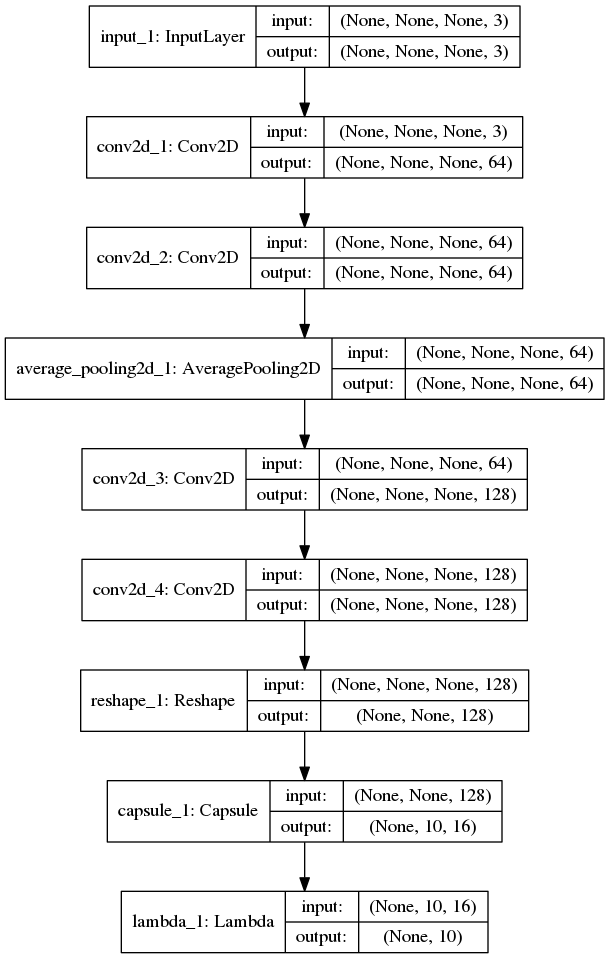
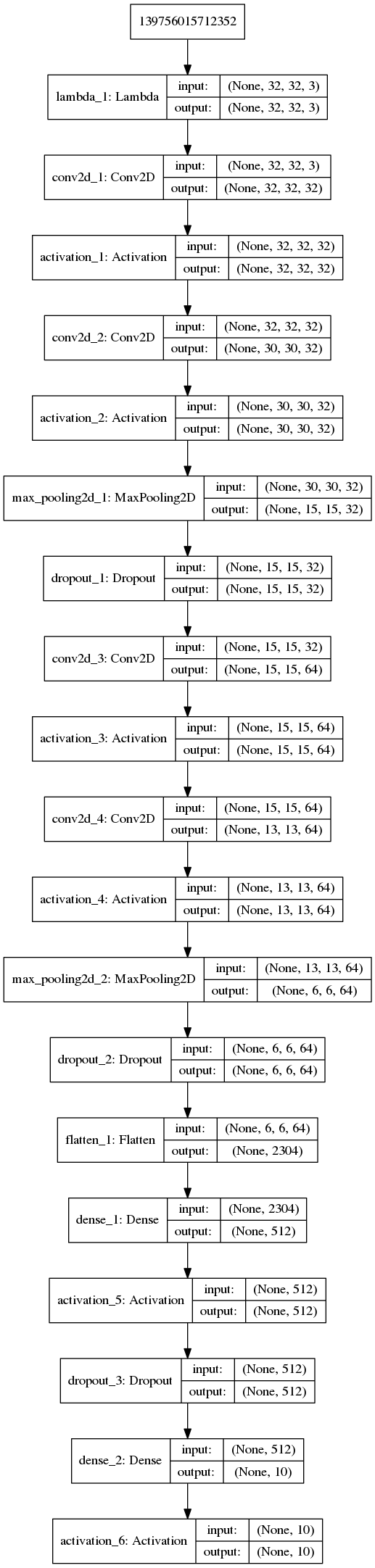
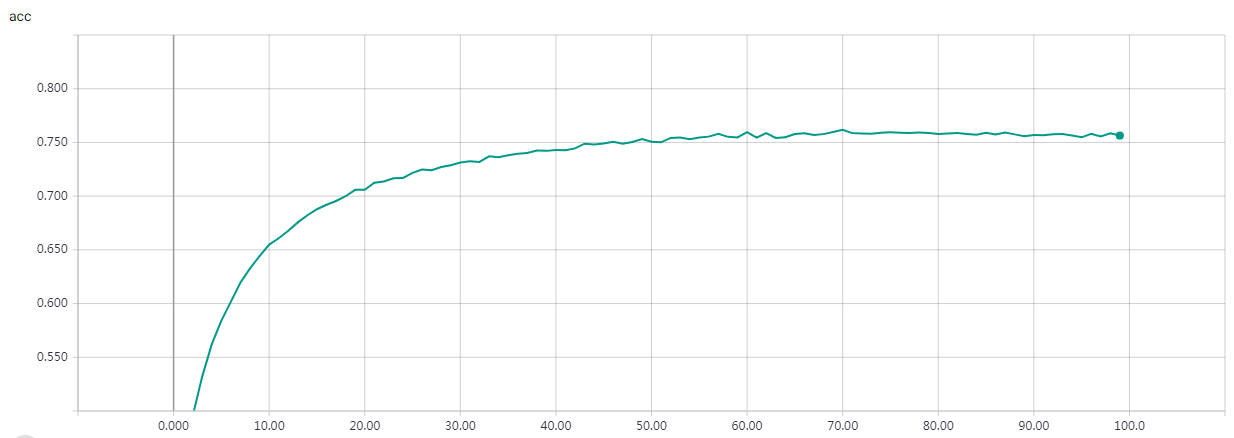
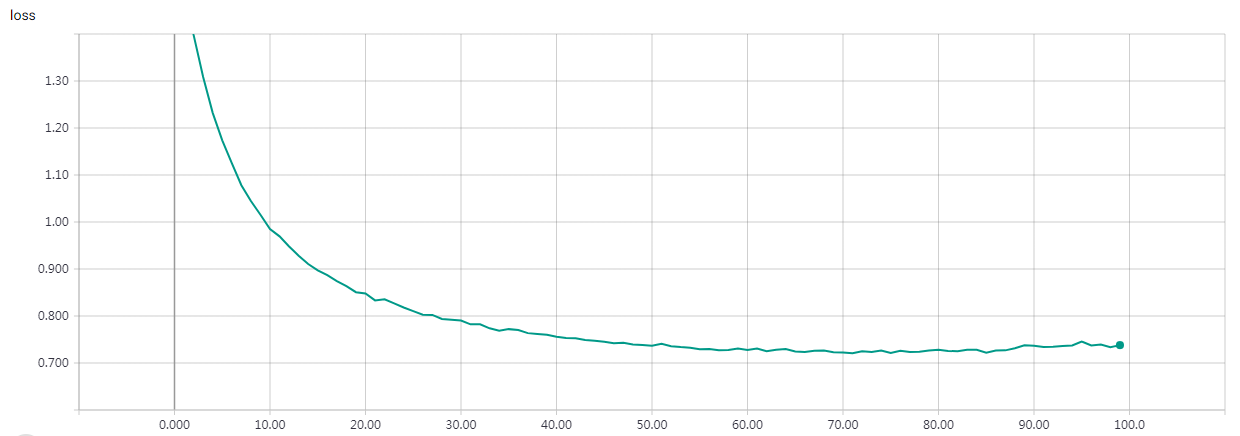
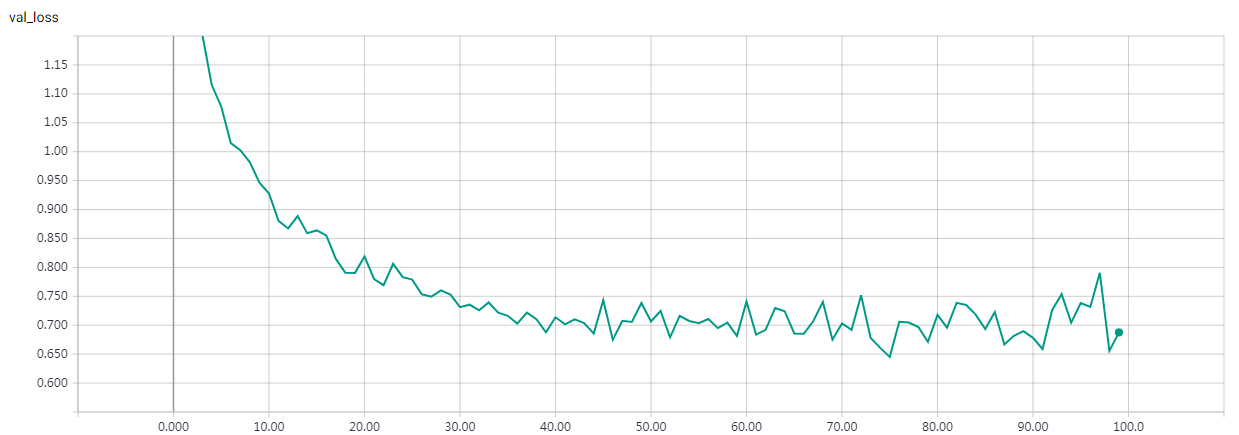
“””Train a simple CNN-Capsule Network on the CIFAR10 small images dataset.
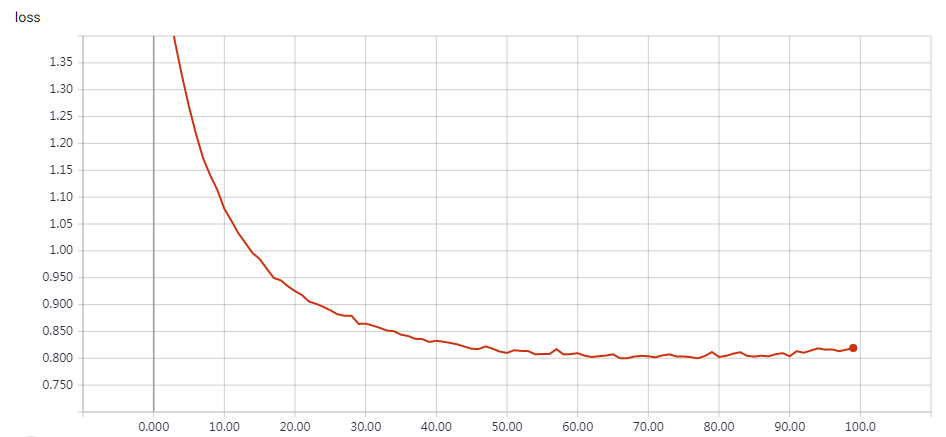
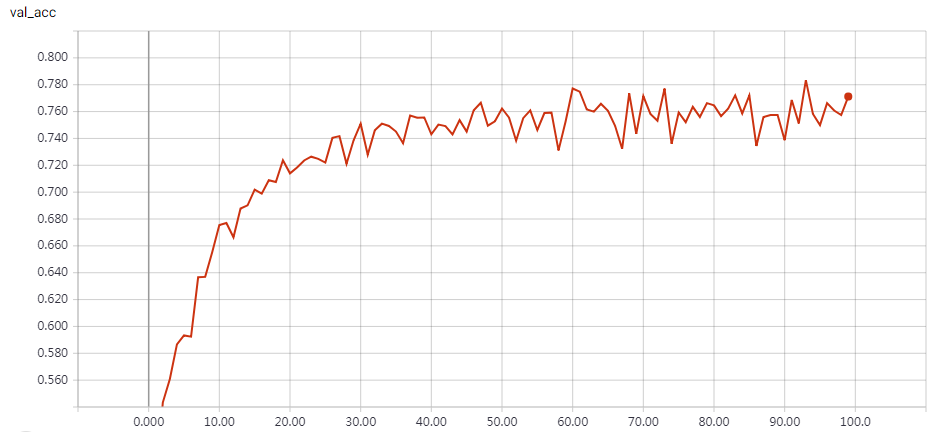
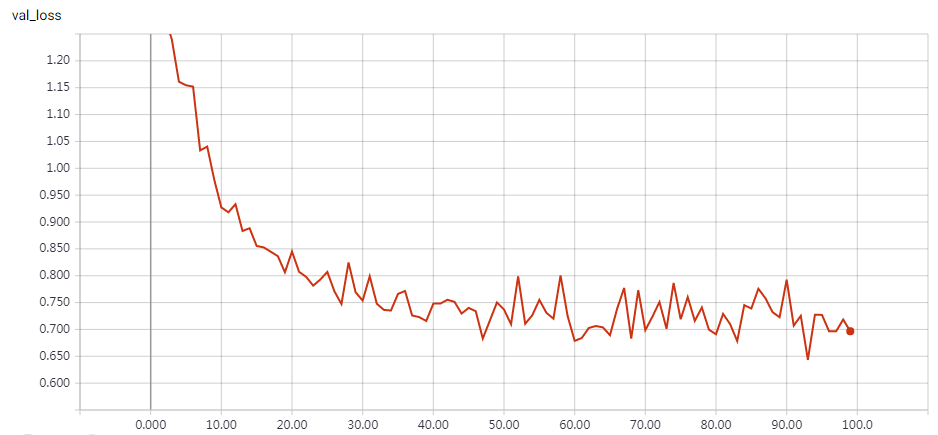
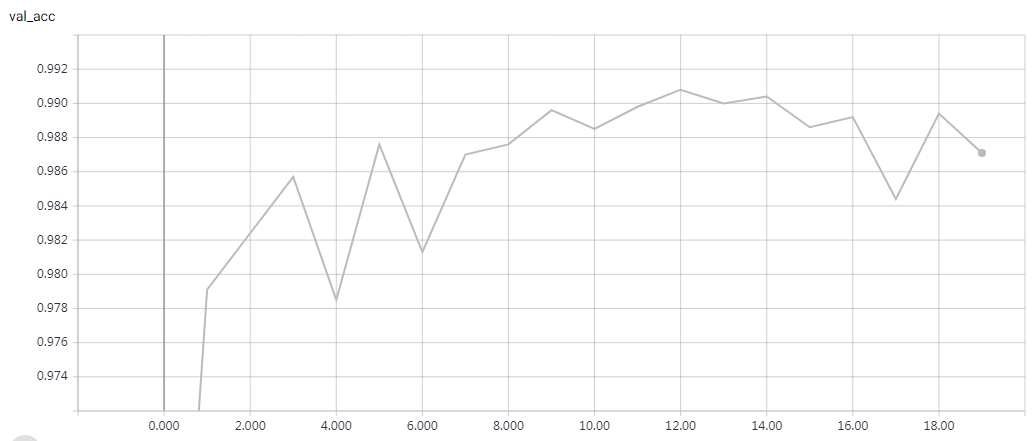
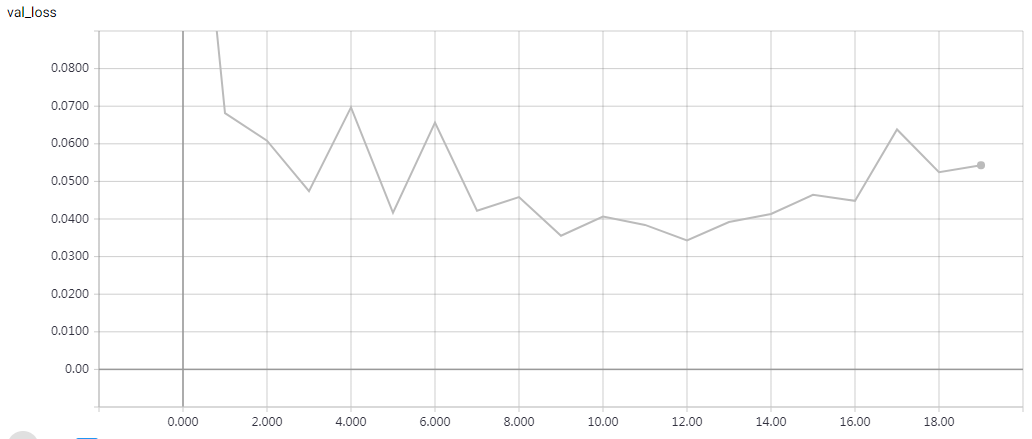
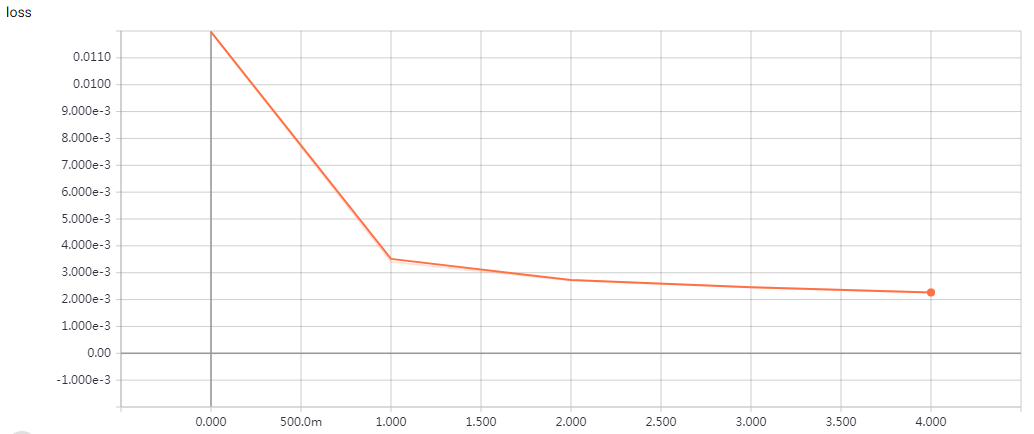
Without Data Augmentation: It gets to 75% validation accuracy in 10 epochs, and 79% after 15 epochs, and overfitting after 20 epochs
With Data Augmentation: It gets to 75% validation accuracy in 10 epochs, and 79% after 15 epochs, and 83% after 30 epochs. In my test, highest validation accuracy is 83.79% after 50 epochs.
This is a fast Implement, just 20s/epoch with a gtx 1070 gpu. “””
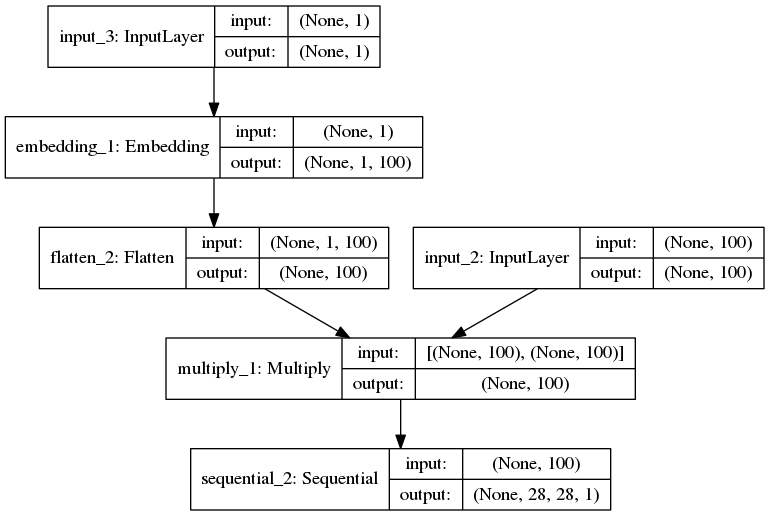
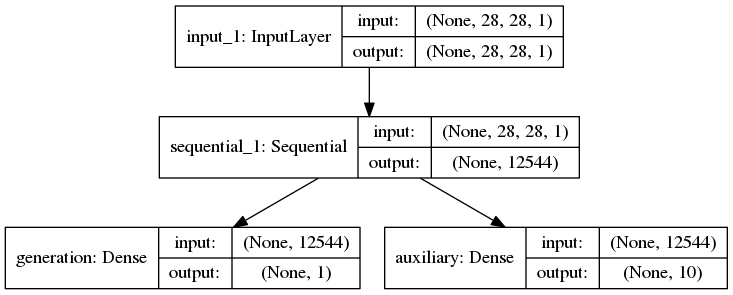
""" Train an Auxiliary Classifier Generative Adversarial Network (ACGAN) on the MNIST dataset. See https://arxiv.org/abs/1610.09585 for more details. You should start to see reasonable images after ~5 epochs, and good images by ~15 epochs. You should use a GPU, as the convolution-heavy operations are very slow on the CPU. Prefer the TensorFlow backend if you plan on iterating, as the compilation time can be a blocker using Theano. Timings: Hardware | Backend | Time / Epoch ------------------------------------------- CPU | TF | 3 hrs Titan X (maxwell) | TF | 4 min Titan X (maxwell) | TH | 7 min Consult https://github.com/lukedeo/keras-acgan for more information and example output """ # Adam parameters suggested in https://arxiv.org/abs/1511.06434 adam_lr = 0.0002 adam_beta_1 = 0.5
'''Trains a stacked what-where autoencoder built on residual blocks on the MNIST dataset. It exemplifies two influential methods that have been developed in the past few years. The first is the idea of properly 'unpooling.' During any max pool, the exact location (the 'where') of the maximal value in a pooled receptive field is lost, however it can be very useful in the overall reconstruction of an input image. Therefore, if the 'where' is handed from the encoder to the corresponding decoder layer, features being decoded can be 'placed' in the right location, allowing for reconstructions of much higher fidelity. # References - Visualizing and Understanding Convolutional Networks Matthew D Zeiler, Rob Fergus https://arxiv.org/abs/1311.2901v3 - Stacked What-Where Auto-encoders Junbo Zhao, Michael Mathieu, Ross Goroshin, Yann LeCun https://arxiv.org/abs/1506.02351v8 The second idea exploited here is that of residual learning. Residual blocks ease the training process by allowing skip connections