N-gram features
词袋模型不考虑词序的问题,若将词序信息添加进去又会造成过高的计算代价。文章取而代之使用bag of n-gram来将词序信息引入:比如 我来到颐和园参观,相应的bigram特征为:我来 来到 到颐 颐和 和园 园参 参观相应的trigram特征为:我来到 来到颐 到颐和 颐和园 和园参 园参观并使用哈希算法高效的存储n-gram信息。
| 标题 | 说明 | 附加 |
|---|---|---|
| Bag of Tricks for Efficient Text Classification | 原始论文 | 201607 |
| 脸书论文翻译《Bag of Tricks for Efficient Text Classification》 | 论文翻译 | 201707 |
| Paper Reading Bag of Tricks for Efficient Text Classification | 论文理解 | 20160710 |
| 论文引介 Bag of Tricks for Efficient Text Classification | 论文 | 201607 |
| 如何评价Word2Vec作者提出的fastText算法?深度学习是否在文本分类等简单任务上没有优势? | 论文浅析和评价 | |
| fastText,智慧与美貌并重的文本分类及向量化工具 | 模型解析 | 20190901 |
总结一下:对简单的任务来说,用简单的网络结构进行处理基本就够了,但是对比较复杂的任务,还是依然需要更复杂的网络结构来学习sentence representation的。
另外,fastText文中还提到的两个tricks分别是:
- hierarchical softmax类别数较多时,通过构建一个霍夫曼编码树来加速
softmax layer的计算,和之前word2vec中的trick相同 - N-gram features只用unigram的话会丢掉word order信息,所以通过加入N-gram features进行补充;用hashing来减少N-gram的存储。
Bag of Tricks for Efficient Text Classification
Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov
(Submitted on 6 Jul 2016 (v1), last revised 9 Aug 2016 (this version, v3))
This paper explores a simple and efficient baseline for text classification. Our experiments show that our fast text classifier fastText is often on par with deep learning classifiers in terms of accuracy, and many orders of magnitude faster for training and evaluation. We can train fastText on more than one billion words in less than ten minutes using a standard multicore~CPU, and classify half a million sentences among~312K classes in less than a minute.本文探讨了一种简单有效的文本分类基线。我们的实验表明,我们的快速文本分类器 fastText在准确性方面通常与深度学习分类器相当,并且在训练和评估方面更快几个数量级。我们可以 使用标准的多核CPU在不到10分钟的时间内对超过10亿个单词进行fastText训练 ,并在不到一分钟的时间内对312K类中的50万个句子进行分类。
Subjects: Computation and Language (cs.CL)
Cite as: arXiv:1607.01759 [cs.CL]
(or arXiv:1607.01759v3 [cs.CL] for this version)
学习该论文的写作方法
论文目录
论文内容

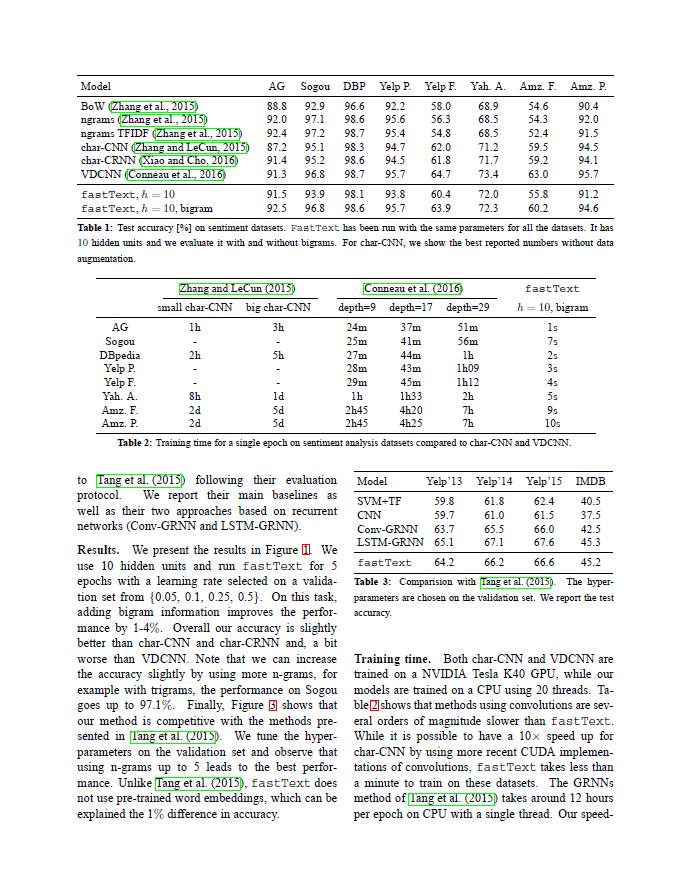
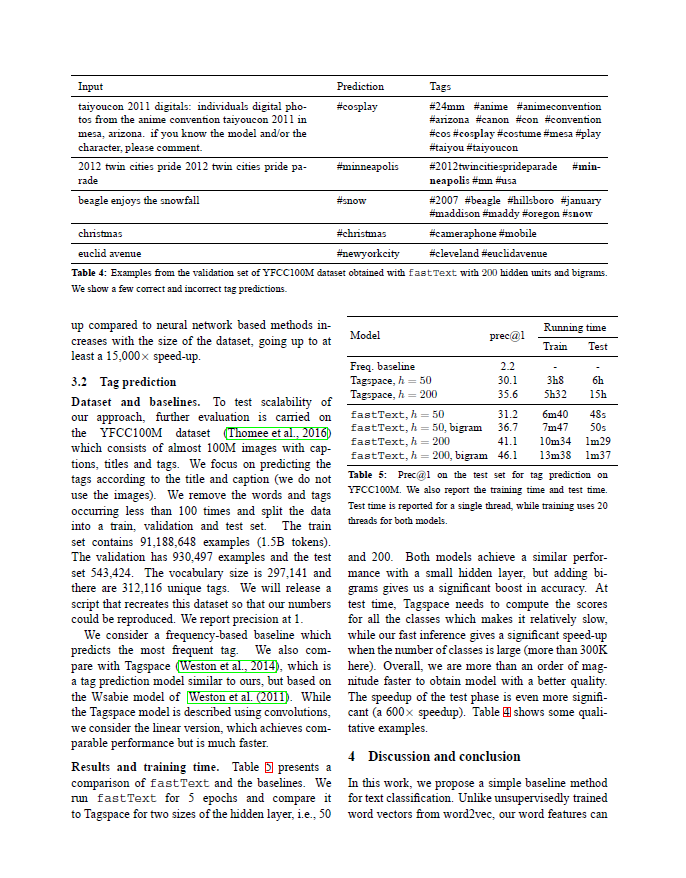

imdb_fasttext 与不使用 N-gram features 相比
红色线是不使用 N-gram features,绿色线是使用,显然使用 N-gram features 有效果