SSIM分数(图3 ,左栏); 来自具有较低多样性的类别的样本具有较高的平均MS-SSIM分数(图3 ,右栏)。 来自ImageNet训练数据的训练图像包含各类的各种平均MS-SSIM分数,表明ImageNet类中图像多样性的可变性(图4 ,x轴)。 注意,对于训练数据,最高平均MS-SSIM得分(表示最小可变性)是0.25。
我们计算AC-GAN模型生成的所有1000个ImageNet类的平均MS-SSIM得分。 我们在训练期间跟踪此值以确定生成器是否已折叠(图5 ,红色曲线)。 我们还使用该度量来在训练完成后将训练图像的多样性与来自GAN模型的样本进行比较。 图4绘制了按类别划分的图像样本和训练数据的平均MS-SSIM值。 蓝线是平等的线。 在1000个类中,我们发现847的平均样本MS-SSIM分数低于训练数据的最大MS-SSIM。 换句话说,84.7%的类具有超过ImageNet训练数据中的最小变量类的样本可变性。
有两个与MS-SSIM指标相关的点以及我们对它的使用值得特别注意。 第一点是我们“滥用”指标:它最初用于使用参考“原始图像”来测量图像压缩算法的质量。 我们改为在两个可能不相关的图像上使用它。 我们认为这是可以接受的,原因如下:第一:视觉检查似乎表明该指标是有意义的 - 具有较高MS-SSIM的配对似乎与具有较低MS-SSIM的配对更相似。 第二:我们将比较限制为使用相同类标签合成的图像。 这限制了MS-SSIM的使用,使其更类似于通常使用的情况(哪个图像作为参考并不重要)。 第三:对于我们的用例,度量标准不是“饱和的”。 如果大多数分数大约为0,那么我们会更关注MS-SSIM的适用性。 最后:培训数据通过该指标实现更多可变性(如预期的那样)这一事实证明该指标正在按预期工作。
第二点是MS-SSIM度量不是作为像素空间中发生器分布的熵的代理,而是作为输出的感知多样性的度量。 生成器输出分布的熵难以计算,成对的MS-SSIM分数不是一个好的代理。 即使它很容易计算,我们仍然认为对感知多样性进行单独测量仍然是有用的。 要了解原因,请考虑生成器熵对对比度的微小变化以及输出的语义内容的变化敏感。 在许多应用中,我们并不关心这种对熵的贡献,并且考虑试图忽略我们认为“在感知上毫无意义”的图像的变化的措施是有用的,因此使用MS-SSIM。
生成的图像既多样又可辨别
我们已经提出了量化指标,证明AC-GAN样本可能是多样的和可辨别的,但我们尚未研究这些指标如何相互作用。 图6显示了所有类别的初始准确度和MS-SSIM分数的联合分布。 初始精度和MS-SSIM是反相关的。 相比之下,Inception-v3模型在所有1000个类别中平均达到78.8%的准确度(Szegedy等, 2015 ) 。 AC-GAN样品的一小部分达到这种精度水平。 这表明未来图像合成模型的机会。
这些结果表明,降低模式的GAN最有可能产生低质量的图像。 这与关于GAN的流行假设形成鲜明对比,GAN是以可变性为代价获得高样本质量的。 我们希望这些发现有助于进一步研究GAN与其他图像合成模型之间不同样本质量的原因。
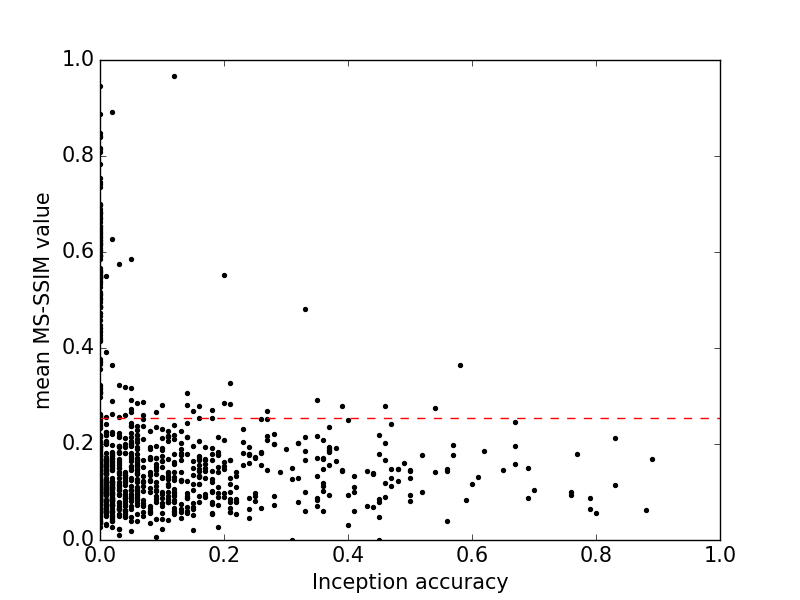
图6:所有1000个ImageNet类的初始精度与MS-SSIM($r^2=-0.16$)。 每个数据点代表一个类的样本的平均MS-SSIM值。 如图4所示,红线标记所有ImageNet类的最大MS-SSIM值(用于训练数据)。 来自AC-GAN模型的样本不会以可辨别性为代价实现可变性。