that give the network the ability to be as linear (or non-linear) as the data sees fit. This allows for much deep networks to be easily trained. The residual element seems to be advantageous in the context of this example as it allows a nice symmetry between the encoder and decoder. Normally, in the decoder, the final projection to the space where the image is reconstructed is linear, however this does not have to be the case for a residual block as the degree to which its output is linear or non-linear is determined by the data it is fed. However, in order to cap the reconstruction in this example, a hard softmax is applied as a bias because we know the MNIST digits are mapped to [0, 1]. # References - Deep Residual Learning for Image Recognition Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun https://arxiv.org/abs/1512.03385v1 - Identity Mappings in Deep Residual Networks Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun https://arxiv.org/abs/1603.05027v3 '''
‘’’Transfer learning toy example. 1 - Train a simple convnet on the MNIST dataset the first 5 digits [0..4]. 2 - Freeze convolutional layers and fine-tune dense layers for the classification of digits [5..9]. Get to 99.8% test accuracy after 5 epochs for the first five digits classifier and 99.2% for the last five digits after transfer + fine-tuning. ‘’’
'''An implementation of sequence to sequence learning for performing addition Input: "535+61" Output: "596" Padding is handled by using a repeated sentinel character (space) Input may optionally be reversed, shown to increase performance in many tasks in: "Learning to Execute" http://arxiv.org/abs/1410.4615 and "Sequence to Sequence Learning with Neural Networks" http://papers.nips.cc/paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf Theoretically it introduces shorter term dependencies between source and target. Two digits reversed: + One layer LSTM (128 HN), 5k training examples = 99% train/test accuracy in 55 epochs Three digits reversed: + One layer LSTM (128 HN), 50k training examples = 99% train/test accuracy in 100 epochs Four digits reversed: + One layer LSTM (128 HN), 400k training examples = 99% train/test accuracy in 20 epochs Five digits reversed: + One layer LSTM (128 HN), 550k training examples = 99% train/test accuracy in 30 epochs '''
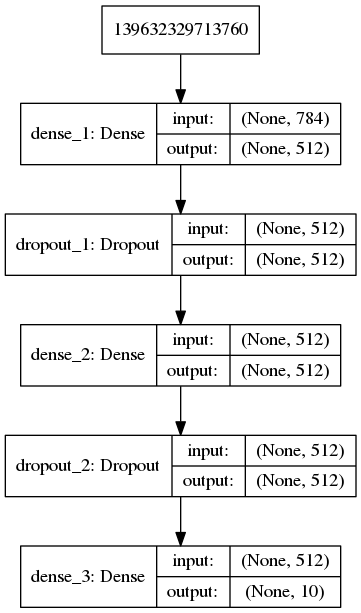
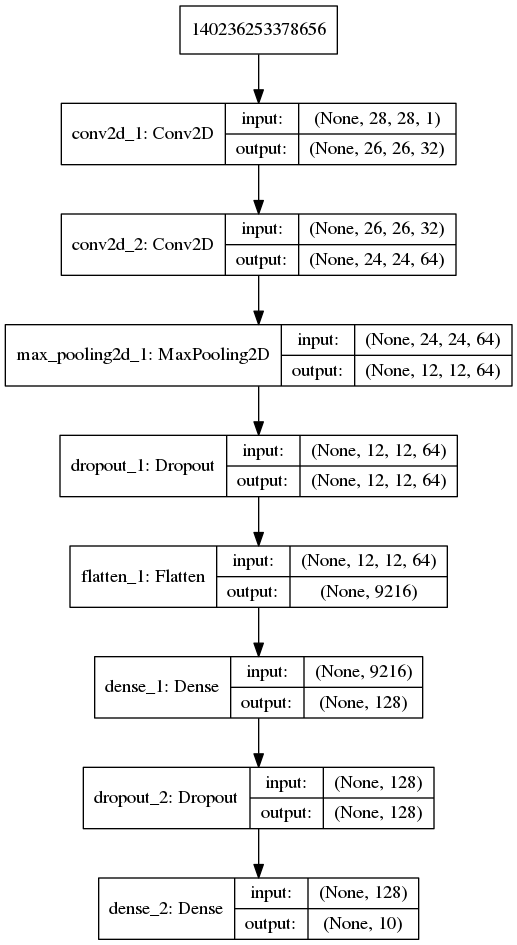
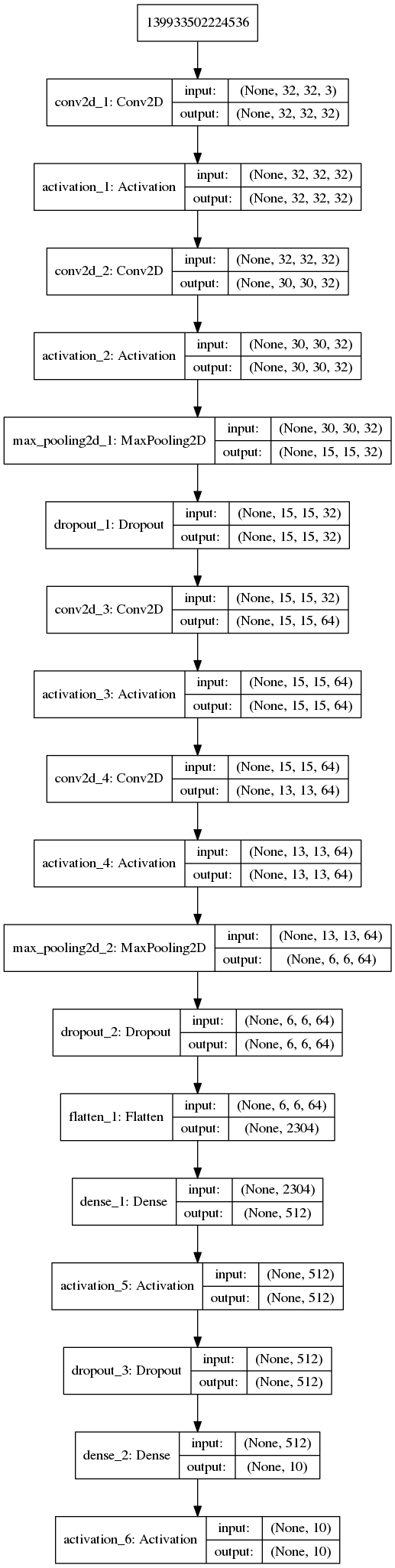
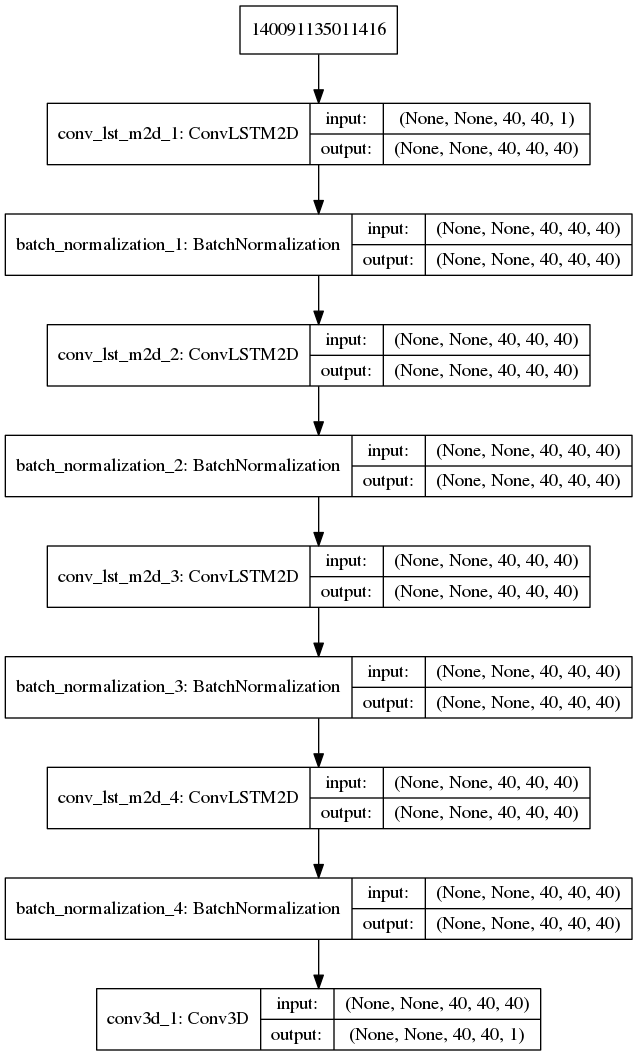
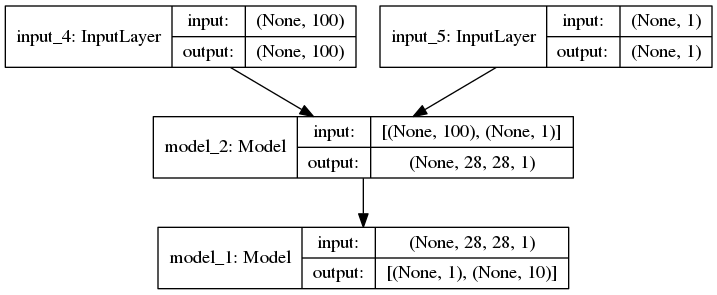
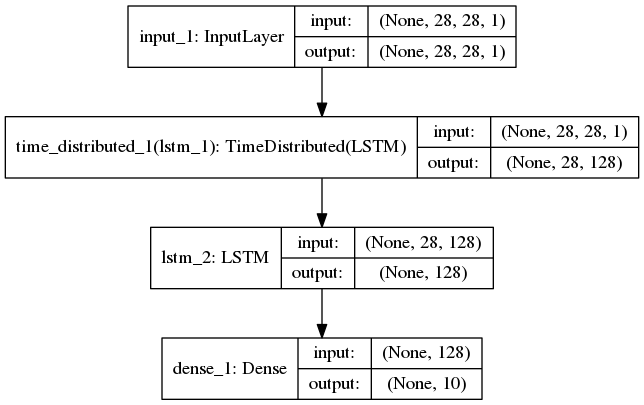
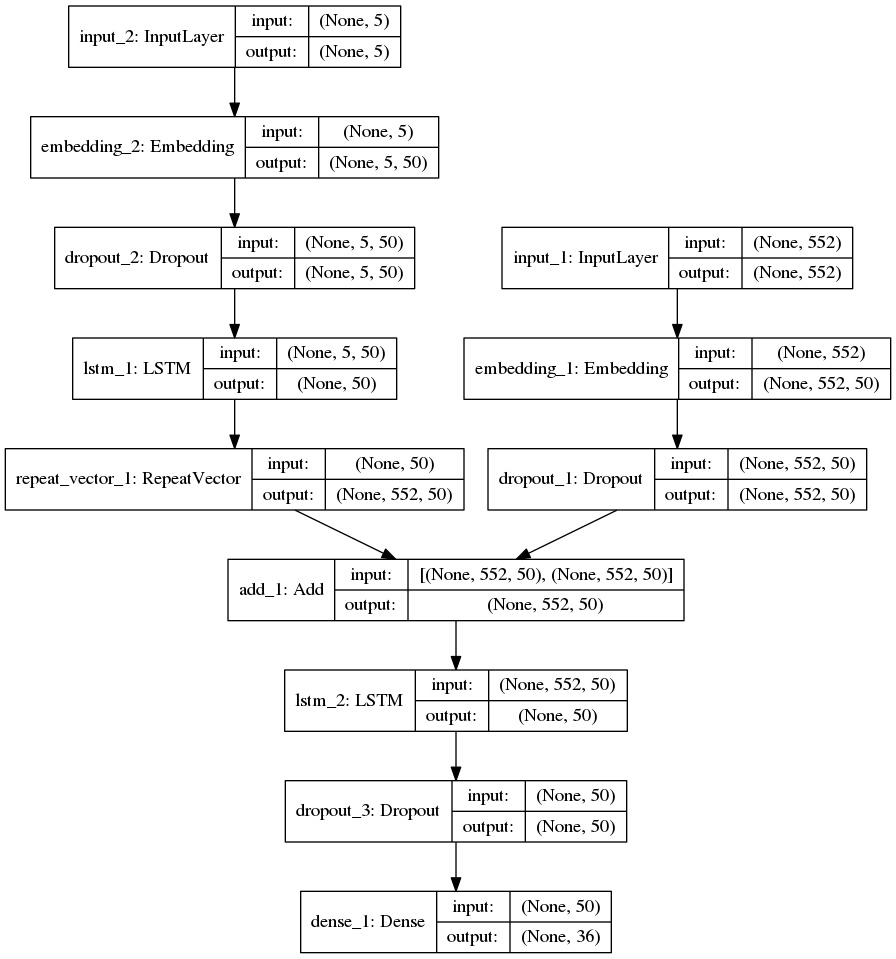
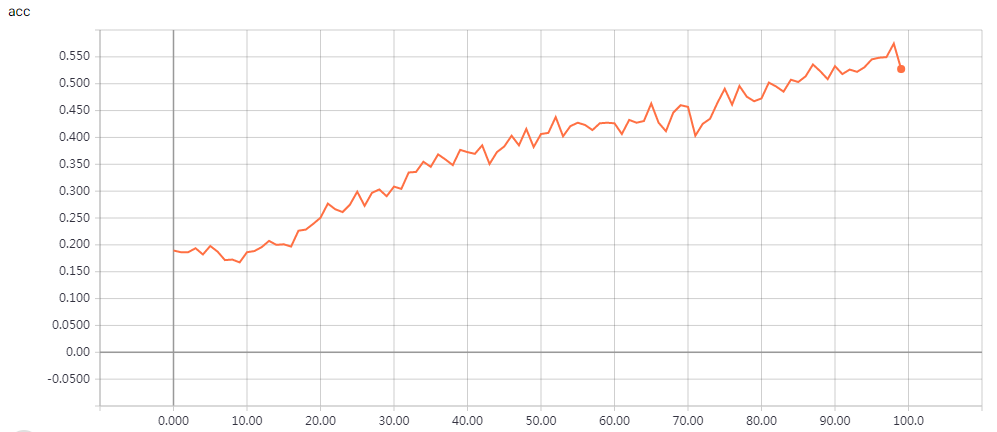
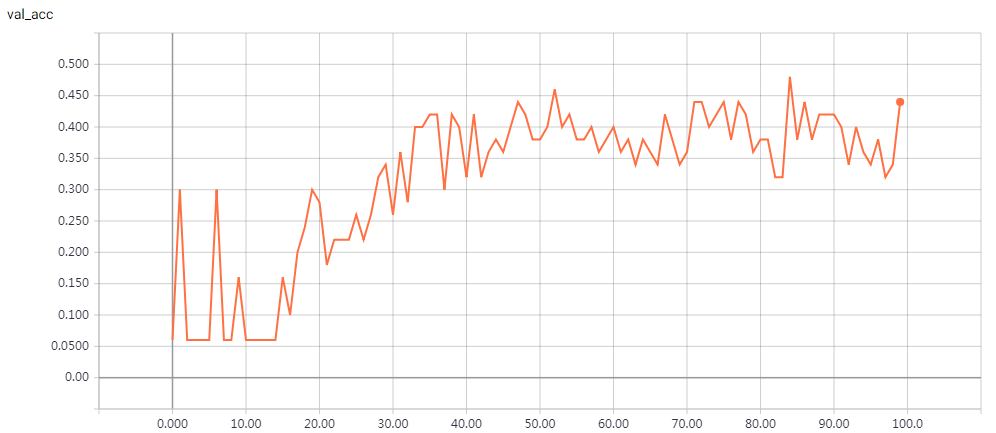
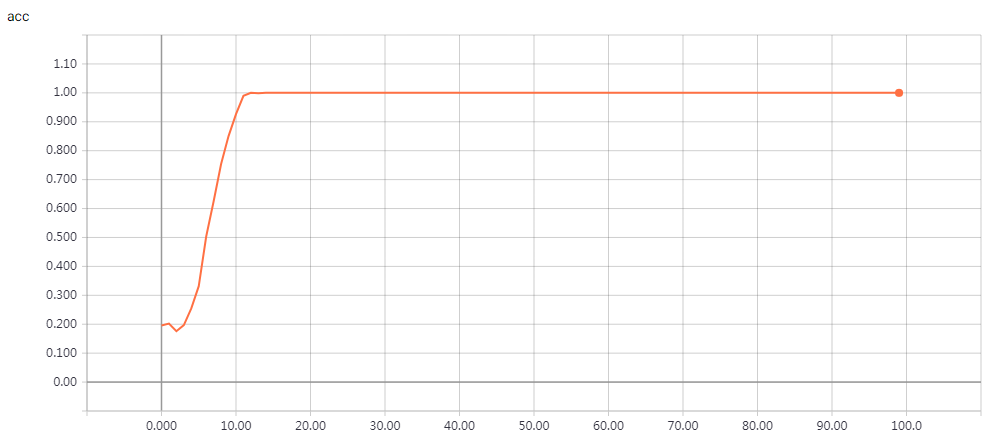
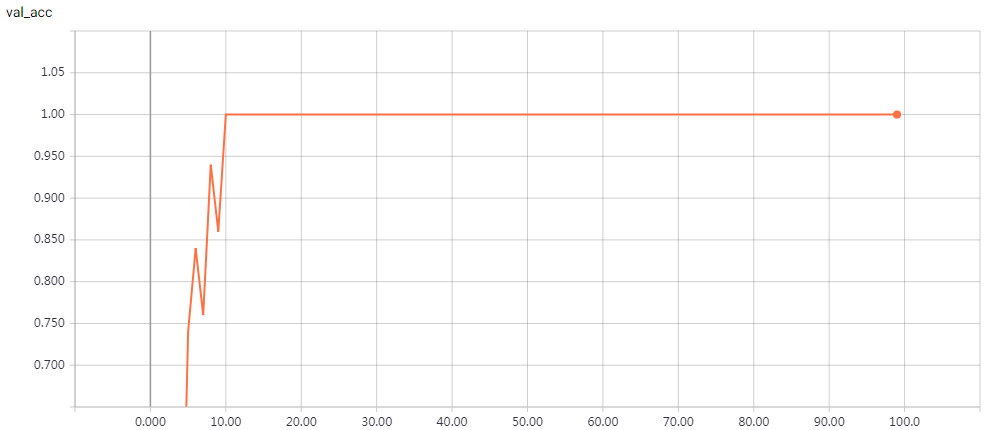
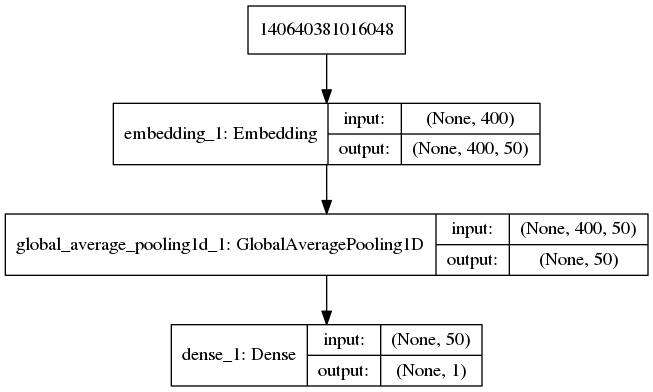
