本文 是 NAACL 2018 最佳论文 Deep contextualized word representations 的 ELMo 模型字符卷积的基础。
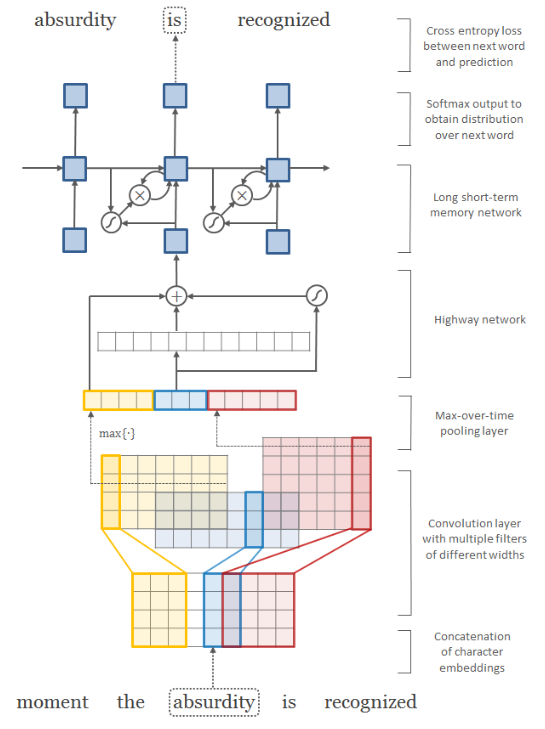
注意点:
- 卷积核的高度一般与单词矩阵的高度一致(字符向量维度);
- 不同的卷积核宽度代表着不同的 N-gram 语法;
- 上图一共有 12 个卷积核,宽度一样的卷积核放在一起了(黄色、蓝色和红色);

Character-Aware Neural Language Models
Yoon Kim, Yacine Jernite, David Sontag, Alexander M. Rush
(Submitted on 26 Aug 2015 (v1), last revised 1 Dec 2015 (this version, v4))
We describe a simple neural language model that relies only on character-level inputs. Predictions are still made at the word-level. Our model employs a convolutional neural network (CNN) and a highway network over characters, whose output is given to a long short-term memory (LSTM) recurrent neural network language model (RNN-LM). On the English Penn Treebank the model is on par with the existing state-of-the-art despite having 60% fewer parameters. On languages with rich morphology (Arabic, Czech, French, German, Spanish, Russian), the model outperforms word-level/morpheme-level LSTM baselines, again with fewer parameters. The results suggest that on many languages, character inputs are sufficient for language modeling. Analysis of word representations obtained from the character composition part of the model reveals that the model is able to encode, from characters only, both semantic and orthographic information.
Comments: AAAI 2016
Subjects: Computation and Language (cs.CL); Neural and Evolutionary Computing (cs.NE); Machine Learning (stat.ML)
Cite as: arXiv:1508.06615 [cs.CL]
(or arXiv:1508.06615v4 [cs.CL] for this version)
| 标题 | 说明 | 附加 |
|---|---|---|
| 自然语言处理中CNN模型几种常见的Max Pooling操作 | 张俊林 | 20160407 |