与先前结果的比较
在对数似然性方面报告了在ImageNet上训练的图像合成模型的先前定量结果(van den Oord等, 2016a , b ) 。 对数似然是一种粗略且可能不准确的样本质量测量(Theis等, 2015 )。 相反,我们使用较低的空间分辨率(32x32)与CIFAR-10上先前的最新结果进行比较。 按照(Salimans等, 2016 )中的程序 ,我们计算初始分数 3 对于分辨率为(32x32)的AC-GAN的50000个样本,随机分成10组。 我们还计算了25000个额外样本的初始分数,随机分成5组。 我们根据第一个分数选择最佳模型并报告第二个分数。 在27个超参数配置中执行网格搜索,与现有技术8.09 ± 0.07相比,我们能够获得8.25 ± 0.07的分数(Salimans等, 2016 ) 。 此外,我们在不采用该工作中引入的任何新技术(即虚拟批量标准化,小批量区分和标签平滑)的情况下实现了这一点。
这提供了额外的证据,即AC-GAN即使没有类别分裂的好处也是有效的。 参见图7 ,对AC-GAN样品和模型样品进行定性比较(Salimans等, 2016 ) 。

图7:从ImageNet数据集生成的样本。 (左)从模型中生成的样本(Salimans等, 2016 ) 。 (右)从AC-GAN生成的随机选择的样本。 AC-GAN样品在早期模型的样品中缺乏全局一致性。
搜索过度拟合的证据
必须研究的一种可能性是AC-GAN在训练数据上过度拟合。 作为网络不记忆训练数据的第一次检查,我们在像素空间中通过L1距离测量的训练数据中识别图像样本的最近邻居(图8 )。 来自训练数据的最近邻居不与相应的样本相似。 这提供了AC-GAN不仅仅是记忆训练数据的证据。

图8:最近邻分析。 (顶部)来自单个ImageNet类的样本。 (下)每个样本的训练数据中对应的最近邻居(L1距离)。
用于理解模型中过度拟合程度的更复杂方法是通过插值来探索该模型的潜在空间。 在过拟合模型中,可以观察到插值图像中的离散跃迁和潜在空间中与有意义的图像不对应的区域(Bengio等人, 2012 ; Radford等人, 2015 ; Dinh等人, 2016 ) 。 图9 (顶部)突出显示了几个图像样本之间潜在空间中的插值。 值得注意的是,发生器了解到某些尺寸组合对应于语义上有意义的特征(例如拱的大小,鸟喙的长度),并且在潜在空间中没有离散的过渡或“洞”。
探索AC-GAN潜在空间的第二种方法是利用模型的结构。 AC-GAN将其表示分解为类信息和类独立的潜在表示z。 采用z固定但是改变类标签对AC-GAN进行采样对应于在多个类中生成具有相同“风格”的样本(Kingma等, 2014 ) 。 图9 (底部)显示了8个鸟类的样本。 同一行的元素具有相同的z。 尽管每列的类都在变化,但全局结构的元素(例如位置,布局,背景)仍然保留,表明AC-GAN可以表示某些类型的“组合性”。

图9:(顶部)所选ImageNet类的潜在空间插值。 最左侧和右侧列显示三对图像样本 - 每对来自不同的类。 中间列突出显示这三对图像之间潜在空间中的线性插值。 (底部)与类无关的信息包含关于合成图像的全局结构。 每列是一个独特的鸟类,而每一行对应一个固定的潜在代码z。
测量类别分裂对图像样本质量的影响