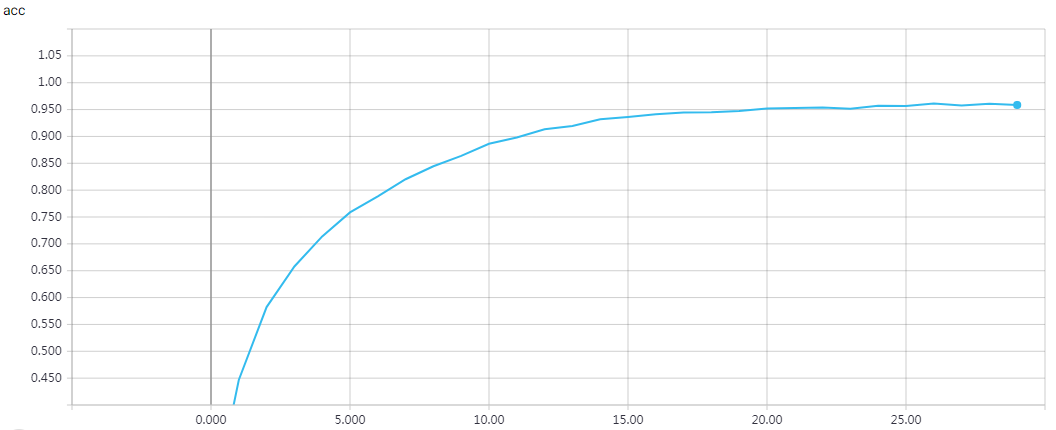
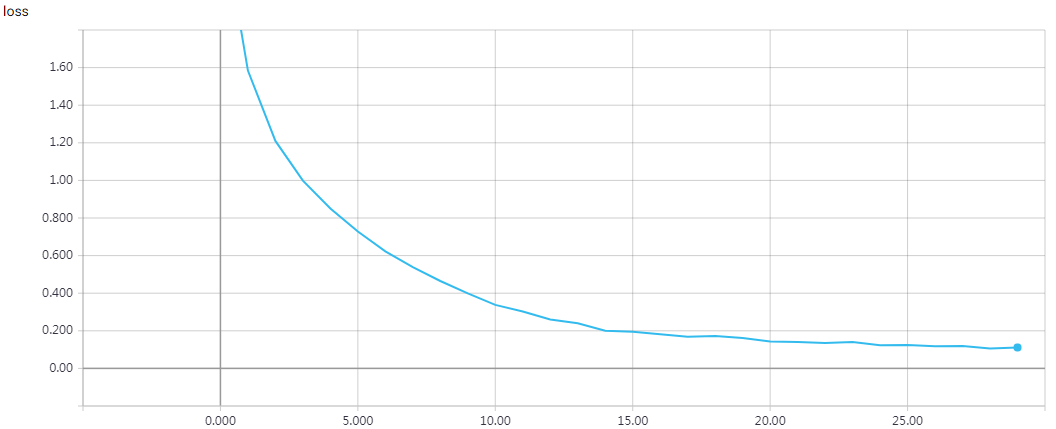
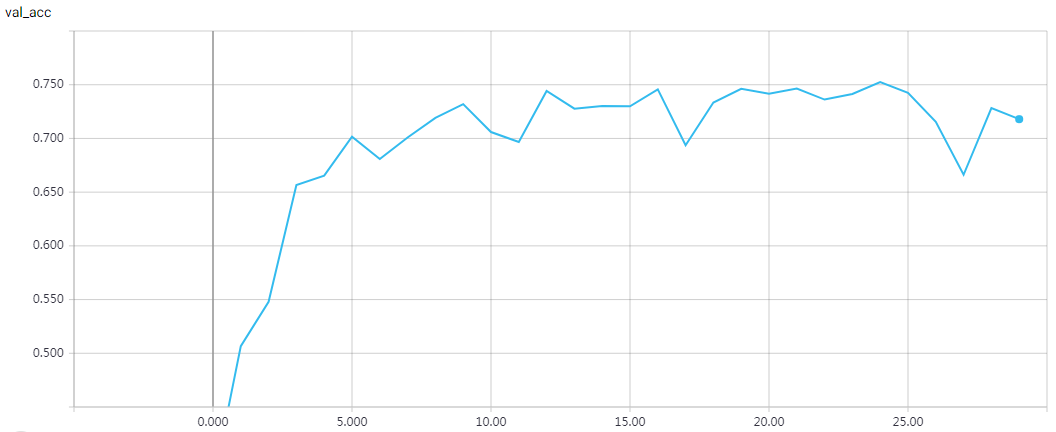
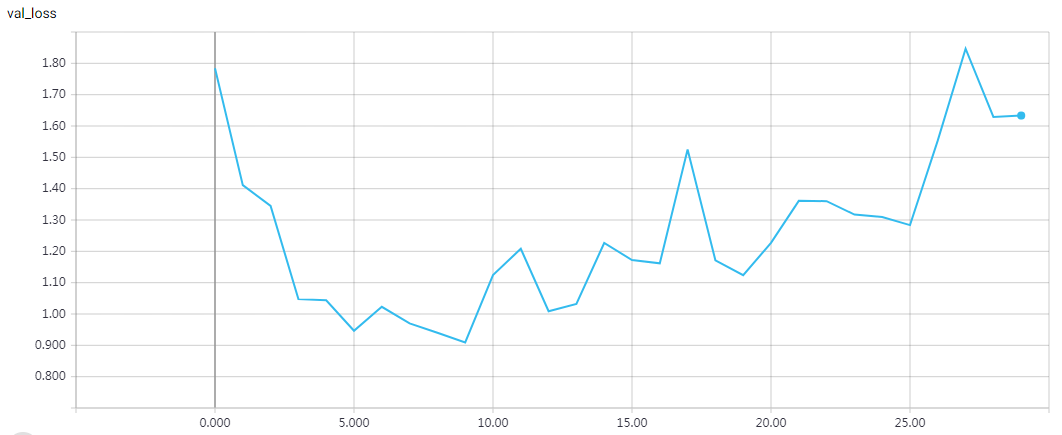
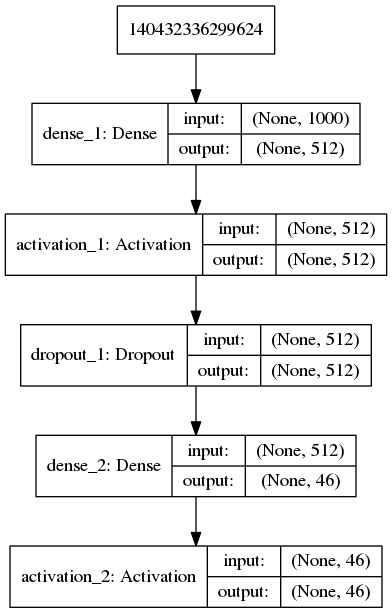
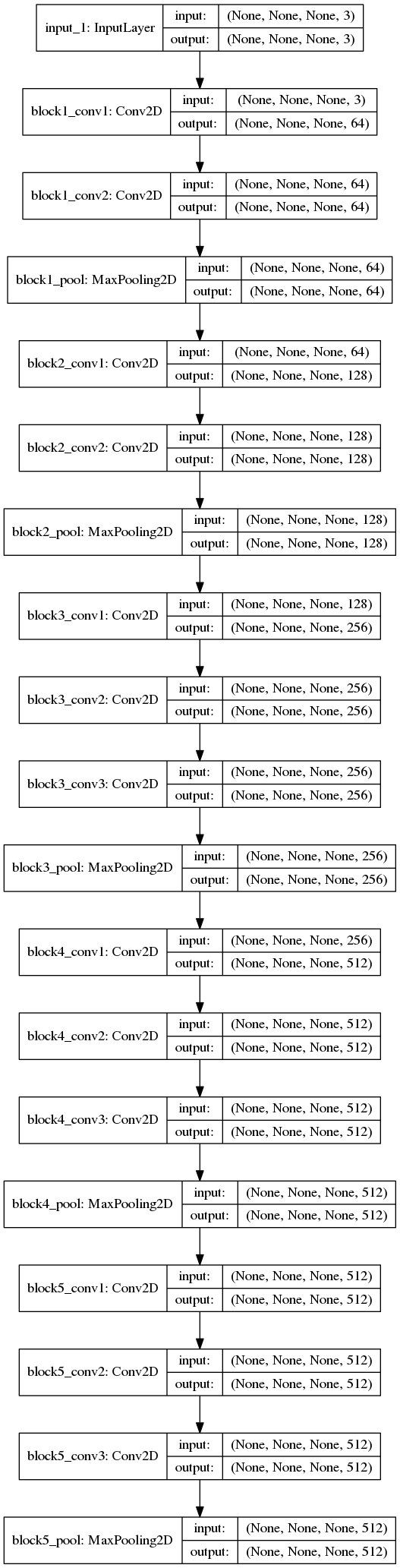
网络结构
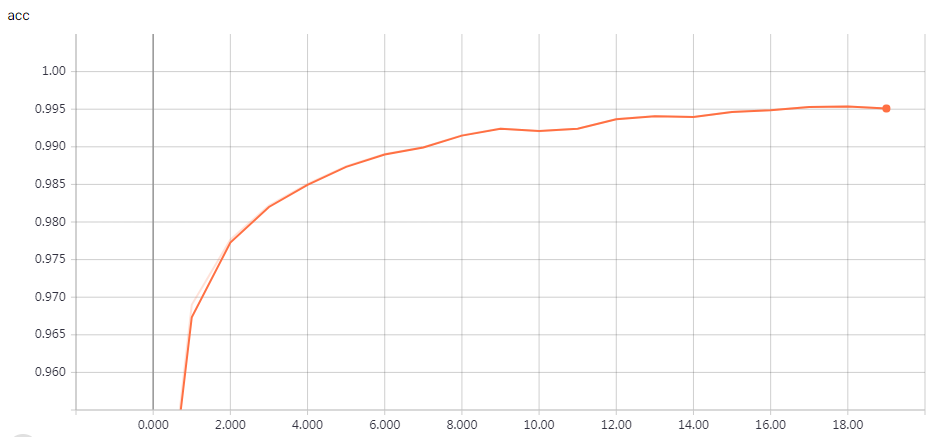
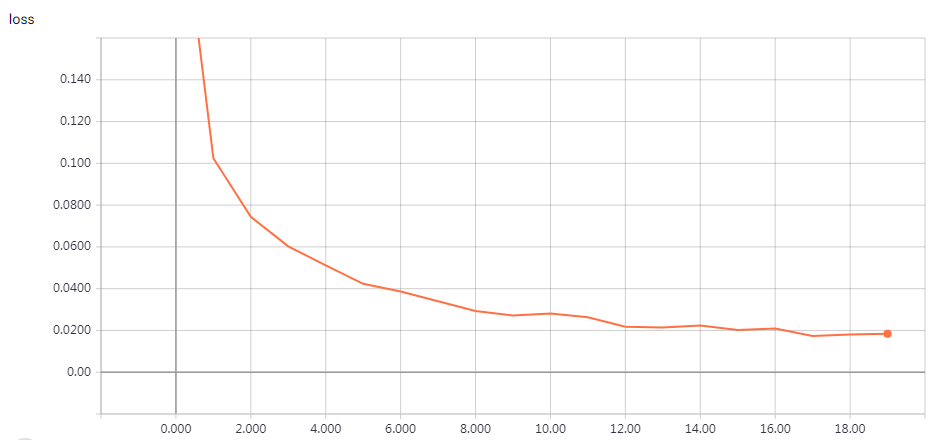
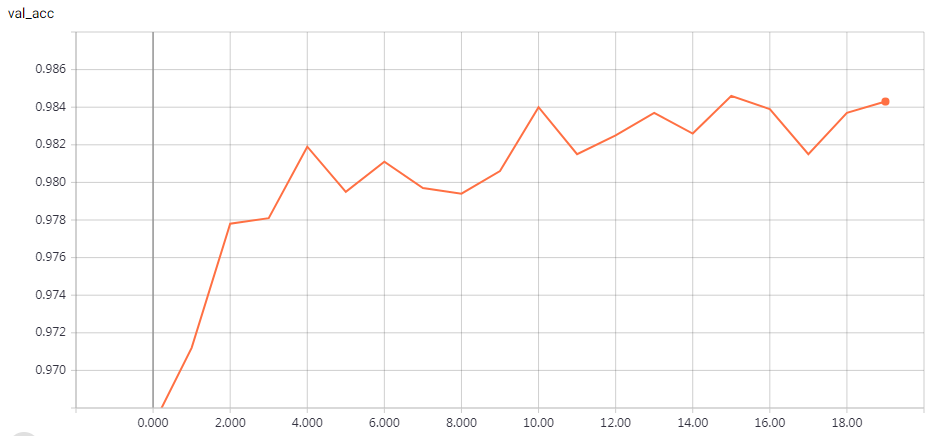
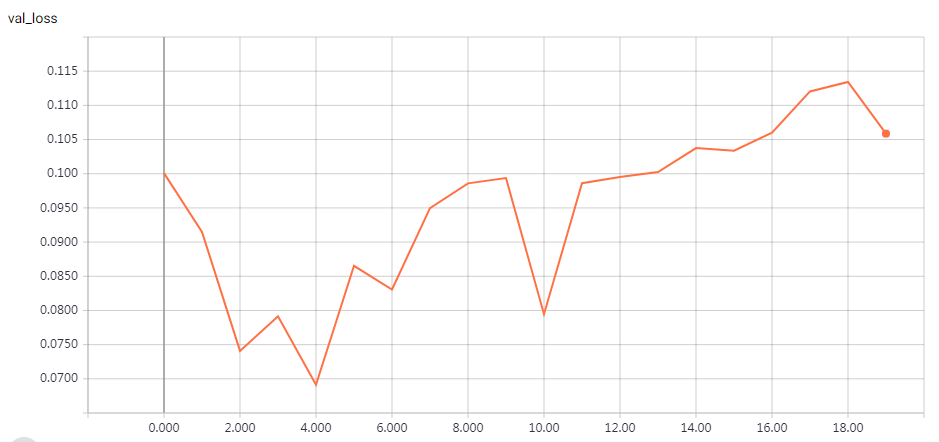
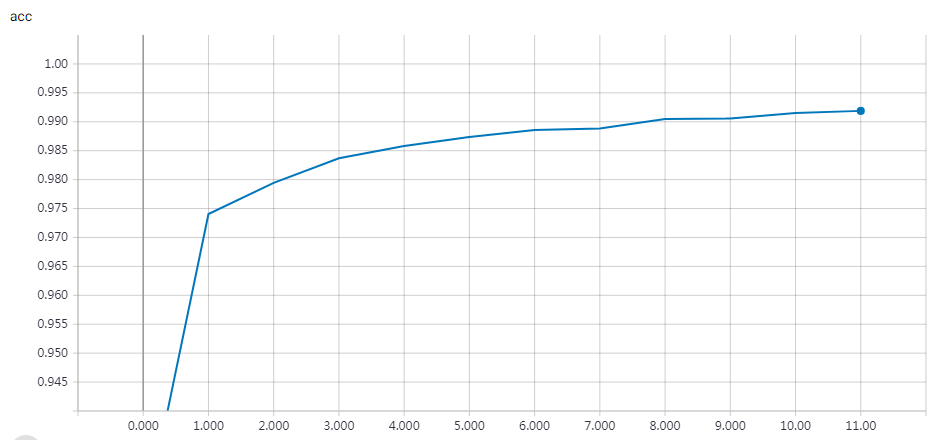
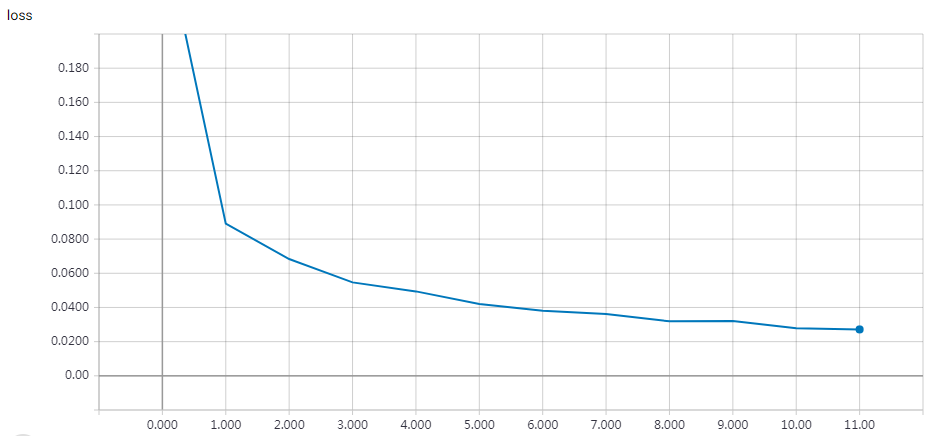
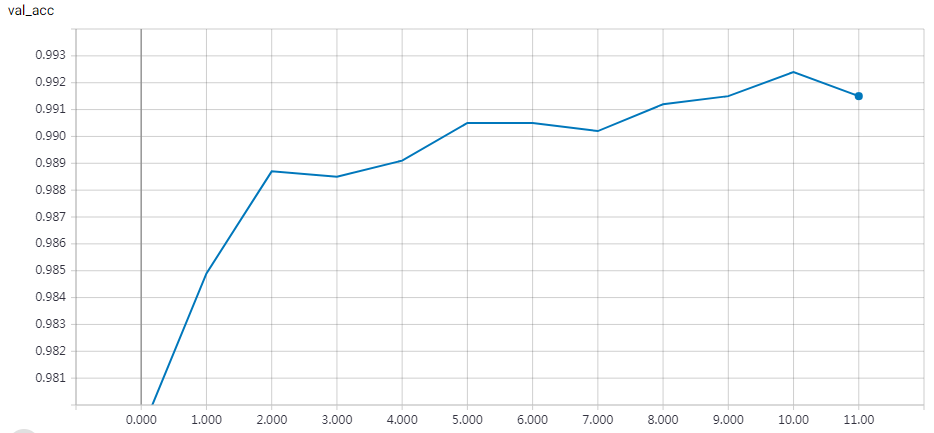
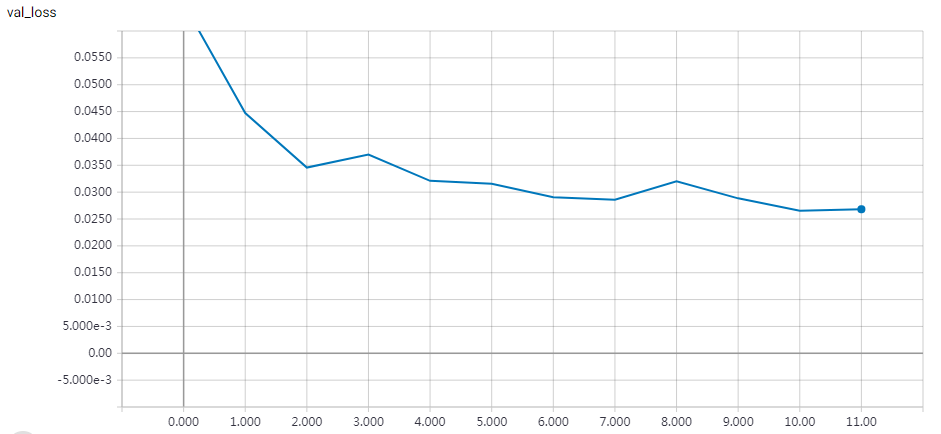
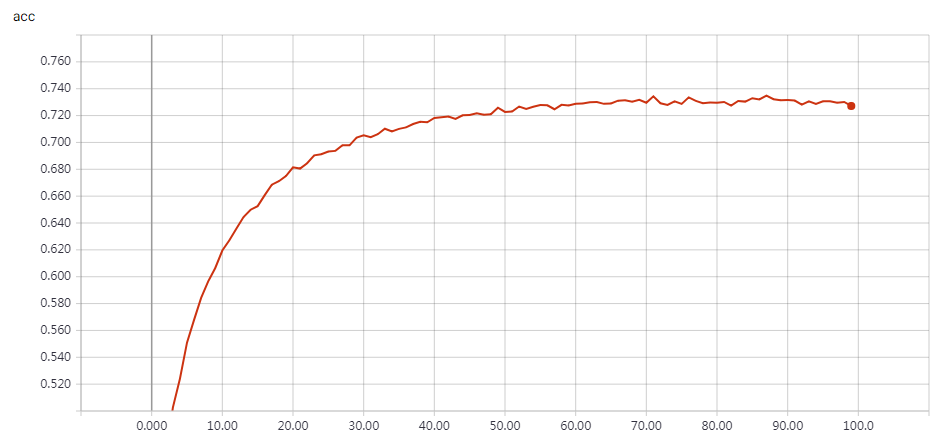
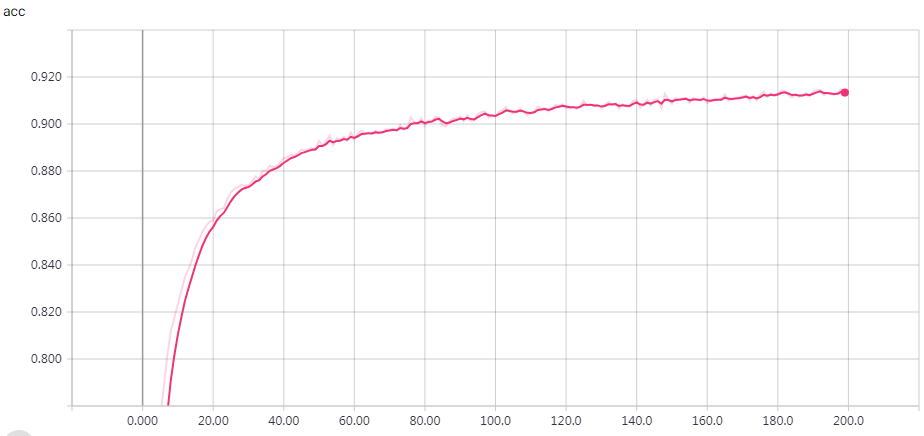
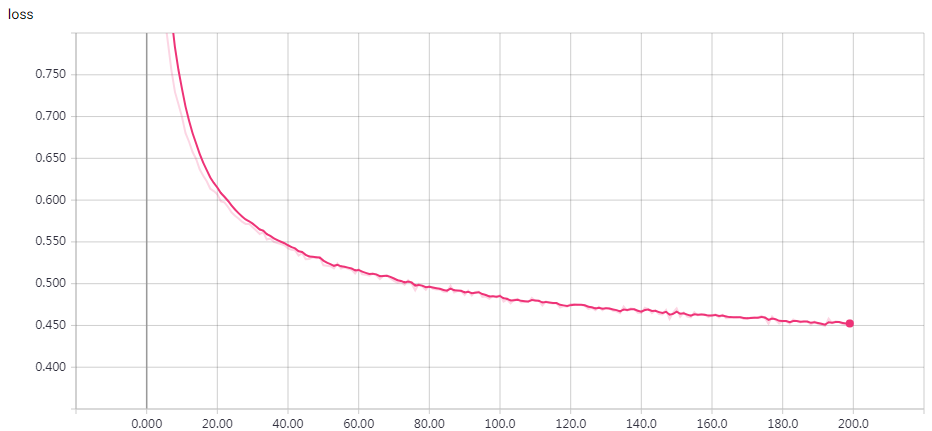
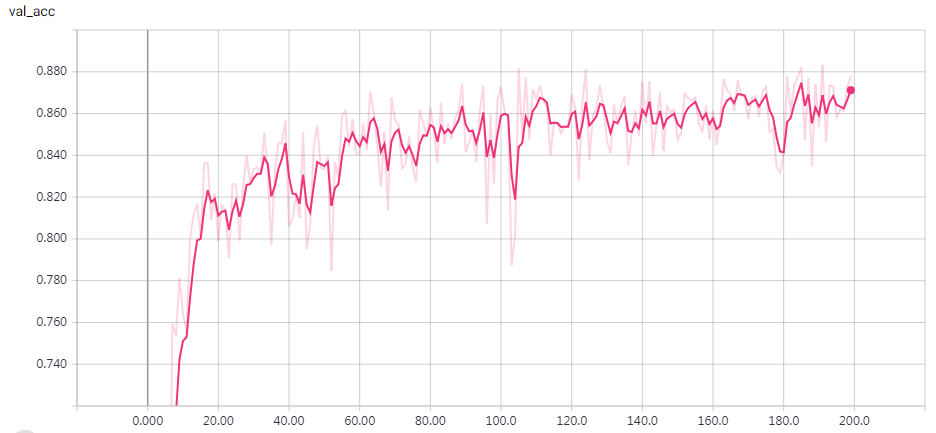
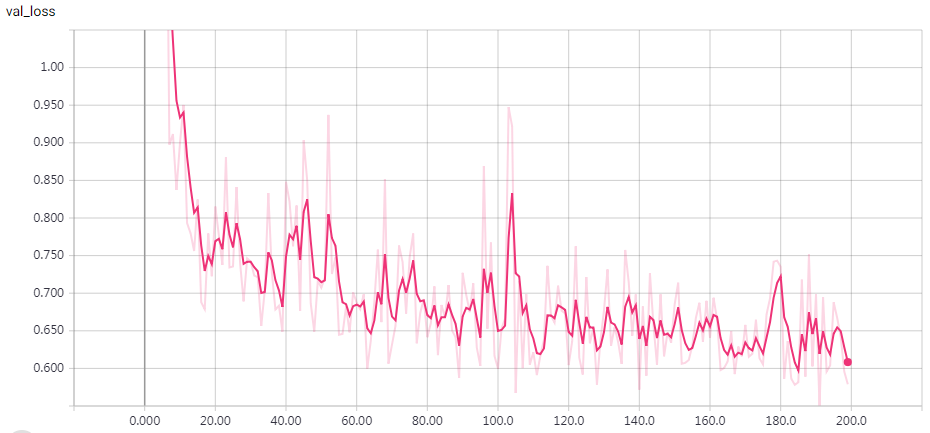
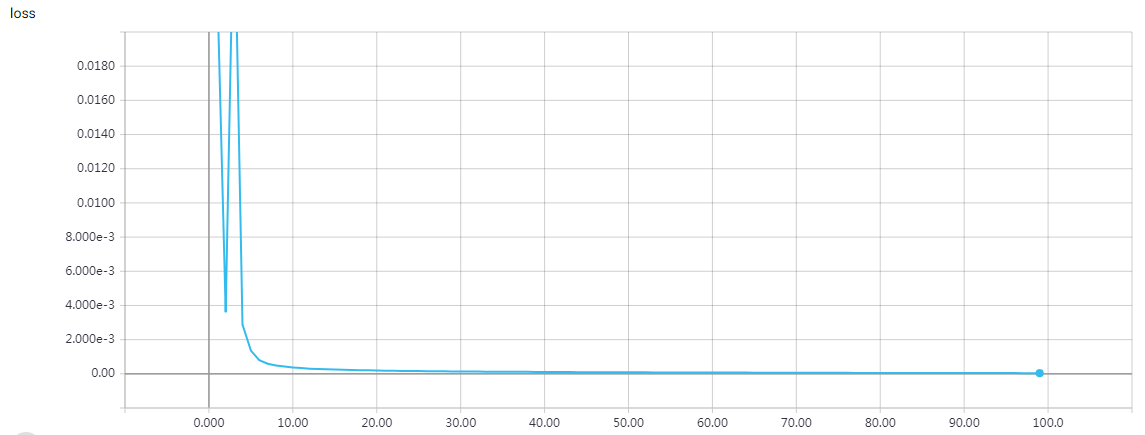
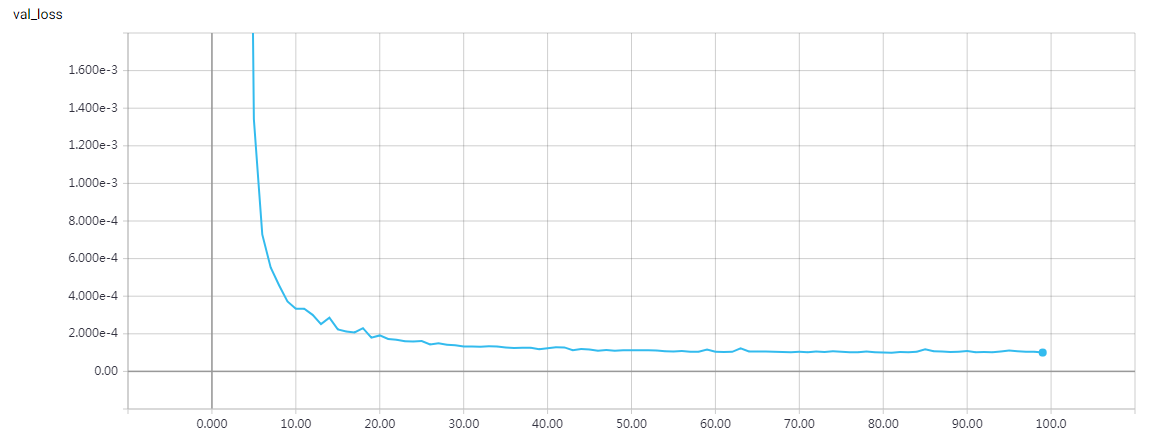
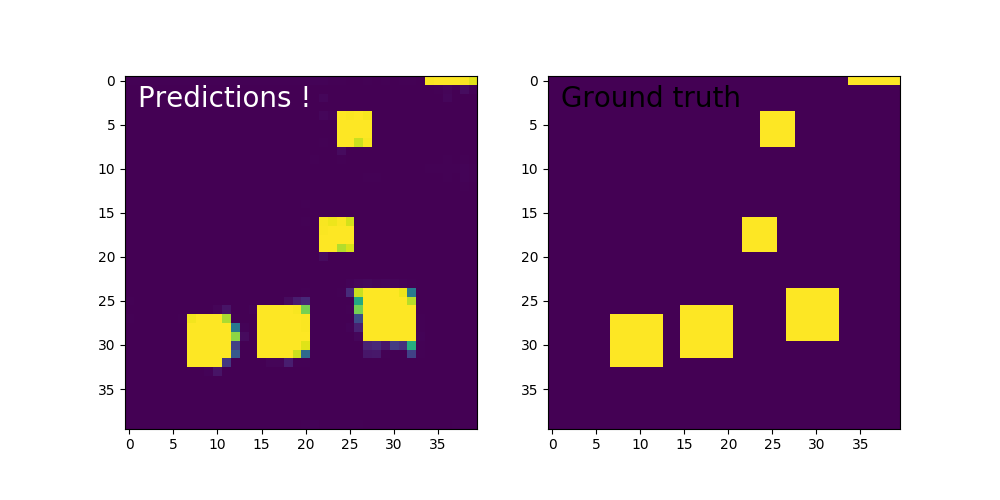
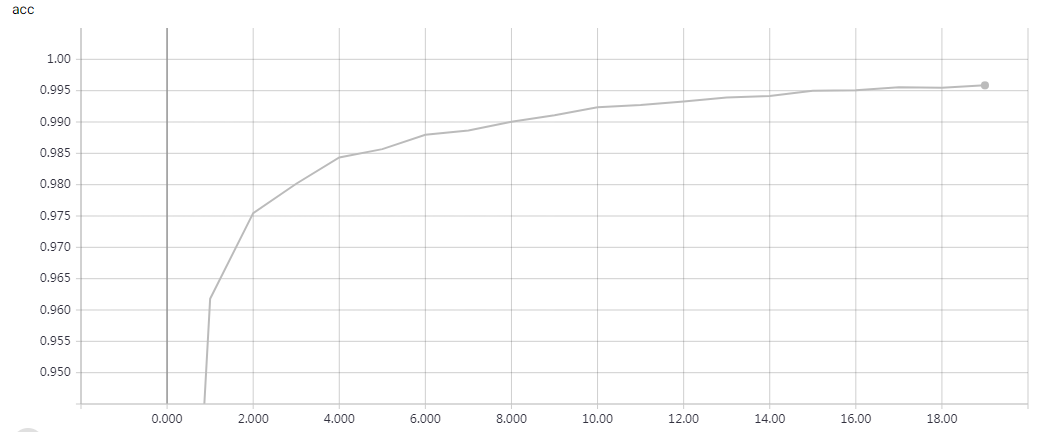
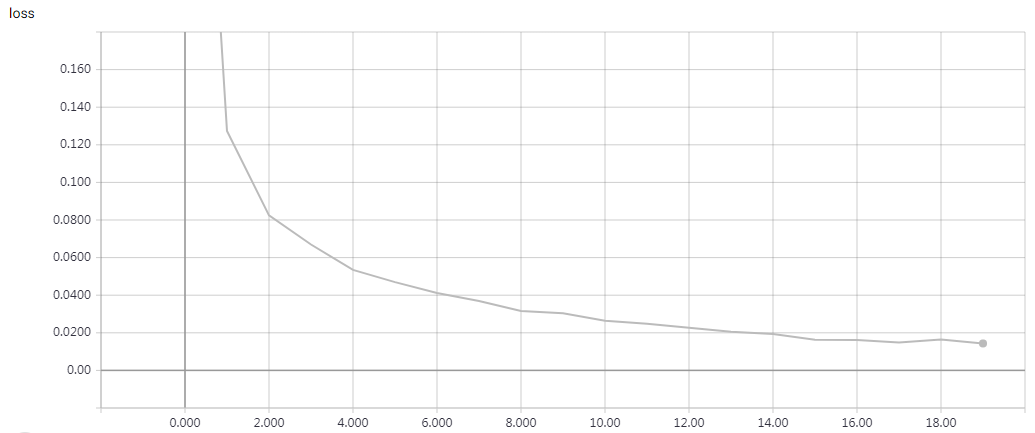
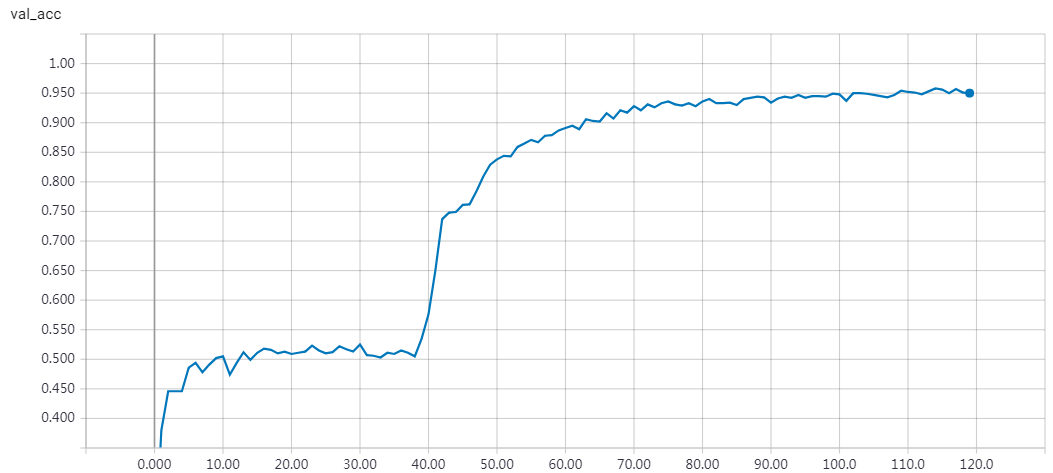
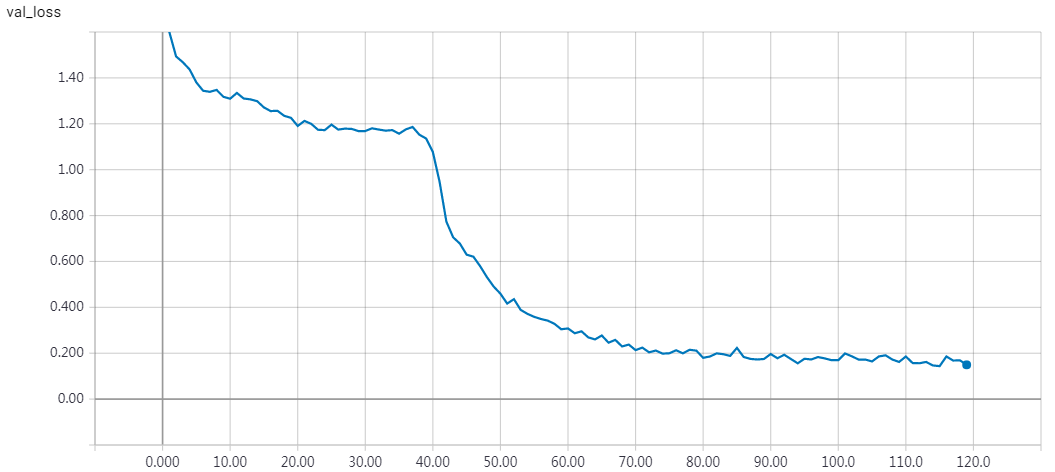
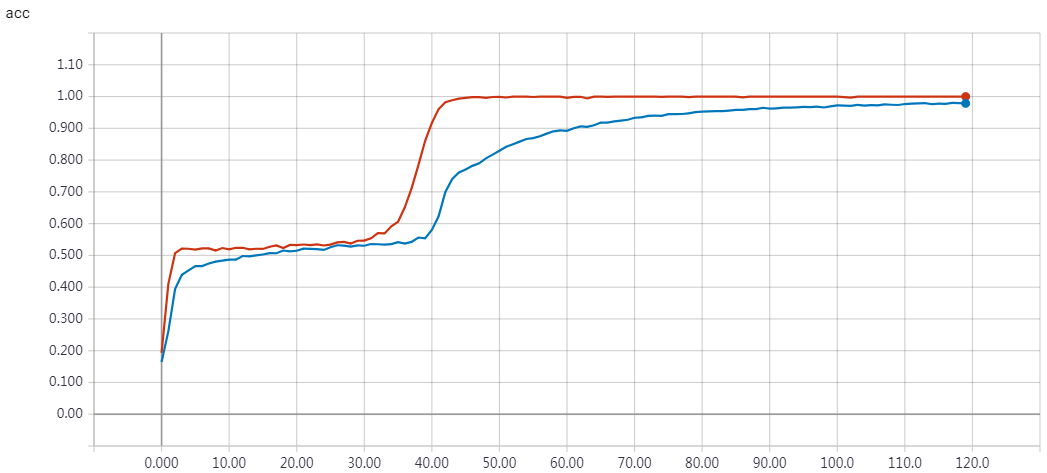
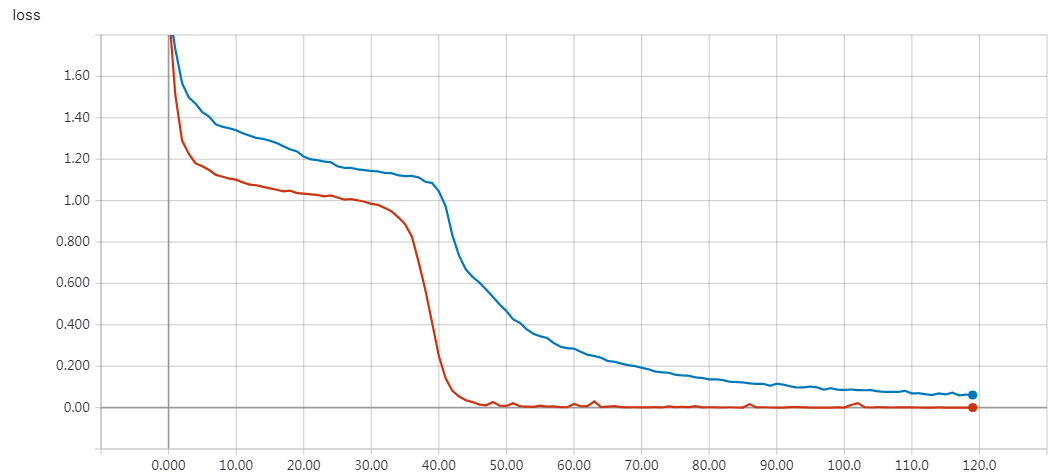
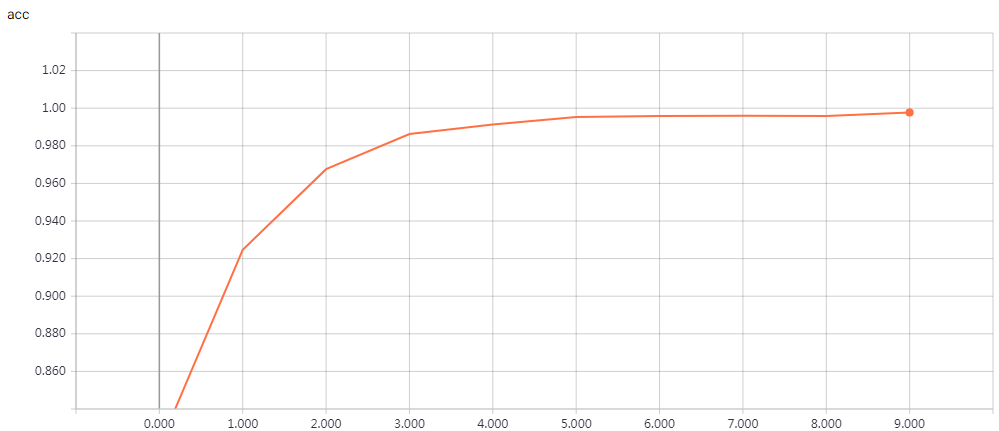
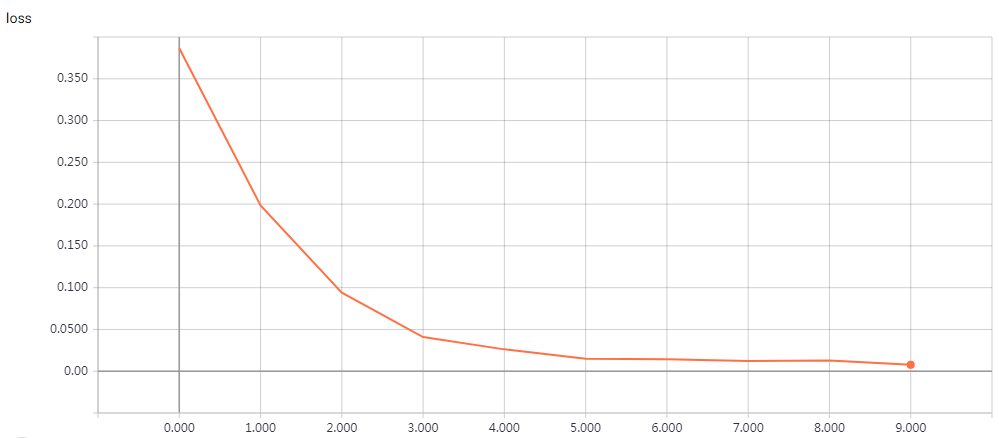
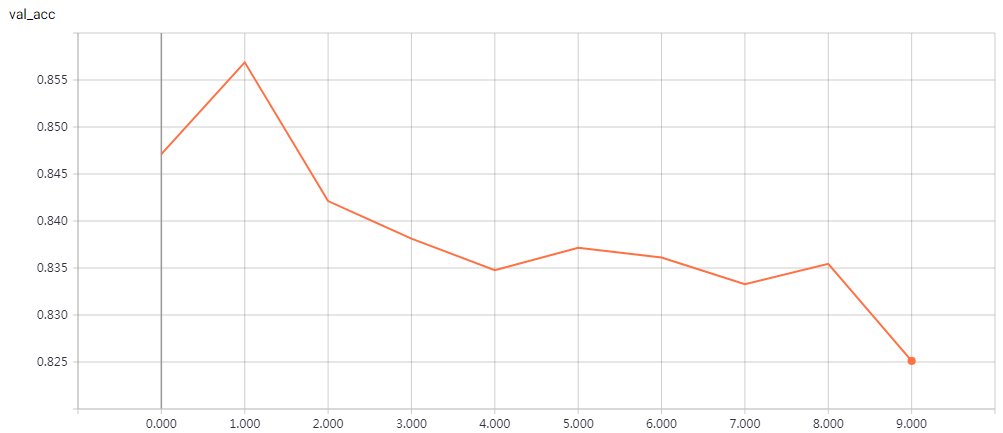
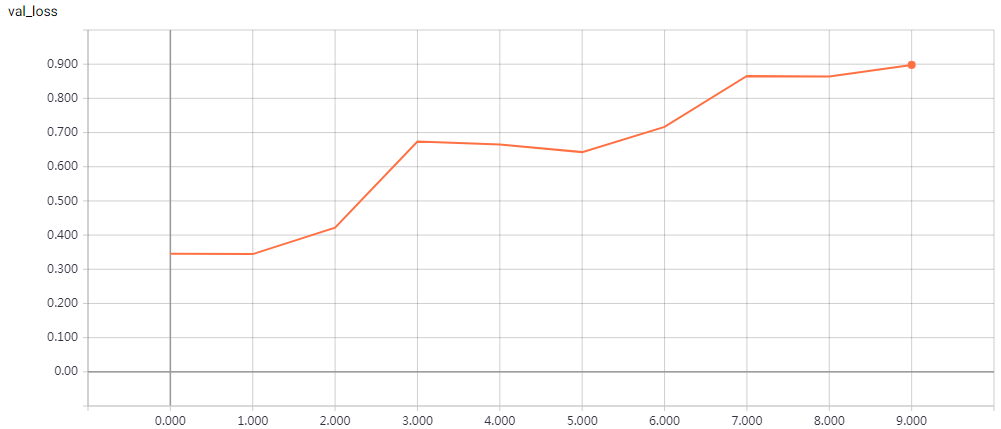
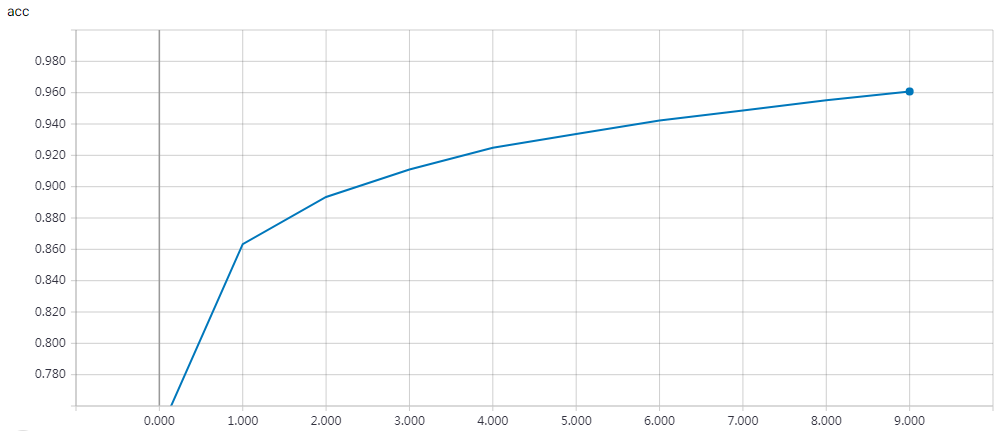
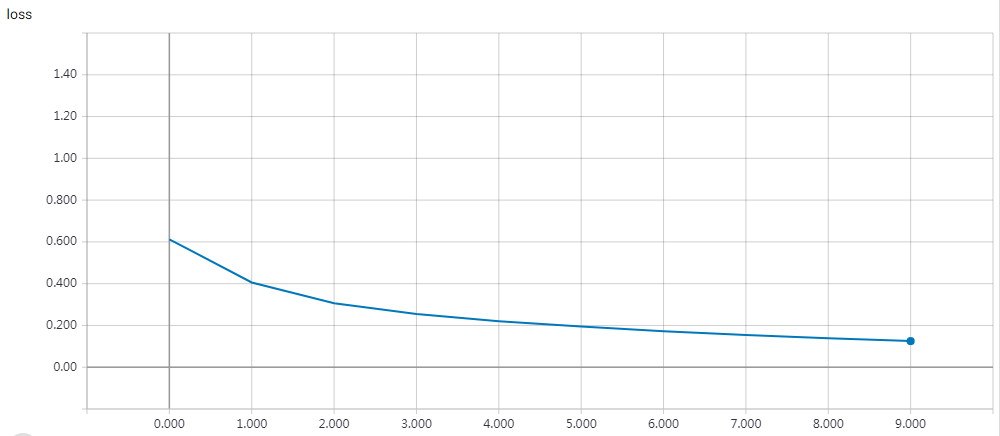
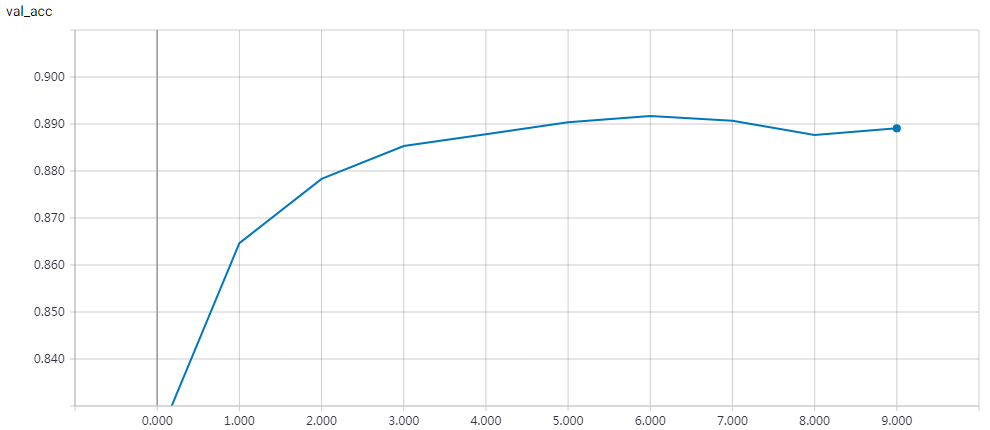
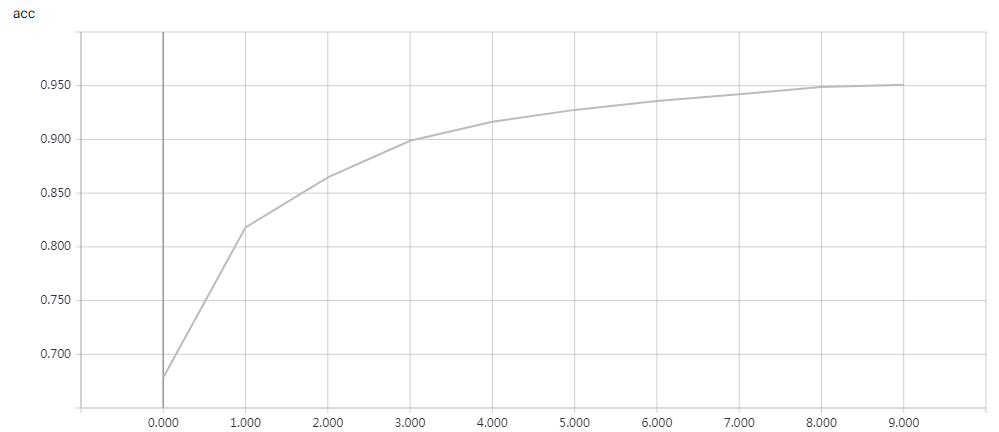
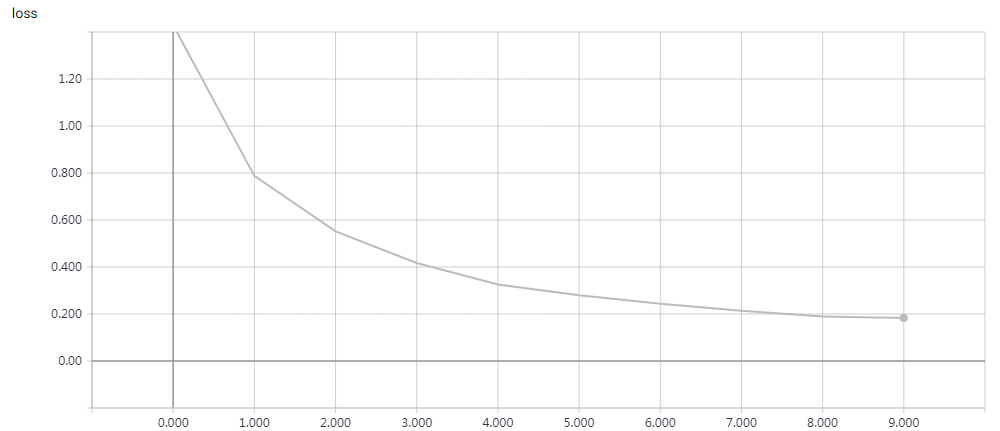
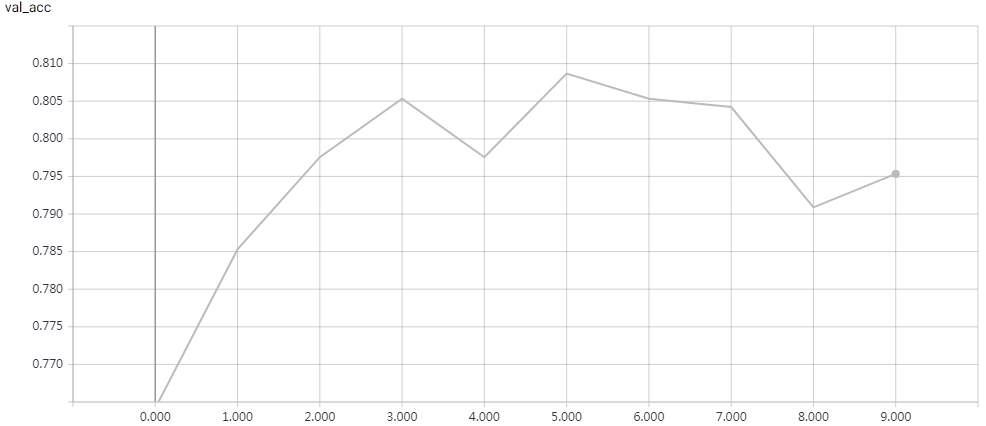
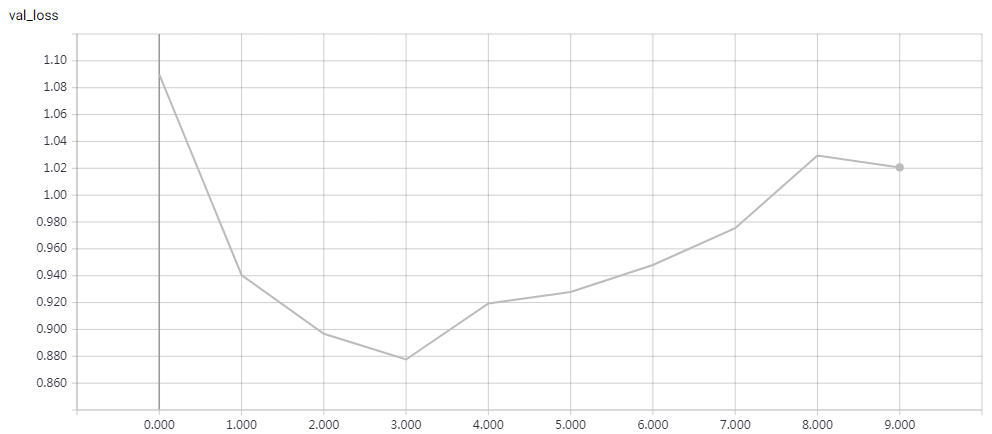
实验结果
1 2 3 4 5 6 7 8 9 10 11 12 13
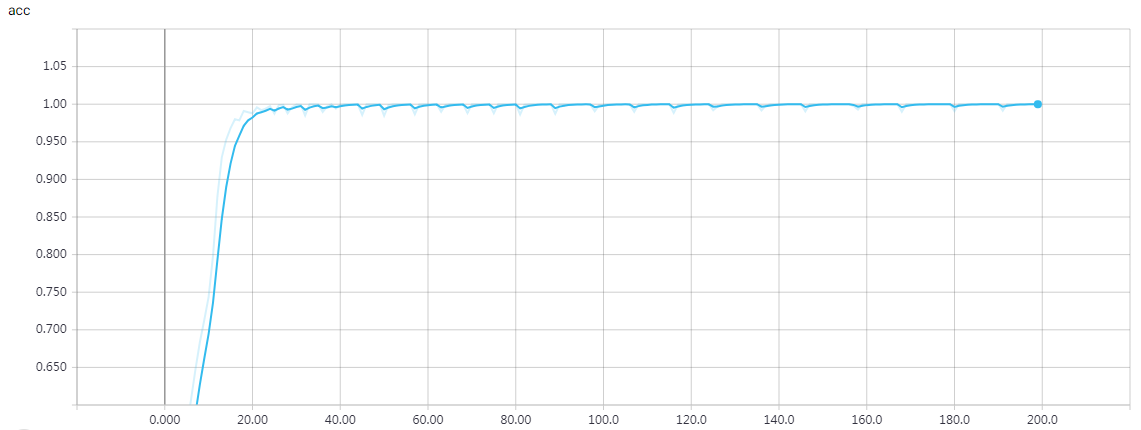
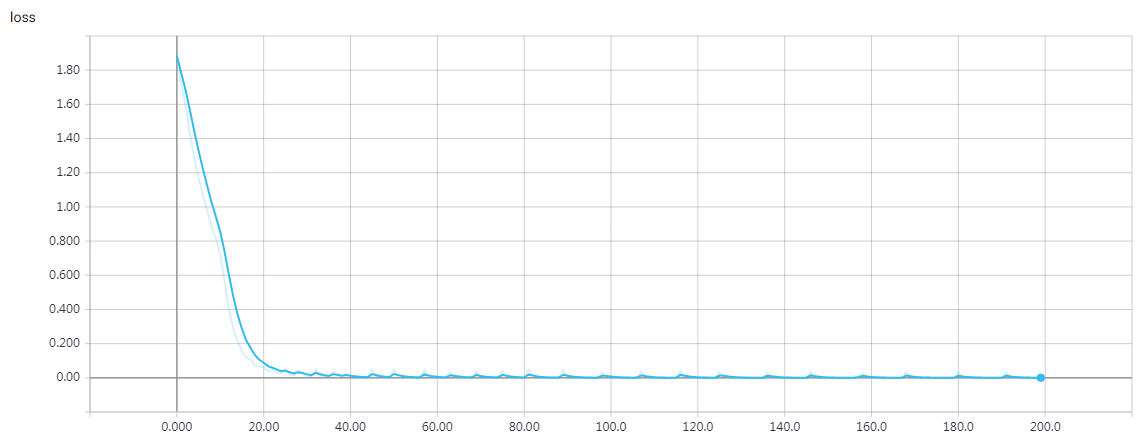
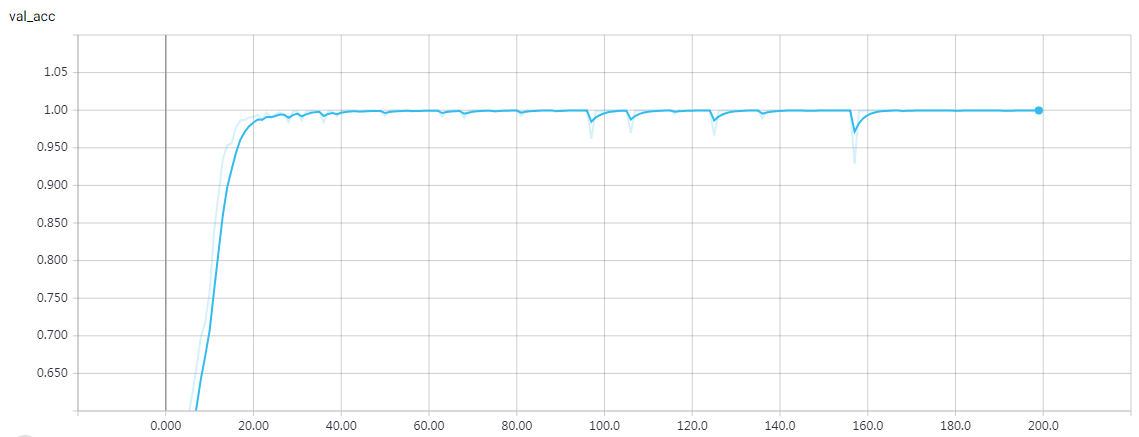
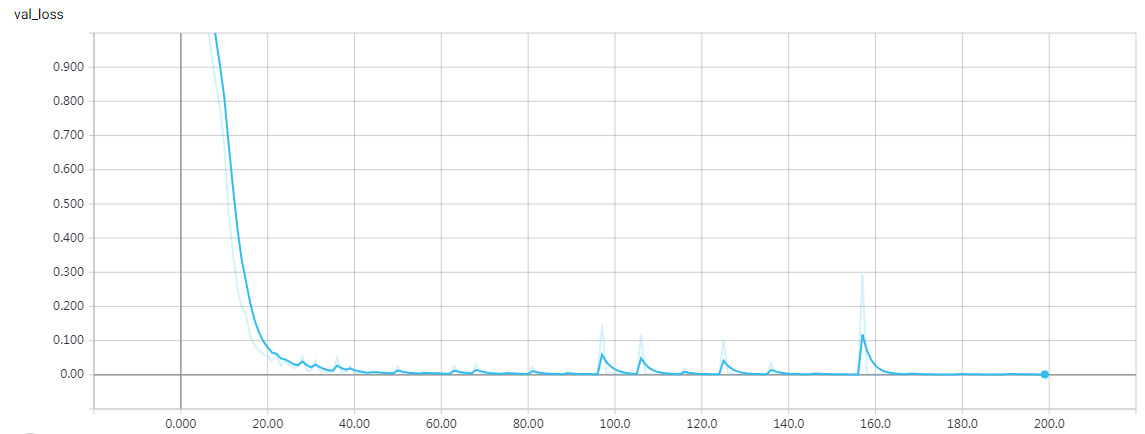
epochs = 200 时的结果
loss: 1.2168e-04 - acc: 1.0000 - val_loss: 0.0011 - val_acc: 0.9997 Q 6+909 T 915 ☑ 915 Q 128+263 T 391 ☑ 391 Q 104+0 T 104 ☑ 104 Q 63+352 T 415 ☑ 415 Q 624+8 T 632 ☑ 632 Q 31+251 T 282 ☑ 282 Q 758+445 T 1203 ☑ 1203 Q 88+534 T 622 ☑ 622 Q 315+624 T 939 ☑ 939 Q 81+459 T 540 ☑ 540
'''Trains two recurrent neural networks based upon a story and a question. The resulting merged vector is then queried to answer a range of bAbI tasks. The results are comparable to those for an LSTM model provided in Weston et al.: "Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks" http://arxiv.org/abs/1502.05698 Task Number | FB LSTM Baseline | Keras QA --- | --- | --- QA1 - Single Supporting Fact | 50 | 100.0 QA2 - Two Supporting Facts | 20 | 50.0 QA3 - Three Supporting Facts | 20 | 20.5 QA4 - Two Arg. Relations | 61 | 62.9 QA5 - Three Arg. Relations | 70 | 61.9 QA6 - yes/No Questions | 48 | 50.7 QA7 - Counting | 49 | 78.9 QA8 - Lists/Sets | 45 | 77.2 QA9 - Simple Negation | 64 | 64.0 QA10 - Indefinite Knowledge | 44 | 47.7 QA11 - Basic Coreference | 72 | 74.9 QA12 - Conjunction | 74 | 76.4 QA13 - Compound Coreference | 94 | 94.4 QA14 - Time Reasoning | 27 | 34.8 QA15 - Basic Deduction | 21 | 32.4 QA16 - Basic Induction | 23 | 50.6 QA17 - Positional Reasoning | 51 | 49.1 QA18 - Size Reasoning | 52 | 90.8 QA19 - Path Finding | 8 | 9.0 QA20 - Agent's Motivations | 91 | 90.7 For the resources related to the bAbI project, refer to: https://research.facebook.com/researchers/1543934539189348 # Notes - With default word, sentence, and query vector sizes, the GRU model achieves: - 100% test accuracy on QA1 in 20 epochs (2 seconds per epoch on CPU) - 50% test accuracy on QA2 in 20 epochs (16 seconds per epoch on CPU) In comparison, the Facebook paper achieves 50% and 20% for the LSTM baseline. - The task does not traditionally parse the question separately. This likely improves accuracy and is a good example of merging two RNNs. - The word vector embeddings are not shared between the story and question RNNs. - See how the accuracy changes given 10,000 training samples (en-10k) instead of only 1000. 1000 was used in order to be comparable to the original paper. - Experiment with GRU, LSTM, and JZS1-3 as they give subtly different results. - The length and noise (i.e. 'useless' story components) impact the ability for LSTMs / GRUs to provide the correct answer. Given only the supporting facts, these RNNs can achieve 100% accuracy on many tasks. Memory networks and neural networks that use attentional processes can efficiently search through this noise to find the relevant statements, improving performance substantially. This becomes especially obvious on QA2 and QA3, both far longer than QA1. '''
with tarfile.open(path) as tar: train = get_stories(tar.extractfile(challenge.format('train')), only_supporting=True) test = get_stories(tar.extractfile(challenge.format('test')), only_supporting=True)
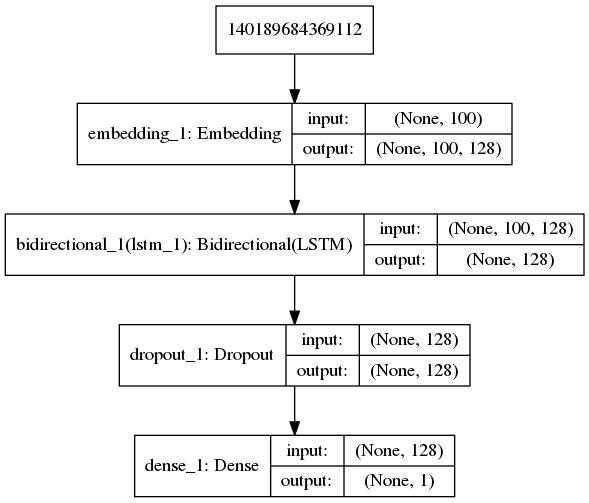
Trains a memory network on the bAbI dataset for reading comprehension.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
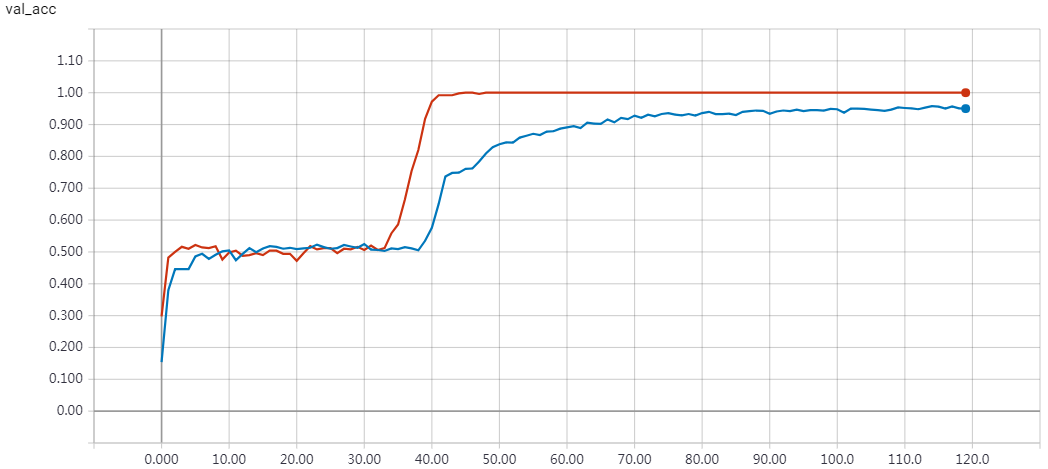
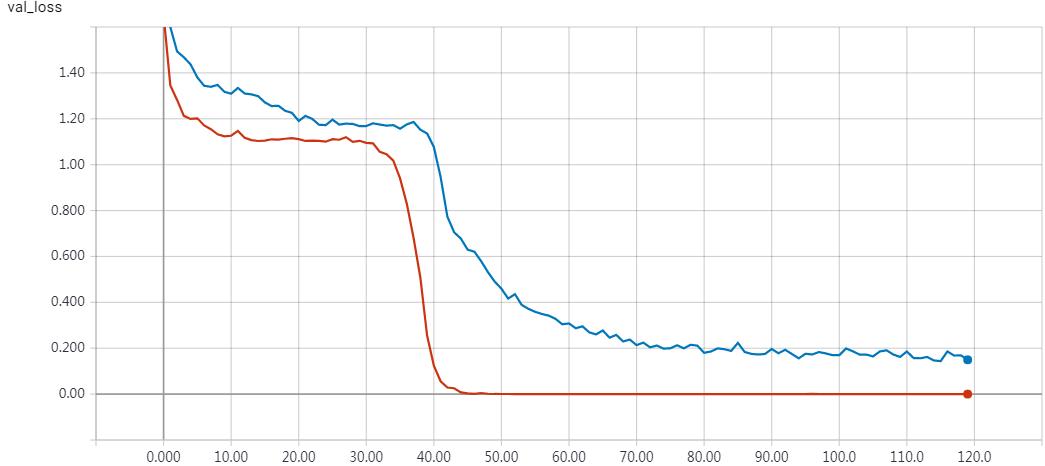
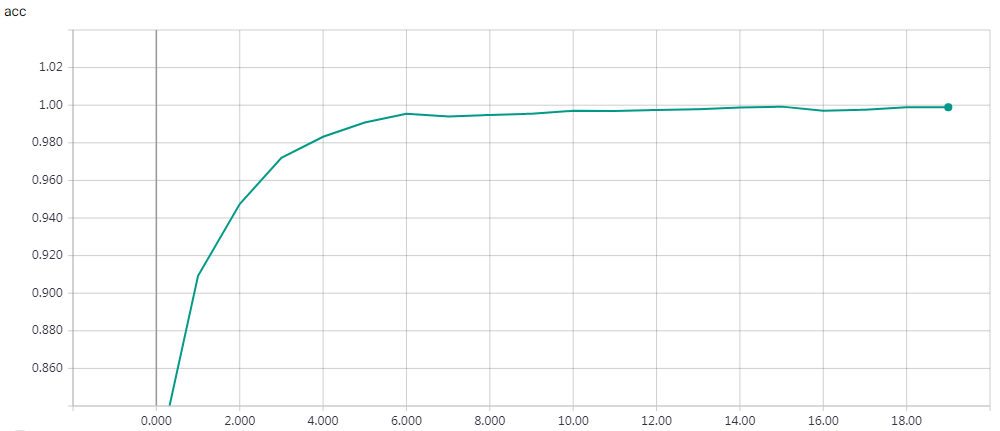
'''Trains a memory network on the bAbI dataset. References: - Jason Weston, Antoine Bordes, Sumit Chopra, Tomas Mikolov, Alexander M. Rush, "Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks", http://arxiv.org/abs/1502.05698 - Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus, "End-To-End Memory Networks", http://arxiv.org/abs/1503.08895 Reaches 98.6% accuracy on task 'single_supporting_fact_10k' after 120 epochs. Time per epoch: 3s on CPU (core i7). '''
Trains a FastText model on the IMDB sentiment classification task.