类条件图像合成提供了基于图像标签划分数据集的机会。 在我们的最终模型中,我们将1000个ImageNet类划分为100个AC-GAN模型。 在本节中,我们将描述实验,这些实验强调了减少用于训练AC-GAN的类别的多样性的好处。 我们采用了标签的排序,并将其分为10个连续的组。这个排序可以在下面的部分中看到,我们在这里显示来自所有1000个类的样本。 分裂绩效讨论的两个方面:每个分裂的类数和分裂内多样性。我们发现在更多类别上训练固定模型会损害模型生成引人注目的样本的能力(图10 )。通过为模型提供更多参数,可以提高较大分割的性能。但是,使用小分割不足以实现良好的性能。我们无法训练GAN (Goodfellow et al。,2014),即使对于1的分割大小也能可靠地收敛。这就提出了一个问题,即在不同的类别上训练模型是否比在类似的集合上训练更容易课程:我们无法找到确凿的证据表明分组中的课程选择会显着影响样本质量。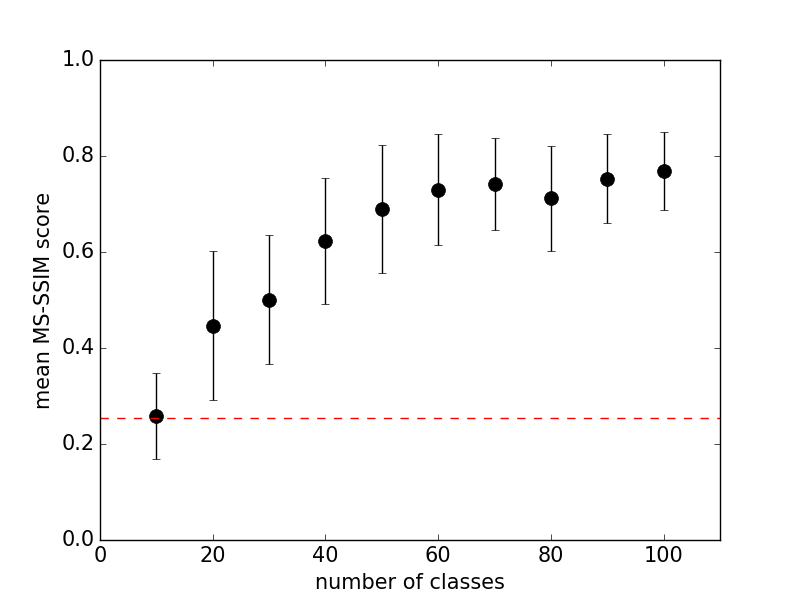
图10:针对训练期间使用的ImageNet类的数量绘制的10个ImageNet类的平均成对MS-SSIM值。我们使用10到100之间的值来修复除训练课程数量之外的所有内容。我们仅报告前10个课程的MS-SSIM值以保持分数可比。随着班级计数的增加,MS-SSIM迅速超过0.25(红线)。使用每个模型的相同数量的训练步骤,使用每个类计数9个随机重启来计算这些分数。由于我们观察到生成器不能从崩溃阶段恢复,因此在这种情况下使用固定数量的训练步骤似乎是合理的。
我们没有关于是什么原因导致这种对班级计数的敏感性的假设,这种假设在实验上得到了很好的支持。我们只能注意到,由于类计数增加时发生的故障情况是“生成器崩溃”,似乎有理由解决“生成器崩溃”的一般方法也可以解决这种敏感问题。
来自所有1000个ImageNet类的样本
我们还从这里托管的1000个ImageNet类中的每一个中生成10个样本。据我们所知,没有其他图像合成工作包括类似的分析。
讨论
这项工作引入了AC-GAN架构,并证明了AC-GAN可以生成全局一致的ImageNet样本。我们为图像可辨性提供了一种新的定量度量,作为空间分辨率的函数。使用此度量标准,我们证明了我们的样本比生成较低分辨率图像并执行简单调整大小操作的模型更具可辨识性。我们还分析了样本在训练数据方面的多样性,并提供了一些证据,证明大多数类别的图像样本在多样性方面与ImageNet数据具有可比性。
在这项工作的基础上存在几个方向。需要做很多工作来改善 128x128 分辨率模型的视觉可辨性。虽然一些合成图像类别具有较高的初始精度,但模型的平均初始精度(10.1 %± 2.0 %)仍远低于实际训练数据的81%。解决这个问题的一个直接机会是用预训练模型增强鉴别器以执行额外的监督任务(例如图像分割,(Ronneberger等,2015))。
提高GAN培训的可靠性是一个持续的研究课题。只有84.7%的ImageNet类表现出与真实训练数据相当的多样性。通过在100个AC-GAN模型中划分1000个ImageNet类,极大地帮助了训练稳定性。构建可以从所有1000个类生成样本的单个模型将是向前迈出的重要一步。
图像合成模型为执行半监督学习提供了独特的机会:这些模型构建了丰富的先前自然图像统计数据,可以通过分类器来利用这些统计数据来改进对少数标签存在的数据集的预测。当标签对于给定的训练图像不可用时,AC-GAN模型可以通过忽略由类标签引起的损失的分量来执行半监督学习。有趣的是,先前的工作表明,实现良好的样本质量可能与半监督学习的成功无关(Salimans等,2016)。