1 2 3 4 5 6 7 8 9 10 11
'''This example demonstrates the use of fasttext for text classification Based on Joulin et al's paper: Bags of Tricks for Efficient Text Classification https://arxiv.org/abs/1607.01759 Results on IMDB datasets with uni and bi-gram embeddings: Uni-gram: 0.8813 test accuracy after 5 epochs. 8s/epoch on i7 cpu. Bi-gram : 0.9056 test accuracy after 5 epochs. 2s/epoch on GTx 980M gpu. '''
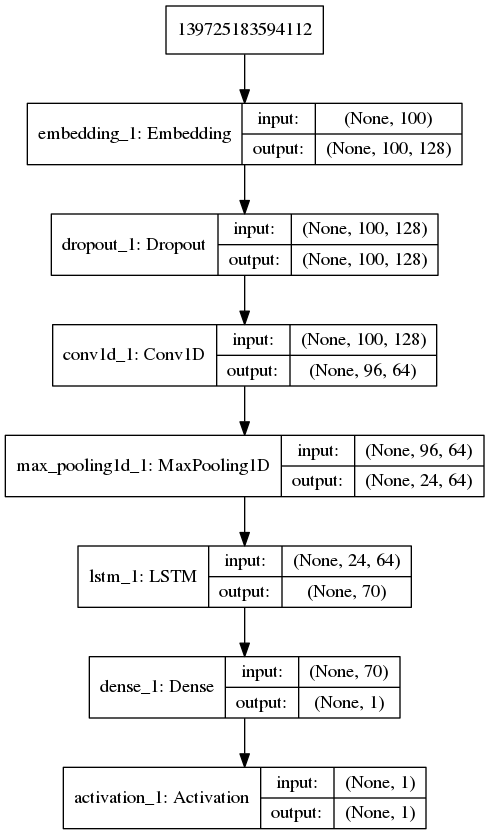
Trains an LSTM model on the IMDB sentiment classification task.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
'''Trains an LSTM model on the IMDB sentiment classification task. The dataset is actually too small for LSTM to be of any advantage compared to simpler, much faster methods such as TF-IDF + LogReg. # Notes - RNNs are tricky. Choice of batch size is important, choice of loss and optimizer is critical, etc. Some configurations won't converge. - LSTM loss decrease patterns during training can be quite different from what you see with CNNs/MLPs/etc. '''
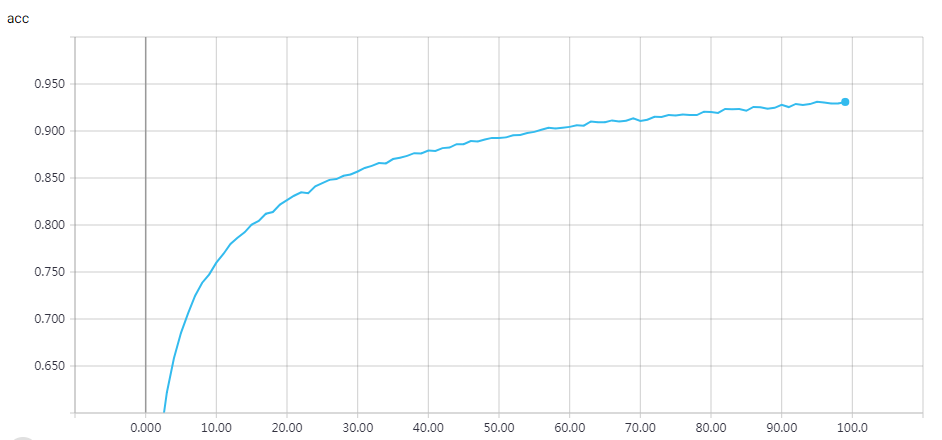
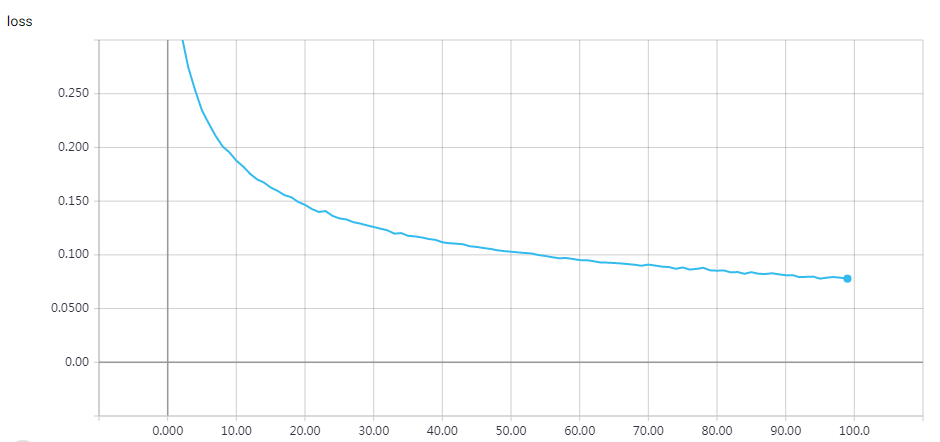
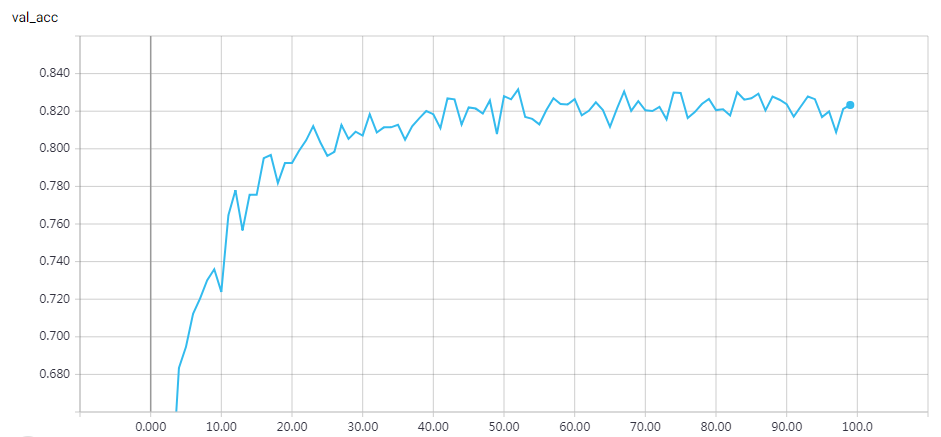
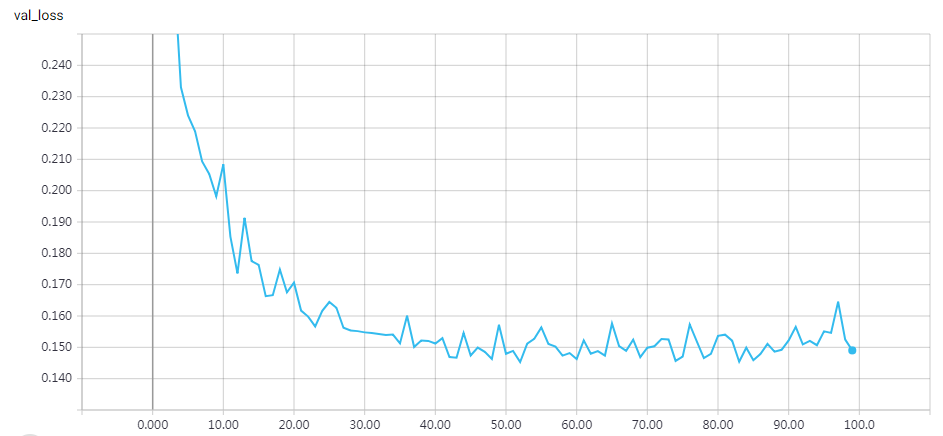
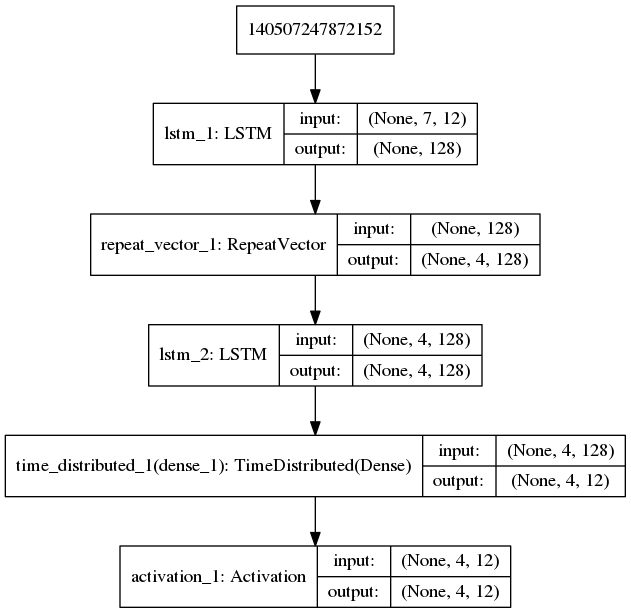
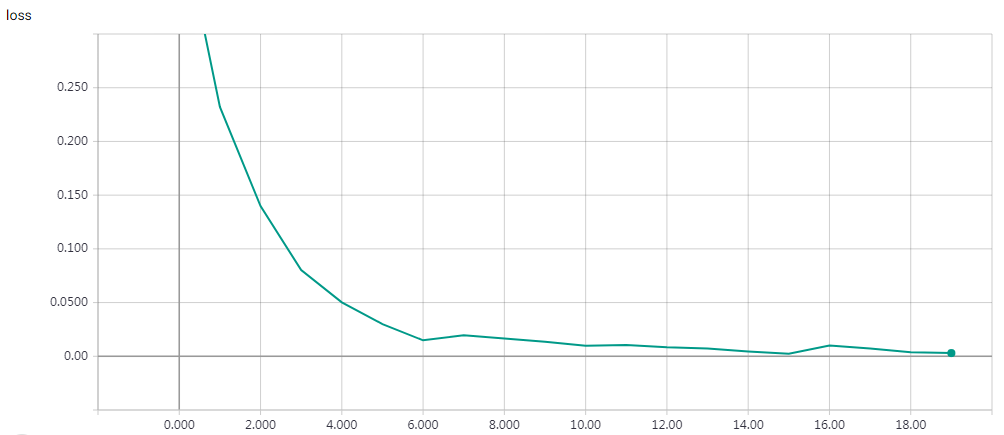
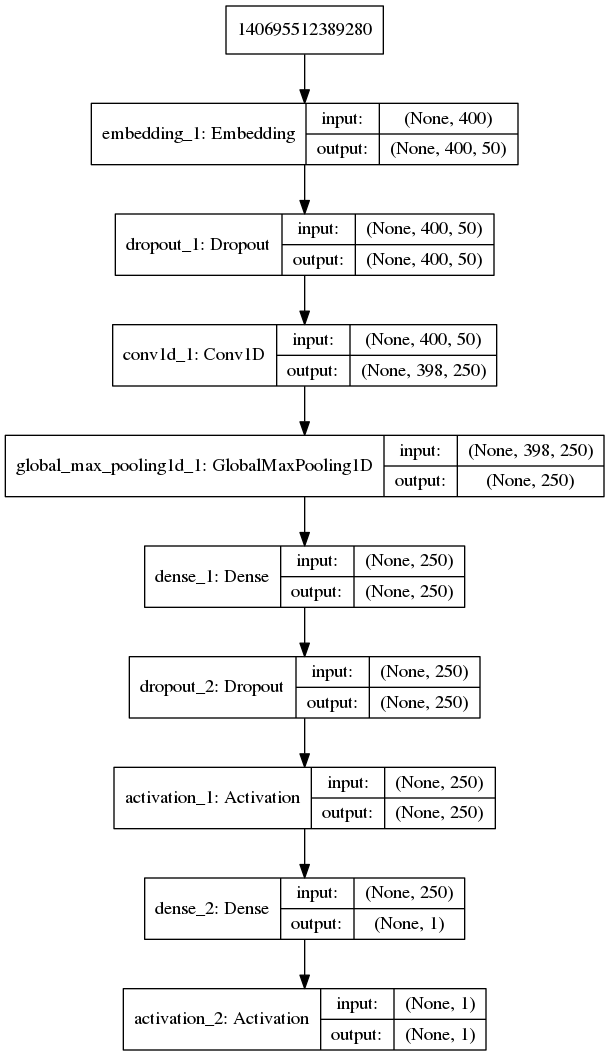
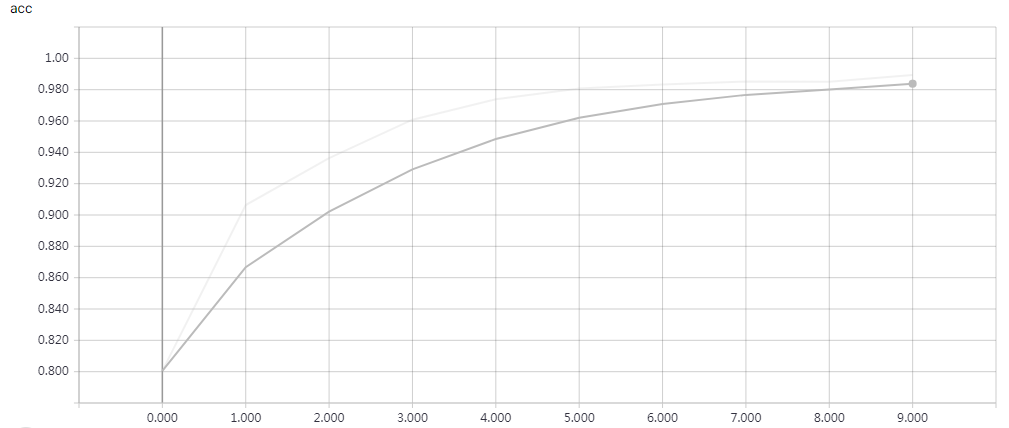
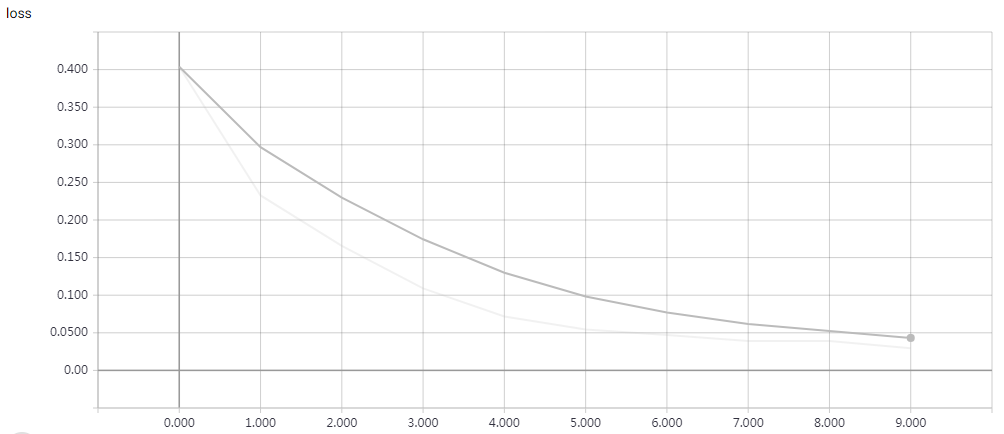
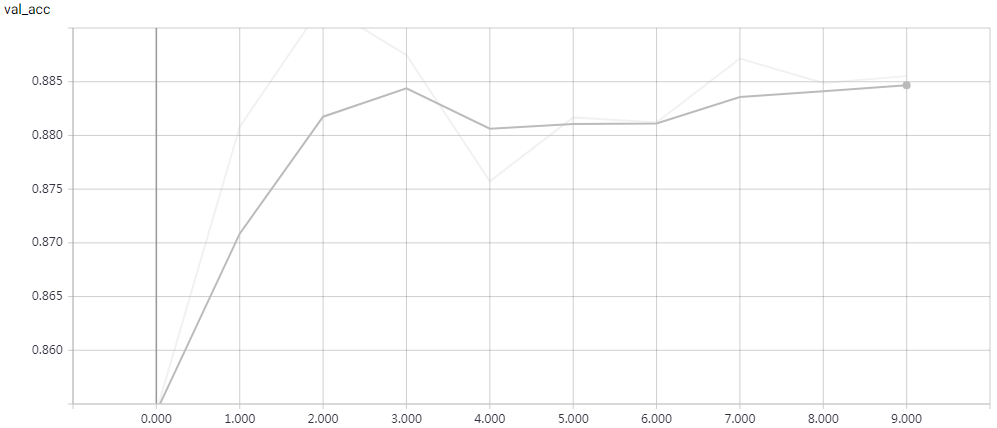
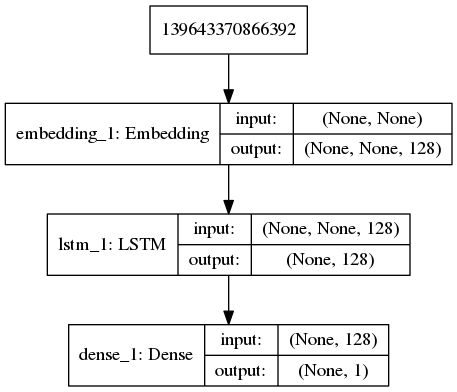
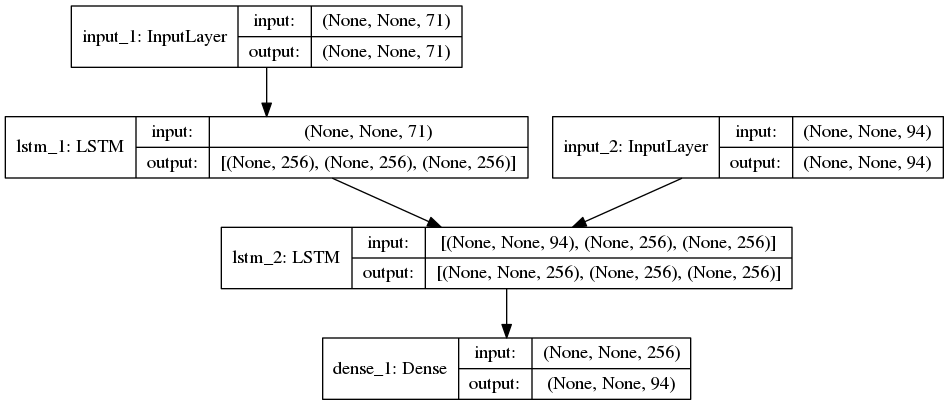
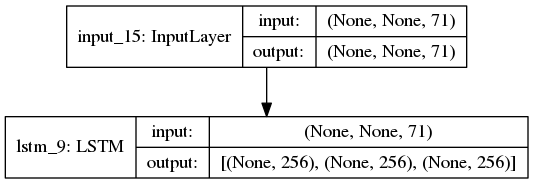
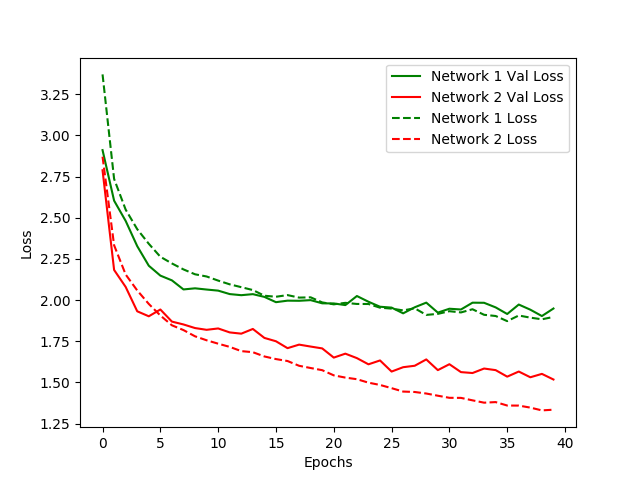
网络结构
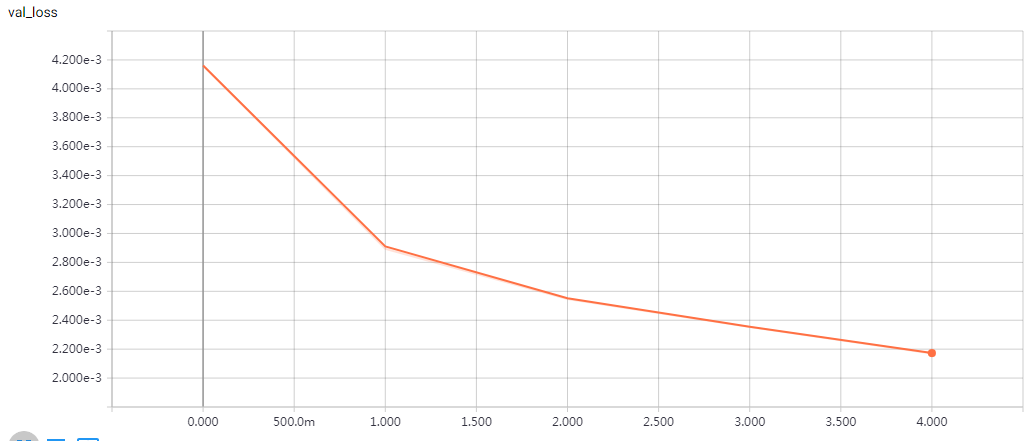
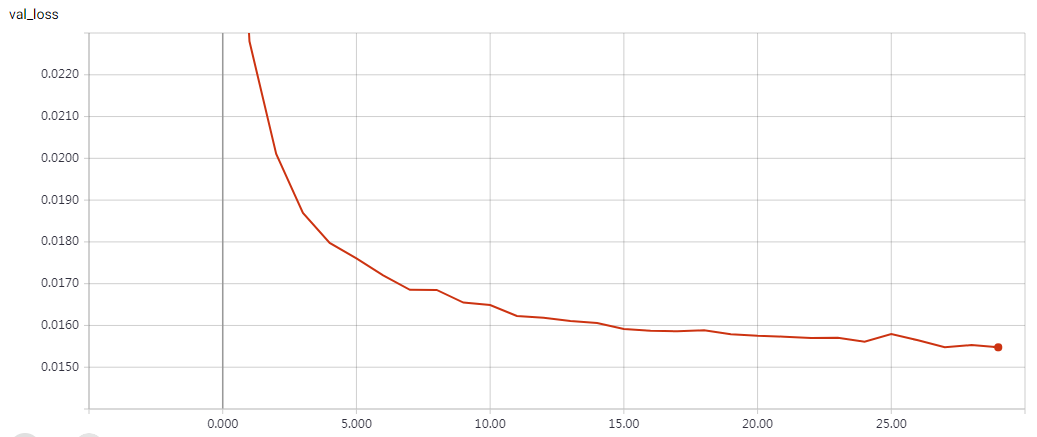
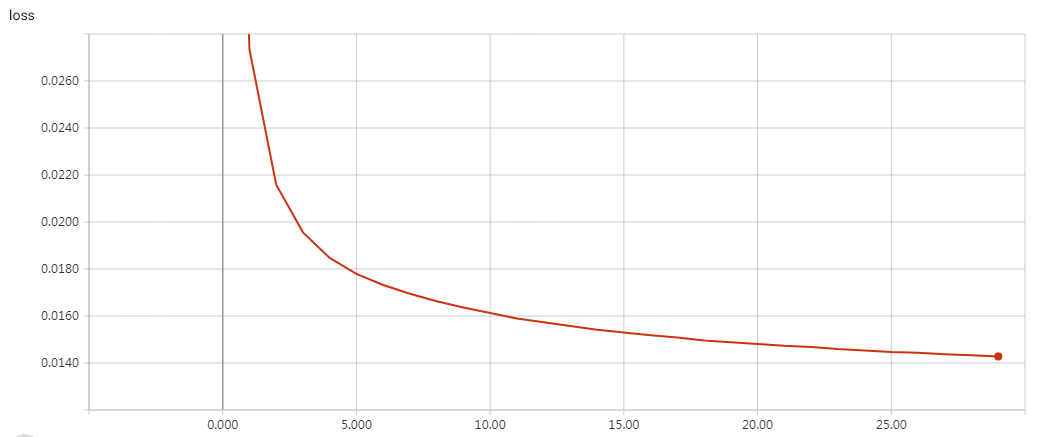
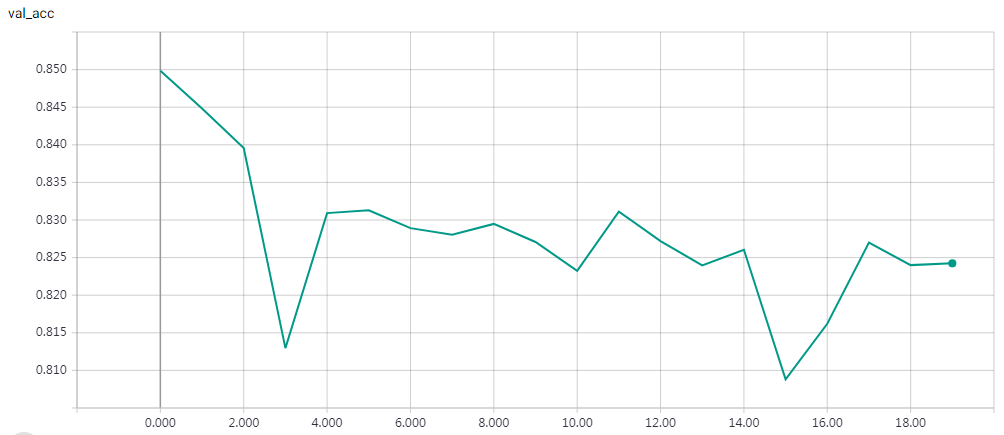
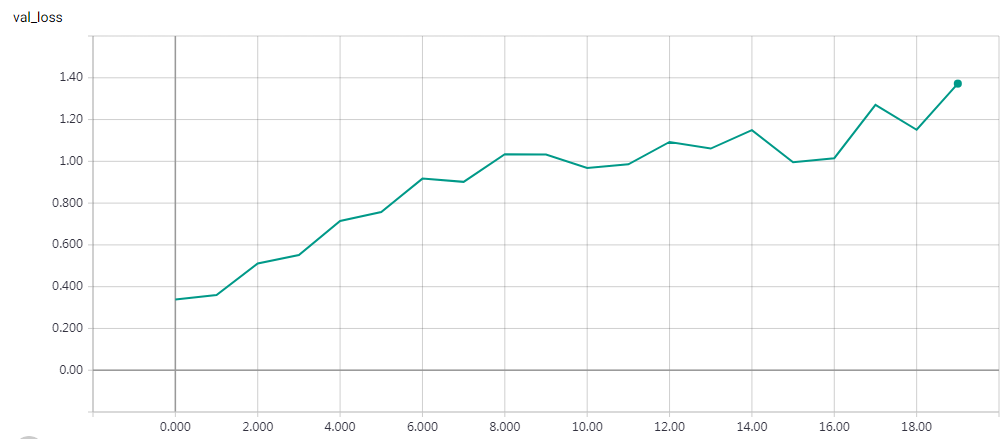
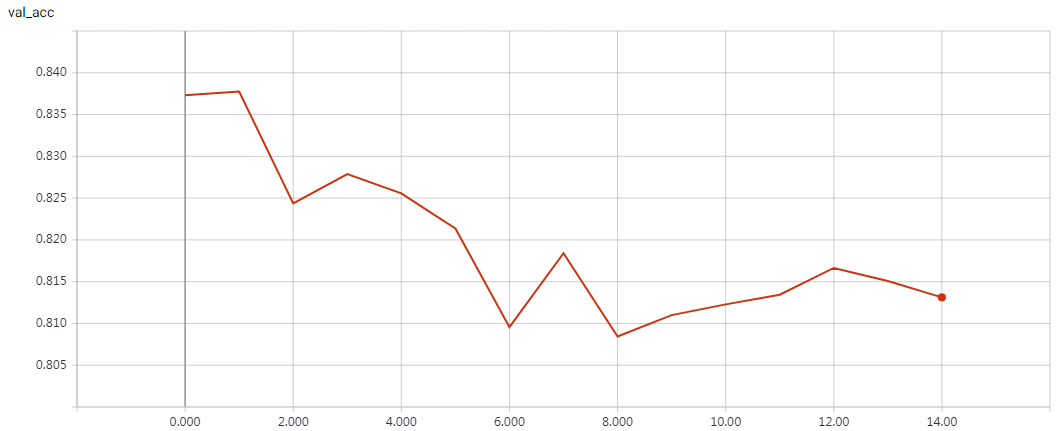
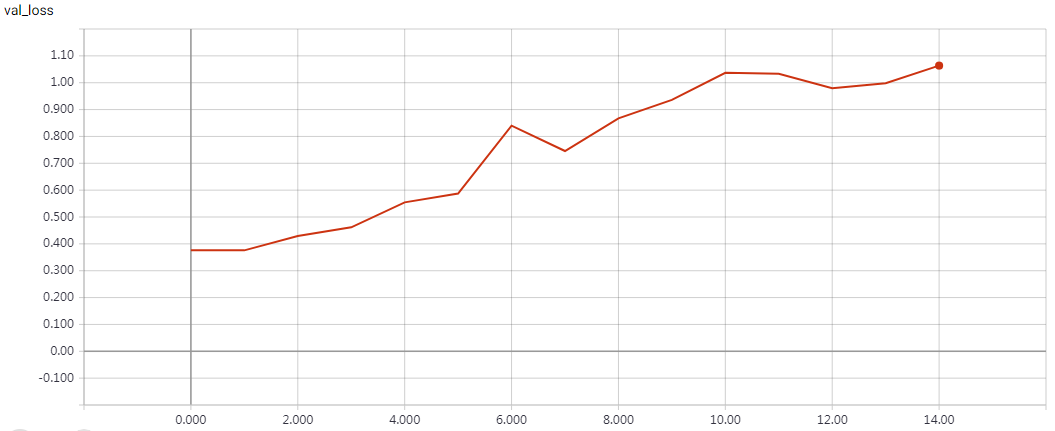
实验结果
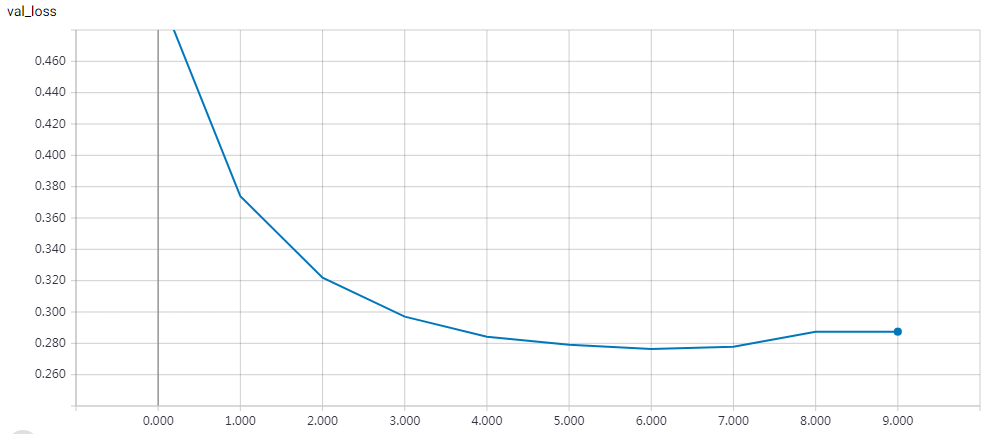
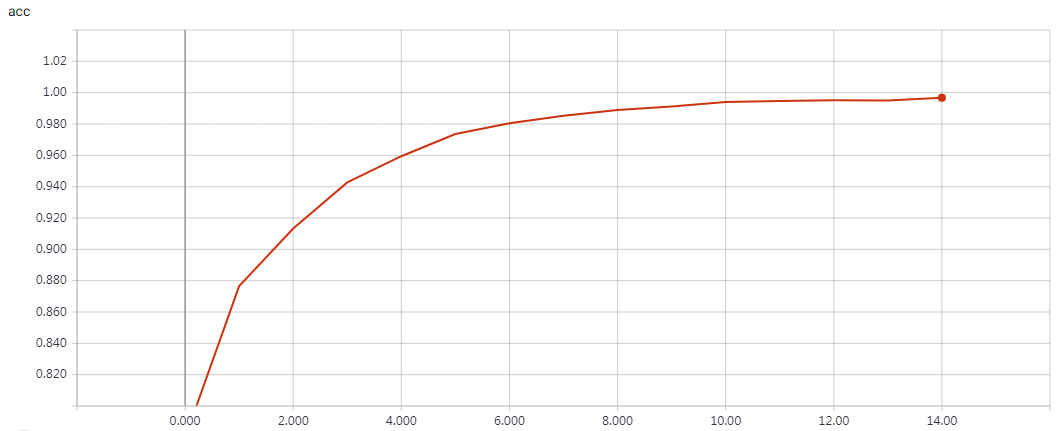
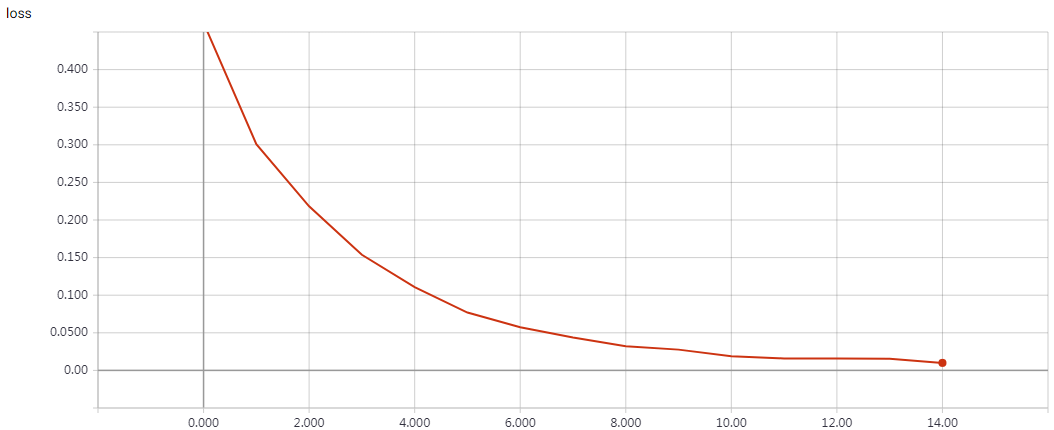
epochs=15 Test accuracy: 0.81312
lstm_stateful.py Demonstrates how to use stateful RNNs to model long sequences efficiently.
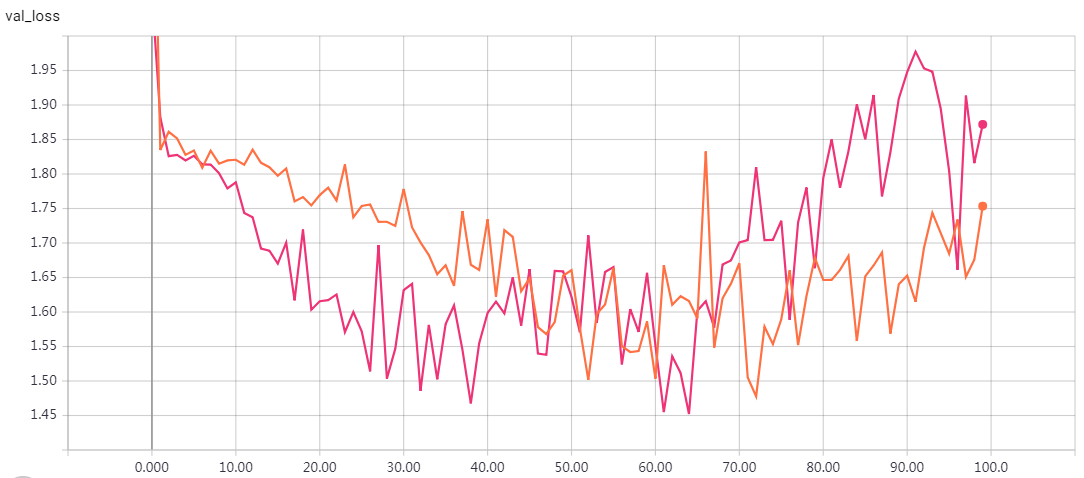
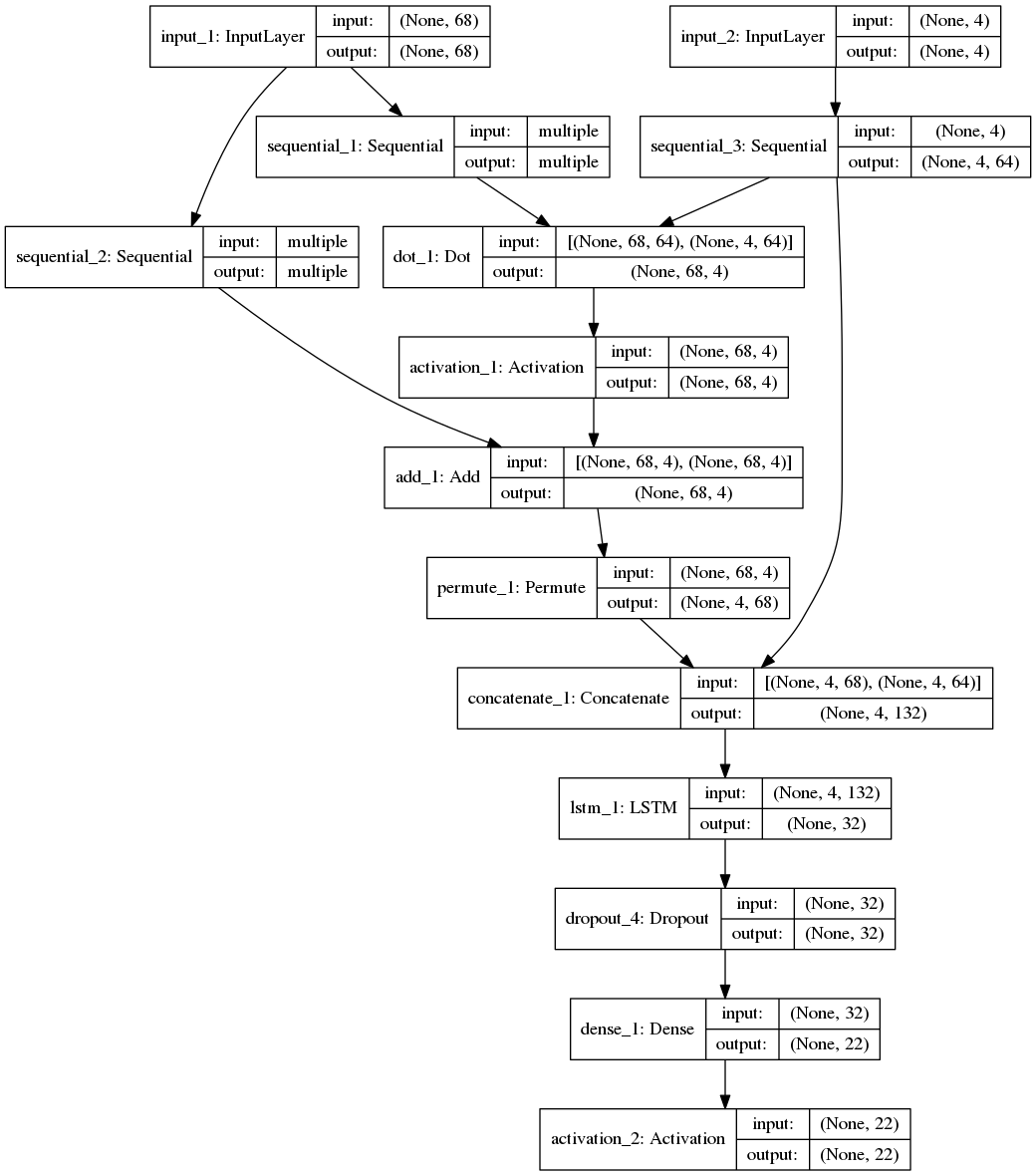
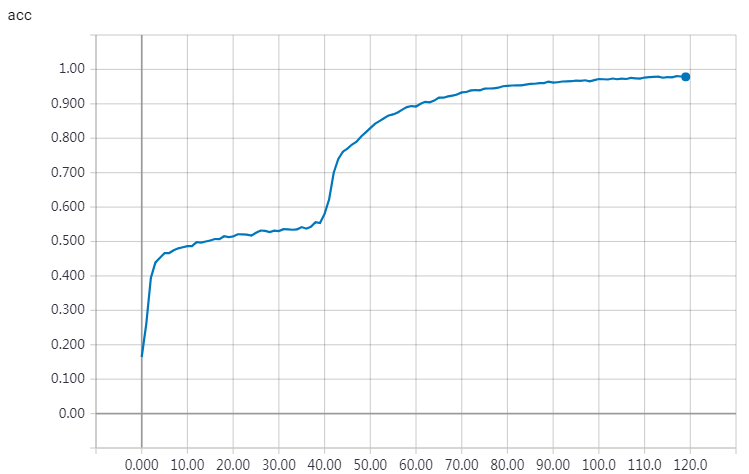
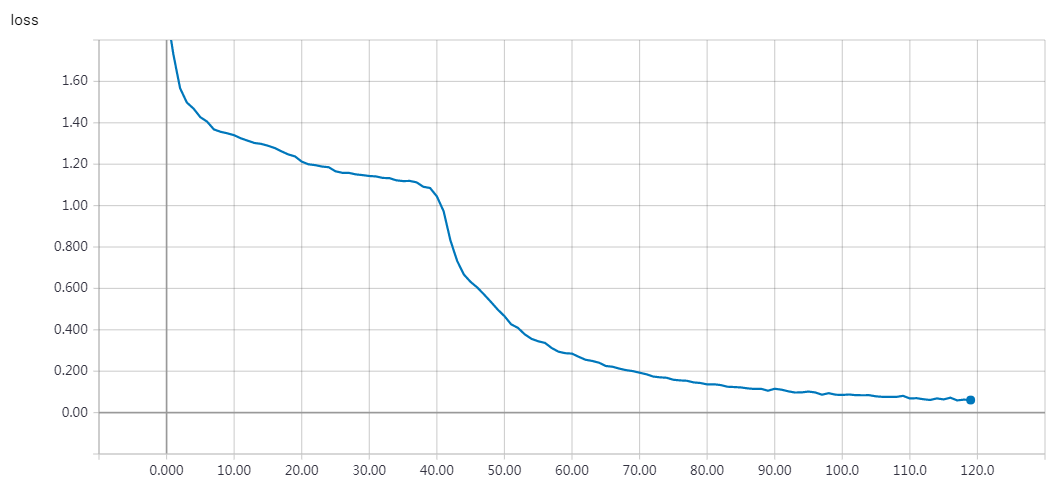
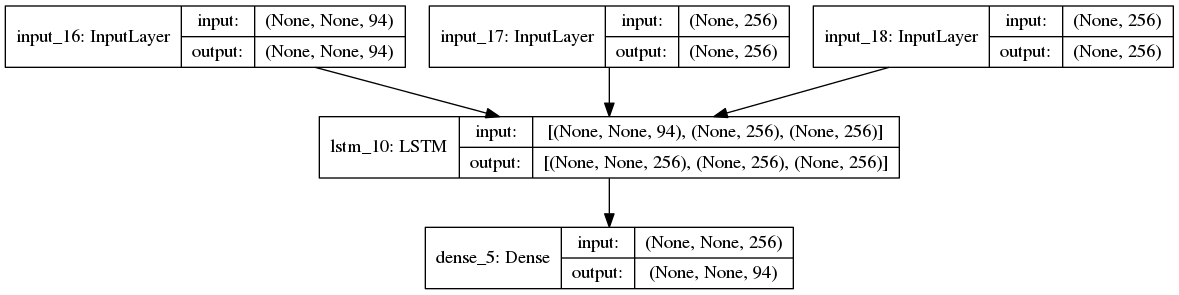
'''Sequence to sequence example in Keras (character-level). This script demonstrates how to implement a basic character-level sequence-to-sequence model. We apply it to translating short English sentences into short French sentences, character-by-character. Note that it is fairly unusual to do character-level machine translation, as word-level models are more common in this domain. # Summary of the algorithm - We start with input sequences from a domain (e.g. English sentences) and corresponding target sequences from another domain (e.g. French sentences). - An encoder LSTM turns input sequences to 2 state vectors (we keep the last LSTM state and discard the outputs). - A decoder LSTM is trained to turn the target sequences into the same sequence but offset by one timestep in the future, a training process called "teacher forcing" in this context. Is uses as initial state the state vectors from the encoder. Effectively, the decoder learns to generate `targets[t+1...]` given `targets[...t]`, conditioned on the input sequence. - In inference mode, when we want to decode unknown input sequences, we: - Encode the input sequence into state vectors - Start with a target sequence of size 1 (just the start-of-sequence character) - Feed the state vectors and 1-char target sequence to the decoder to produce predictions for the next character - Sample the next character using these predictions (we simply use argmax). - Append the sampled character to the target sequence - Repeat until we generate the end-of-sequence character or we hit the character limit. # Data download English to French sentence pairs. http://www.manythings.org/anki/fra-eng.zip Lots of neat sentence pairs datasets can be found at: http://www.manythings.org/anki/ # References - Sequence to Sequence Learning with Neural Networks https://arxiv.org/abs/1409.3215 - Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation https://arxiv.org/abs/1406.1078 '''
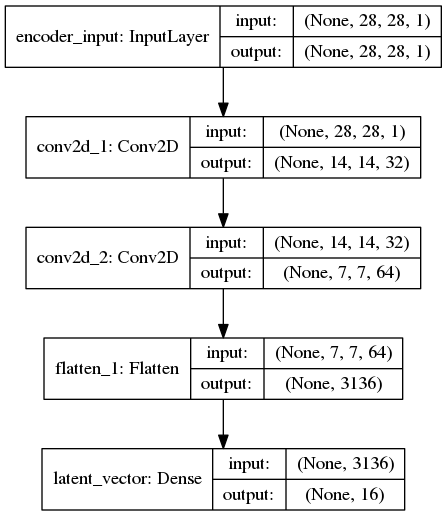
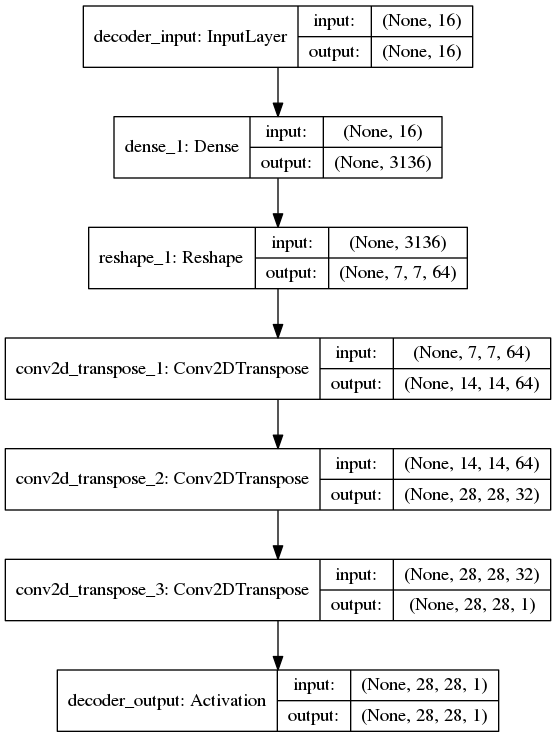
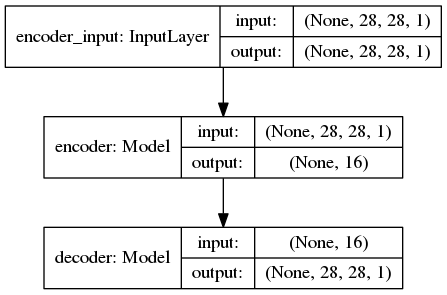
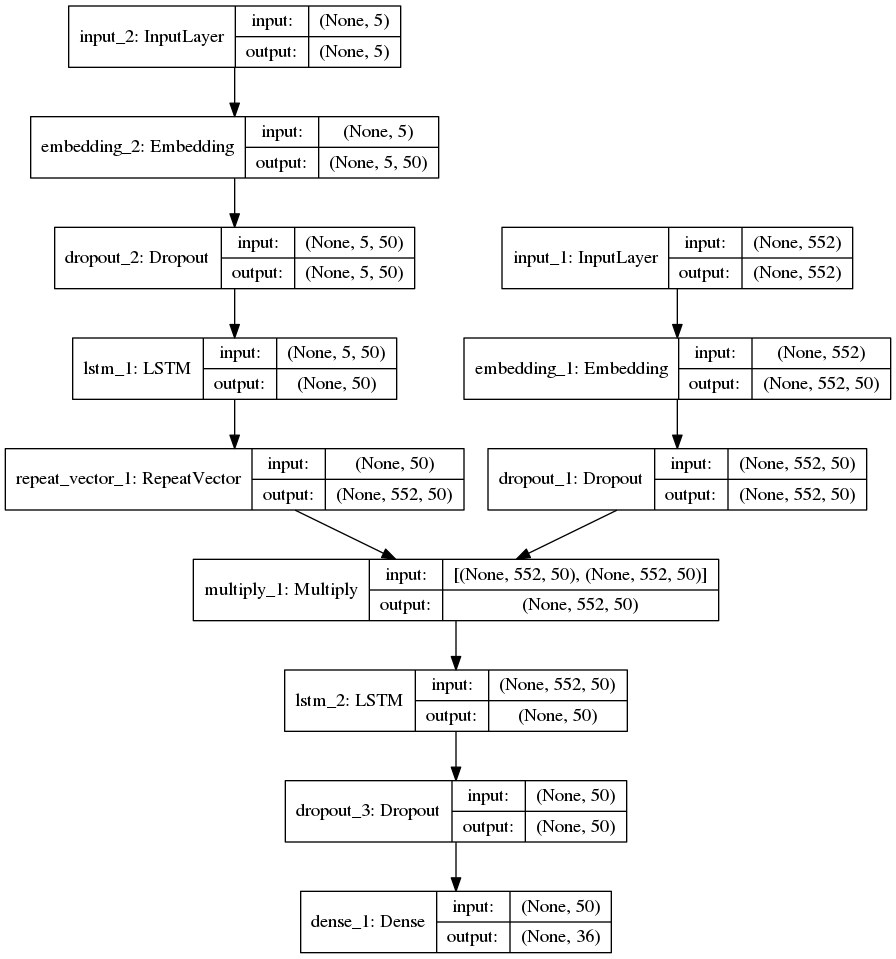
网络结构
编码器
解码器
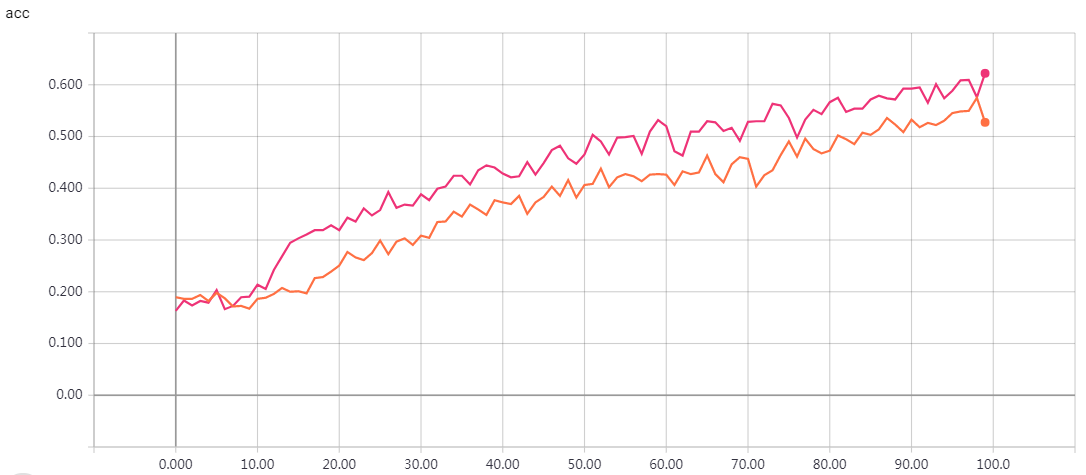
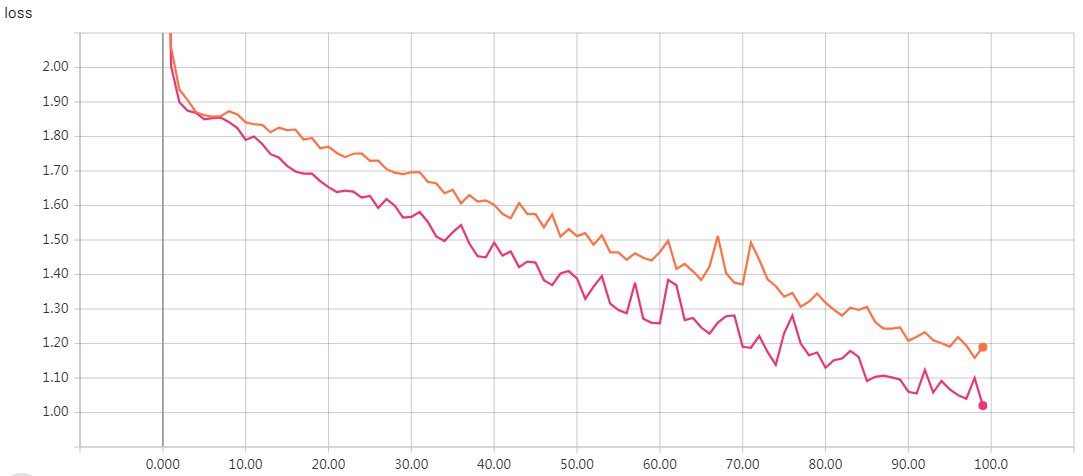
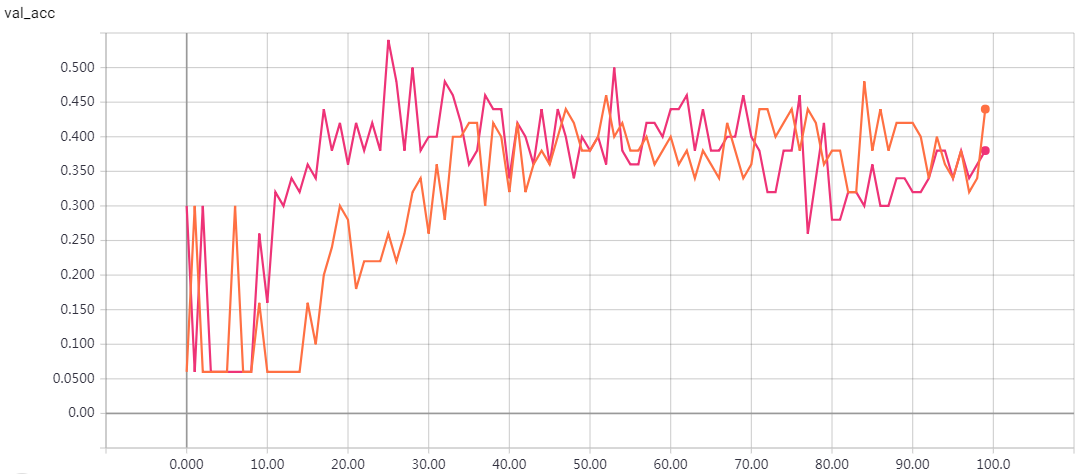
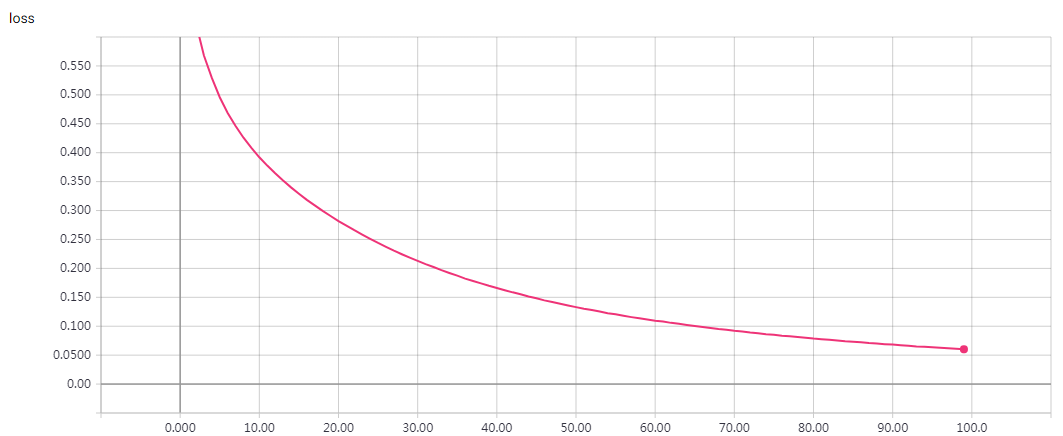
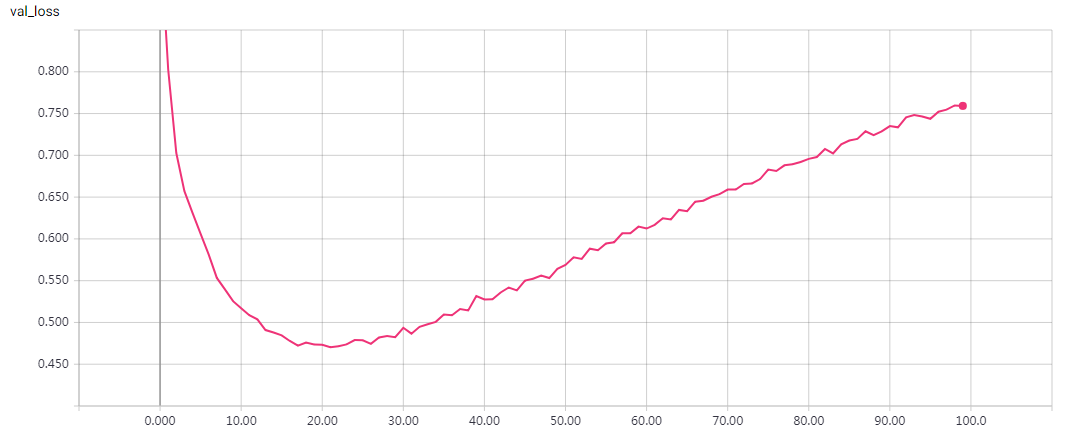
实验结果
epochs=100 loss: 0.0602 - val_loss: 0.7592
1 2 3 4 5 6 7 8 9
- Input sentence: Come in. Decoded sentence: Entrez ! - Input sentence: Come on! Decoded sentence: Viens ! - Input sentence: Drop it! Decoded sentence: Laisse tomber !
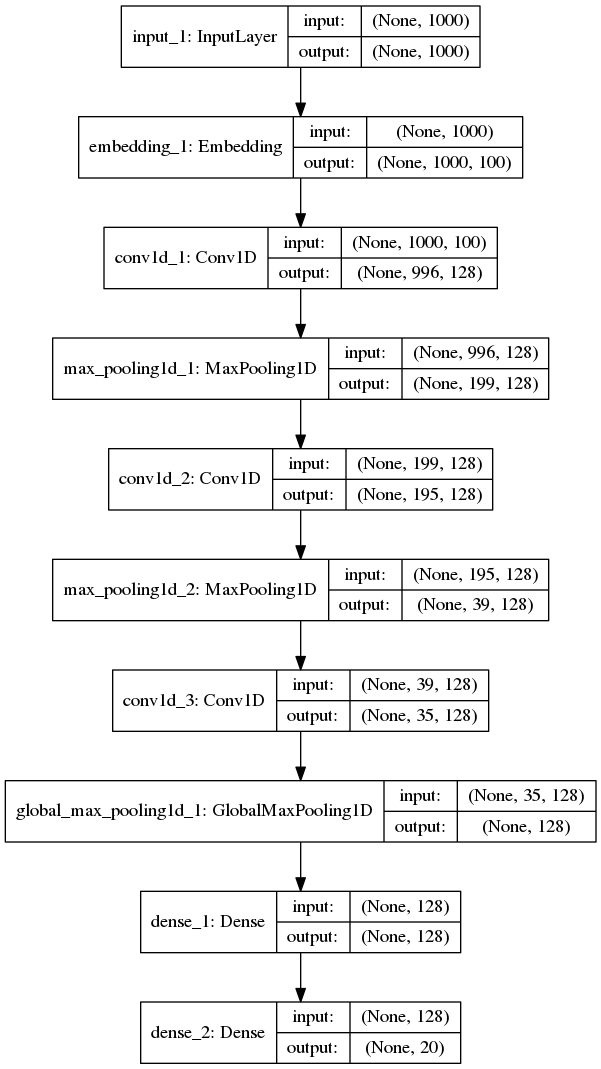
Loads pre-trained word embeddings (GloVe embeddings) into a frozen Keras Embedding layer, and uses it to train a text classification model on the 20 Newsgroup dataset.
Network 1 Relu Test score: 1.9769948146646827 Test accuracy: 0.5204808548796103 Network 2 Selu Test score: 1.530816549927872 Test accuracy: 0.6714158504007124
'''Example script to generate text from Nietzsche's writings. At least 20 epochs are required before the generated text starts sounding coherent. It is recommended to run this script on GPU, as recurrent networks are quite computationally intensive. If you try this script on new data, make sure your corpus has at least ~100k characters. ~1M is better. '''
网络结构
实验结果
1 2 3 4 5 6 7 8 9 10 11 12 13
----- Generating text after Epoch: 99 ----- diversity: 0.2 ----- Generating with seed: " of his tolerance and humanity which pro" of his tolerance and humanity which proe ee e e e ee e ee et e ee te ee e" ! esov ehe eeted en enete ee e e ee q te e t eeqo a x een x qe n et" ! ex if i tewn x .o e v - ' e ! q jj j s t qhi xh x ! tetsa k ewetce e e of eeh e e et i e ee e x ee eetk( e e n e x xo = x ! xvekne x e ) x qnb z ehe e n x )edxd xx x xi x x tcnwet x- 'e o q e te eto e x eti ' ----- diversity: 0.5 ----- Generating with seed: " of his tolerance and humanity which pro" of his tolerance and humanity which pro ee e e ee ee ee e beeee ee e ' xx z e e ' en qengg x x evo-n x ! xn 'o xb i it k x n x xbe a wee x tix e i t q etvece e etoe o z eet i q h wete eo xe'e e egovee ! e eese e oe xe x e e zd ti q n x ni tqj x a n zxb x x " x we n n x j e et z v ! xj an ee xq " q styiete nxe! x et ! i qt ta xbn tx ----- diversity: 1.0 ----- Generating with seed: " of his tolerance and humanity which pro" of his tolerance and humanity which proe eee ee eeeeee et eeeteeei ee (eeiiey qqe i n xxee x ue e jni " x xb z n n e in n e' ve te j e zw eeq(se t x q xve im:t x xxb tek x ehed te e't xheefe e-e xn e ebe eey zn xeg:ti xbs xvfete x !o ee- e e e o e we e ese eet -e oee e x (xb e ee necf e j e e ( ee je ie este)n ax q n . xjf z xi o t xxv x xnocese i ----- diversity: 1.2 ----- Generating with seed: " of his tolerance and humanity which pro" of his tolerance and humanity which pro eeeee eee e e e tetee" e eteeee-e i eex o xhe ee x e on e te"( t x xg e i hek.tni etf xiecnne evet ecewe e e o ec ? e;e ,ee e e ee e;skyn xe e e x xte he et i q x jw w xn xn e x ' q= t o n nex e =tho xenwei ao? x zn x evq ety q x x et e es be d x xq ie n xetzo ke q y etx xt xsn inn eti e x ei eq t
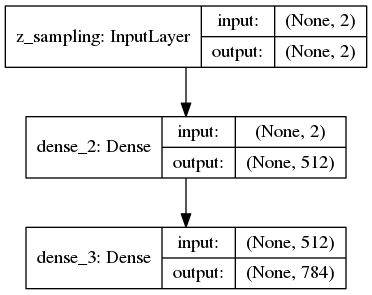
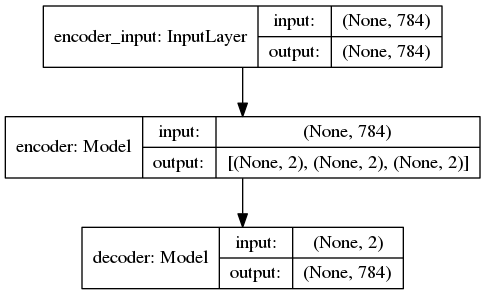
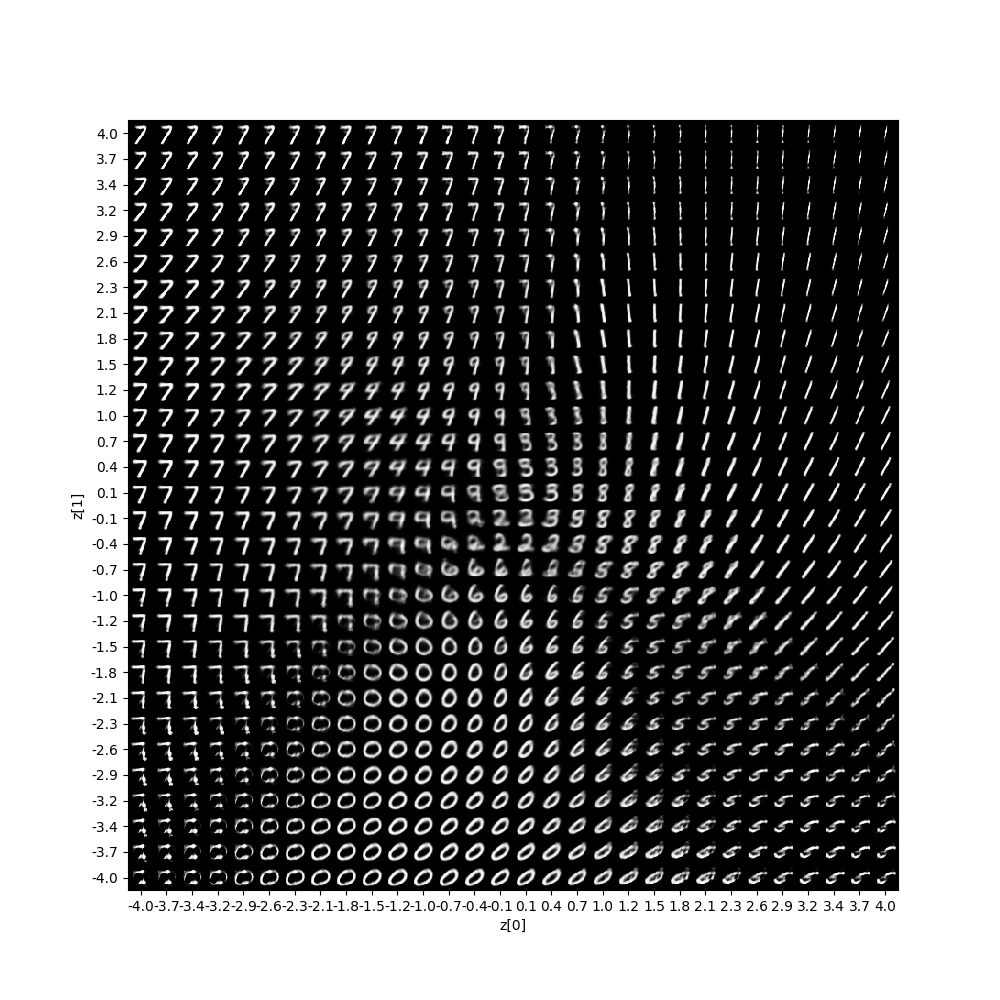
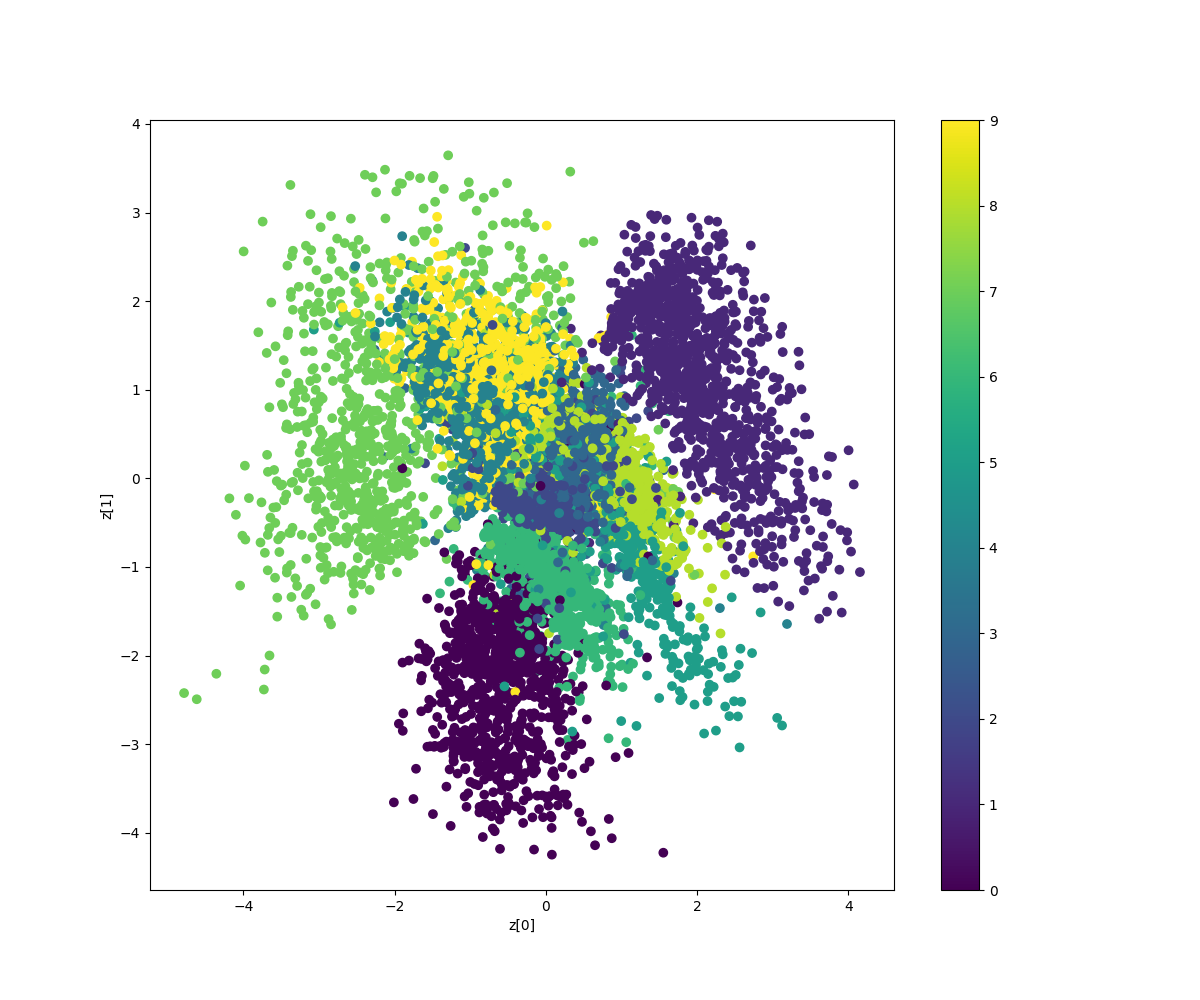
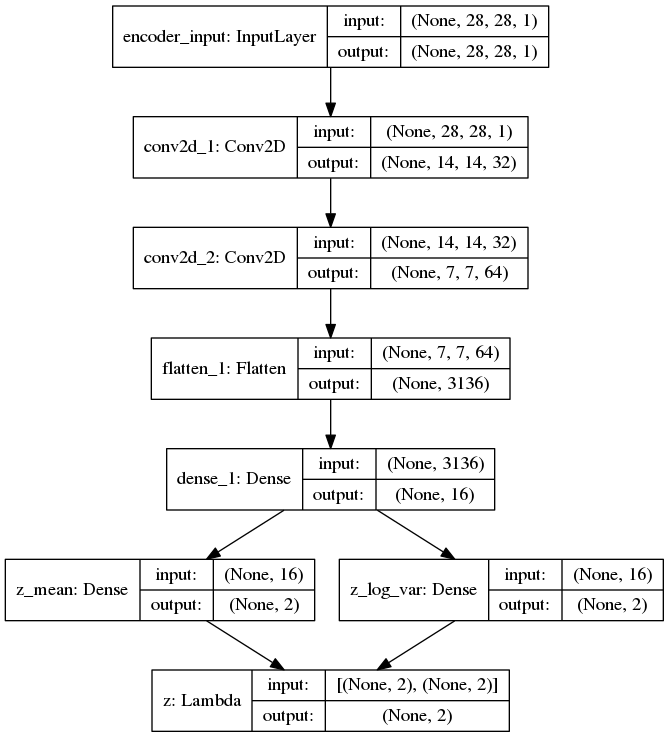
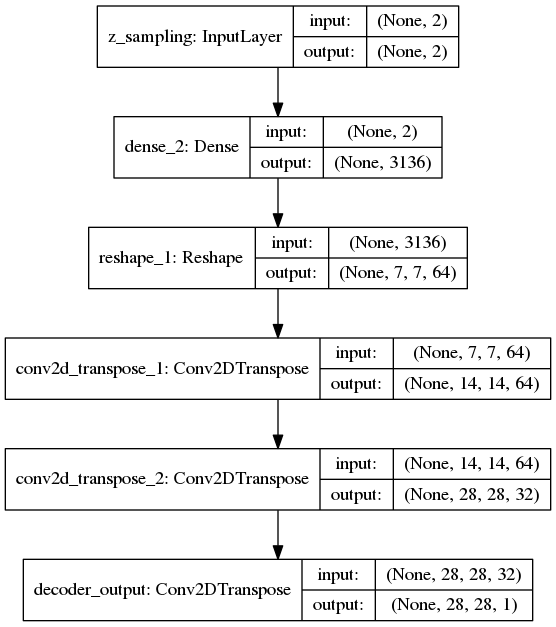
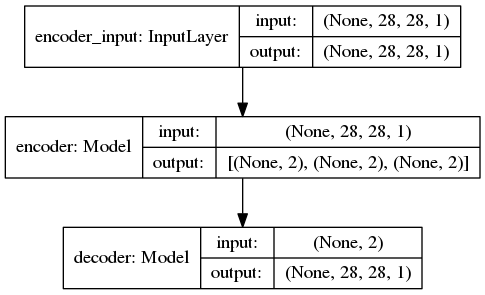
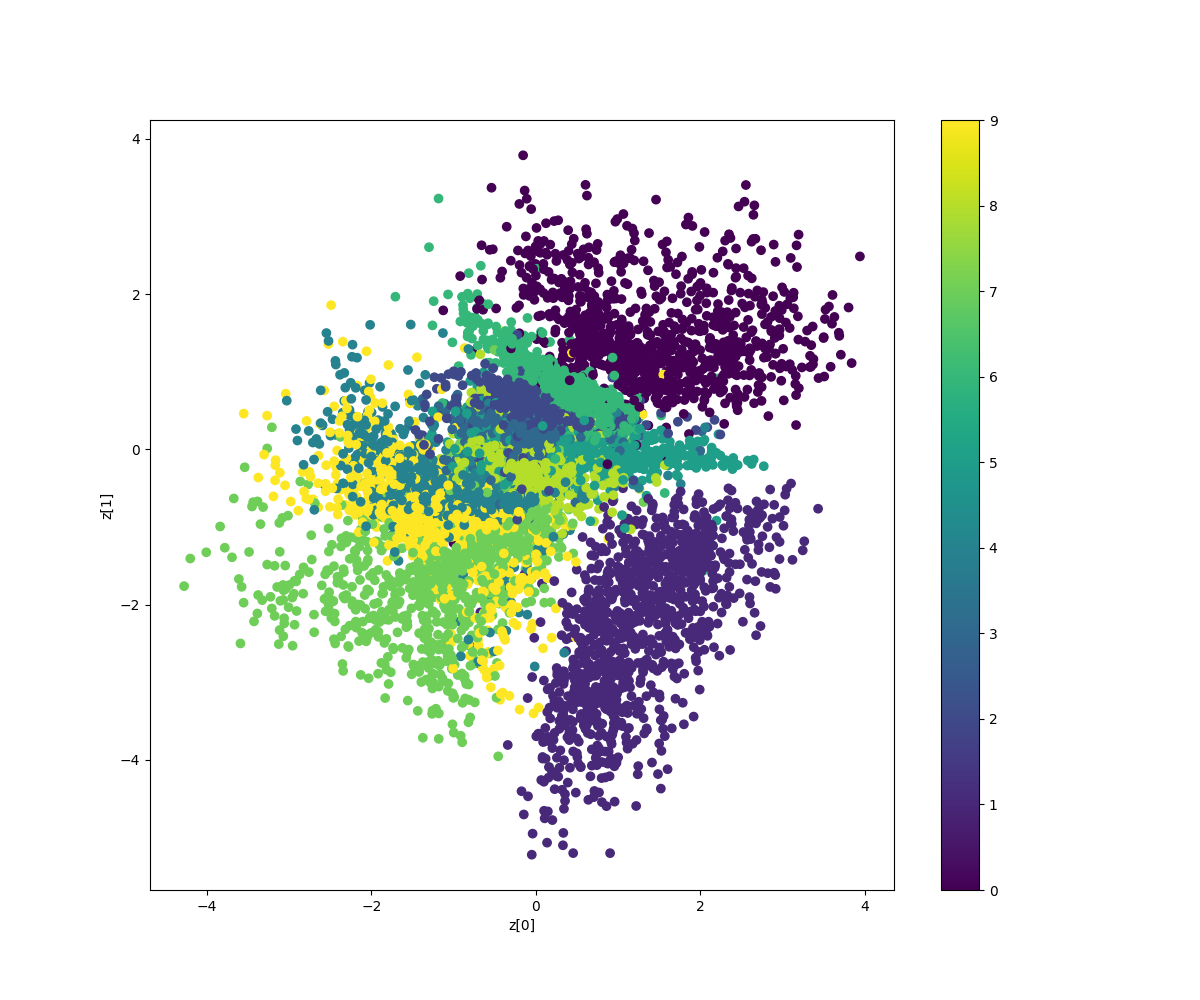
Demonstrates how to build a variational autoencoder.
1 2 3 4 5 6 7 8 9 10 11 12 13
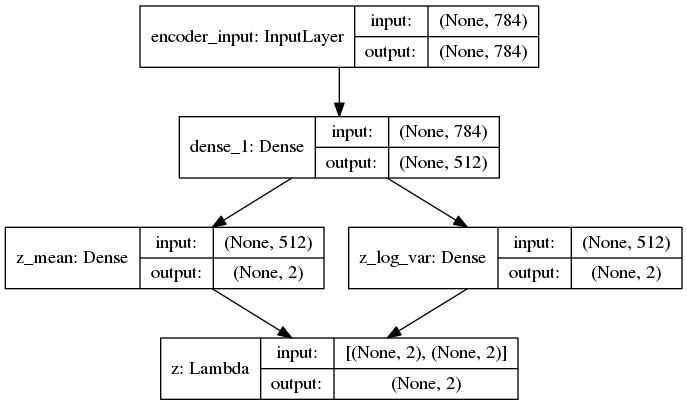
'''Example of VAE on MNIST dataset using MLP The VAE has a modular design. The encoder, decoder and VAE are 3 models that share weights. After training the VAE model, the encoder can be used to generate latent vectors. The decoder can be used to generate MNIST digits by sampling the latent vector from a Gaussian distribution with mean=0 and std=1. **Reference:** [1] Kingma, Diederik P., and Max Welling. "Auto-encoding variational bayes." https://arxiv.org/abs/1312.6114 '''
Demonstrates how to build a variational autoencoder with Keras using deconvolution layers.
‘’’Example of VAE on MNIST dataset using CNN The VAE has a modular design. The encoder, decoder and VAE are 3 models that share weights. After training the VAE model, the encoder can be used to generate latent vectors. The decoder can be used to generate MNIST digits by sampling the latent vector from a Gaussian distribution with mean=0 and std=1.
Demonstrates how to write custom layers for Keras.
1 2 3 4 5 6 7 8 9 10 11
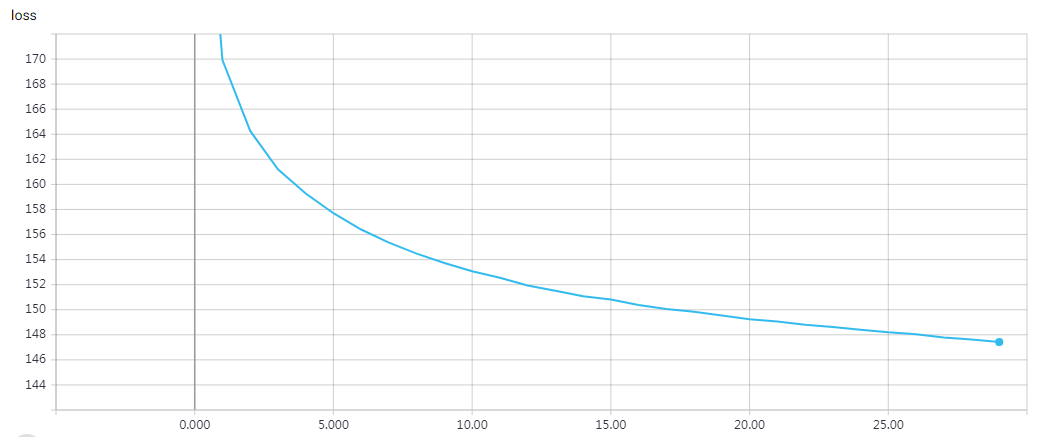
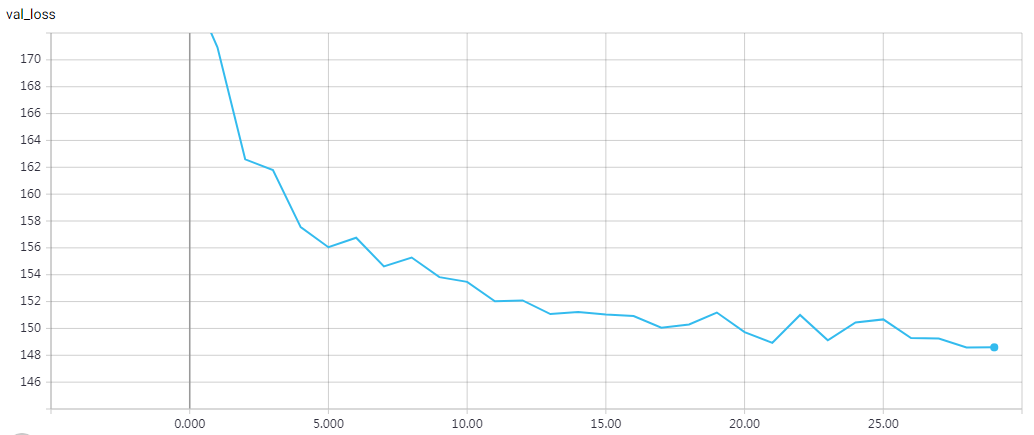
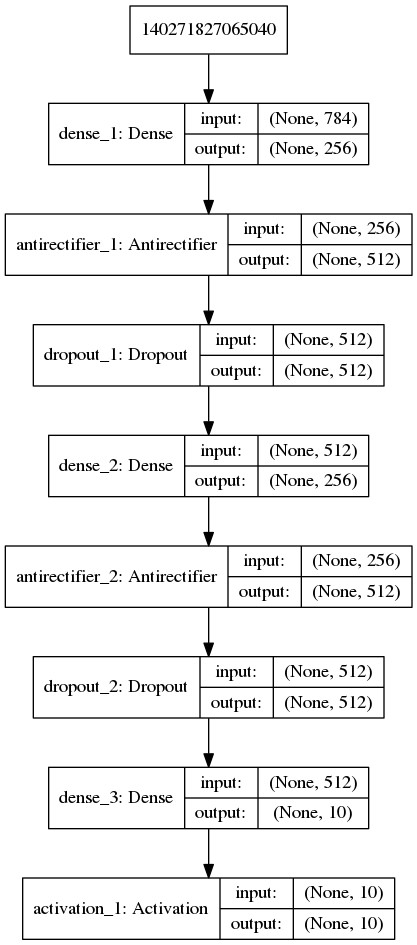
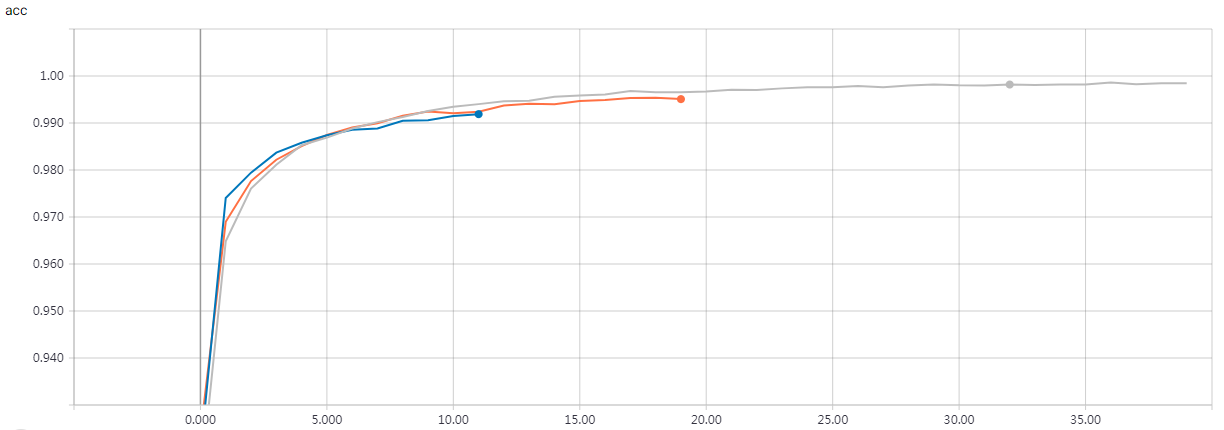
'''The example demonstrates how to write custom layers for Keras. We build a custom activation layer called 'Antirectifier', which modifies the shape of the tensor that passes through it. We need to specify two methods: `compute_output_shape` and `call`. Note that the same result can also be achieved via a Lambda layer. Because our custom layer is written with primitives from the Keras backend (`K`), our code can run both on TensorFlow and Theano. '''
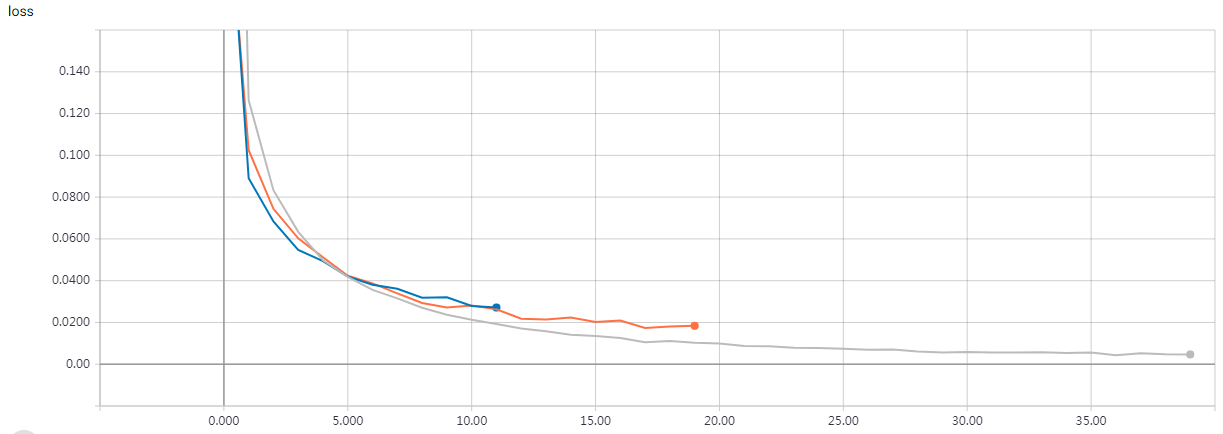
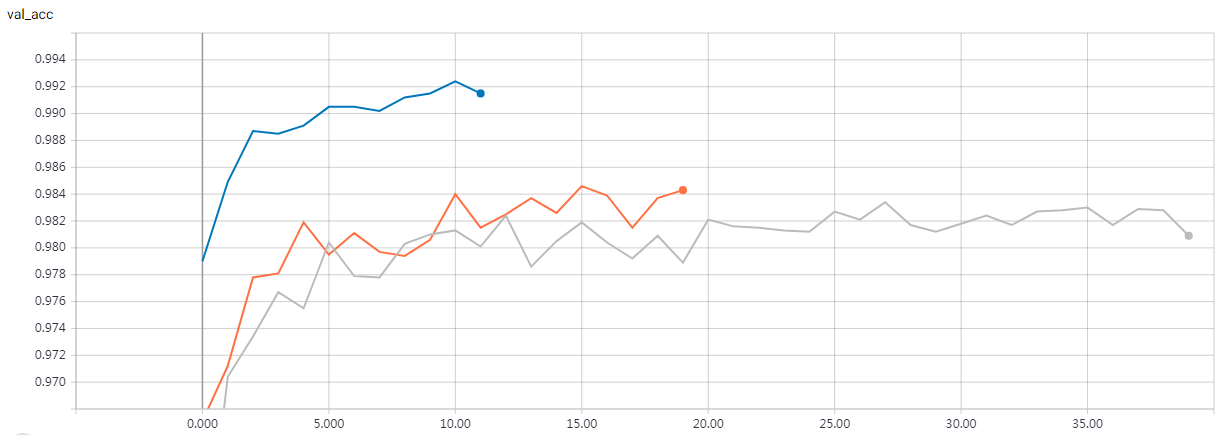
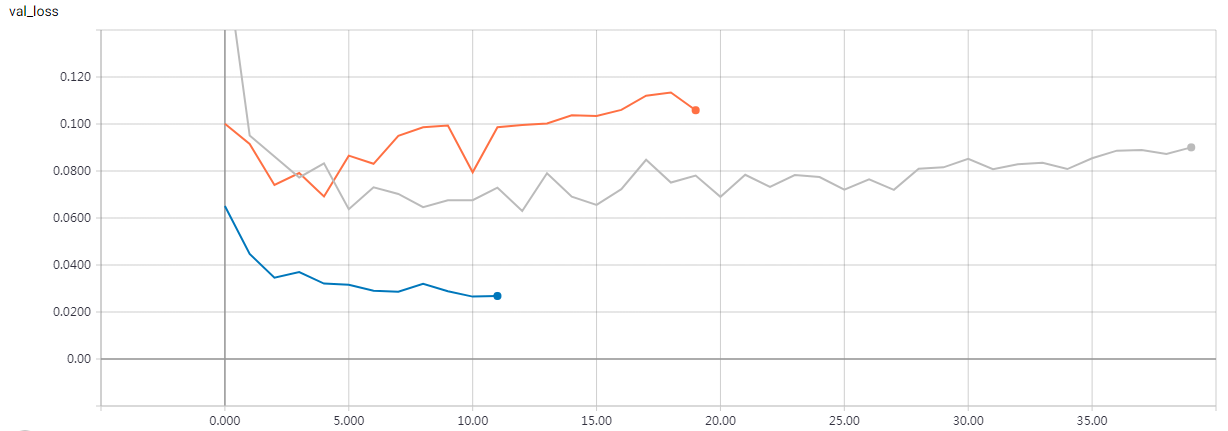
Builds simple CNN models on MNIST and uses sklearn's GridSearchCV to find best model '''
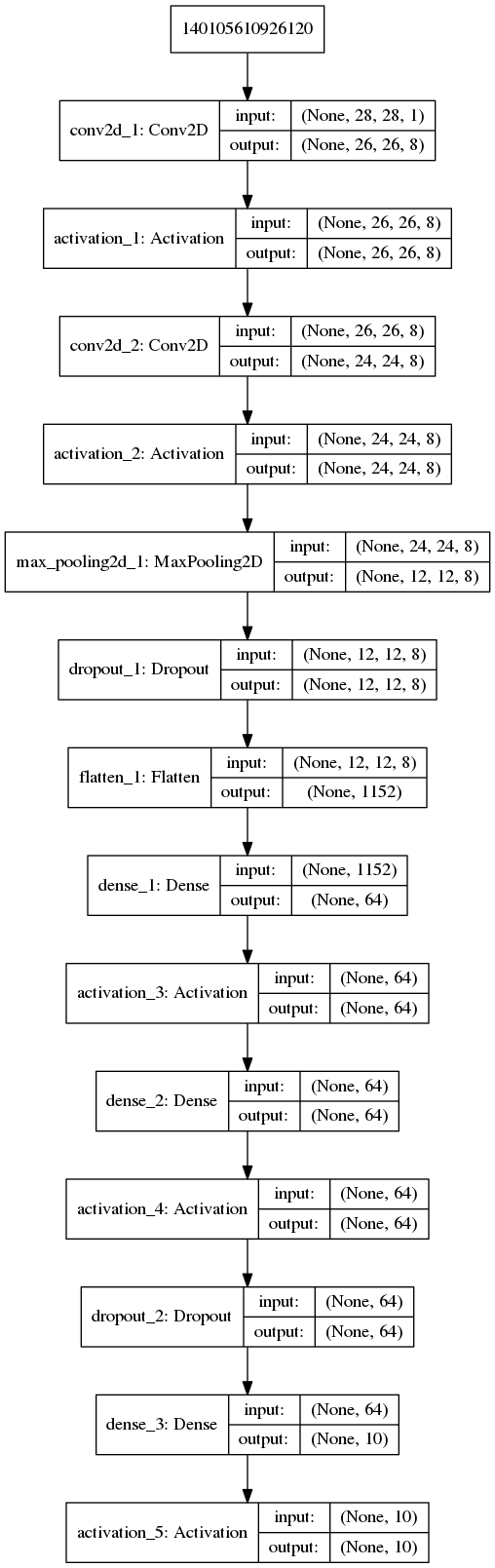
网络结构
实验结果
1 2 3 4
The parameters of the best model are: {'dense_layer_sizes': [64, 64], 'epochs': 6, 'filters': 8, 'kernel_size': 3, 'pool_size': 2} loss : 0.042469549842912235 acc : 0.9872
mnist_irnn.py Reproduction of the IRNN experiment with pixel-by-pixel sequential MNIST in “A Simple Way to Initialize Recurrent Networks of Rectified Linear Units” by Le et al.
mnist_net2net.py Reproduction of the Net2Net experiment with MNIST in “Net2Net: Accelerating Learning via Knowledge Transfer”.
'''Train a simple deep CNN on the CIFAR10 small images dataset. Using Tensorflow internal augmentation APIs by replacing ImageGenerator with an embedded AugmentLayer using LambdaLayer, which is faster on GPU. # Benchmark of `ImageGenerator` vs `AugmentLayer` both using augmentation 2D: (backend = Tensorflow-GPU, Nvidia Tesla P100-SXM2) Settings: horizontal_flip = True ---------------------------------------------------------------------------- Epoch | ImageGenerator | ImageGenerator | AugmentLayer | Augment Layer Number | %Accuracy | Performance | %Accuracy | Performance ---------------------------------------------------------------------------- 1 | 44.84 | 15ms/step | 45.54 | 358us/step 2 | 52.34 | 8ms/step | 50.55 | 285us/step 8 | 65.45 | 8ms/step | 65.59 | 281us/step 25 | 76.74 | 8ms/step | 76.17 | 280us/step 100 | 78.81 | 8ms/step | 78.70 | 285us/step --------------------------------------------------------------------------- Settings: rotation = 30.0 ---------------------------------------------------------------------------- Epoch | ImageGenerator | ImageGenerator | AugmentLayer | Augment Layer Number | %Accuracy | Performance | %Accuracy | Performance ---------------------------------------------------------------------------- 1 | 43.46 | 15ms/step | 42.21 | 334us/step 2 | 48.95 | 11ms/step | 48.06 | 282us/step 8 | 63.59 | 11ms/step | 61.35 | 290us/step 25 | 72.25 | 12ms/step | 71.08 | 287us/step 100 | 76.35 | 11ms/step | 74.62 | 286us/step --------------------------------------------------------------------------- (Corner process and rotation precision by `ImageGenerator` and `AugmentLayer` are slightly different.) '''
网络结构
实验结果
tensorboard_embeddings_mnist.py Trains a simple convnet on the MNIST dataset and embeds test data which can be later visualized using TensorBoard’s Embedding Projector.