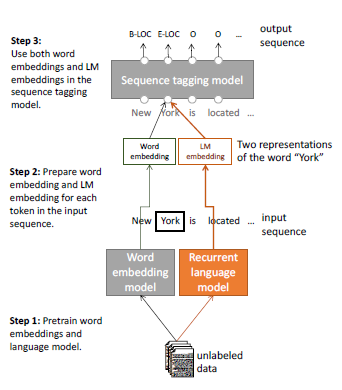
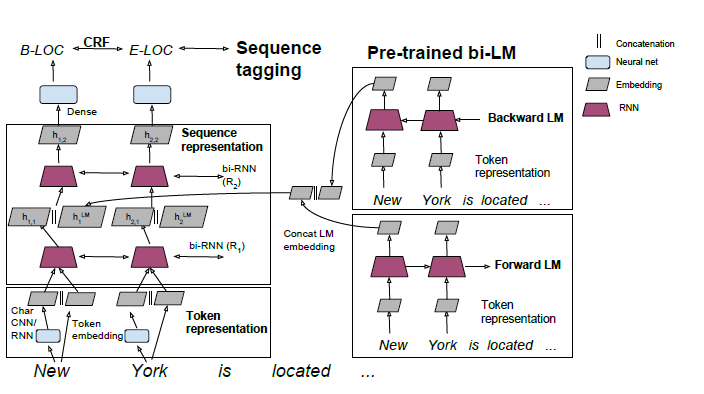
本文 是 NAACL 2018 最佳论文 Deep contextualized word representations 的前作,详细介绍了一种用预训练的双向语言模型提高其它模型(序列标注)效果的半监督方法。


Semi-supervised sequence tagging with bidirectional language models
Matthew E. Peters, Waleed Ammar, Chandra Bhagavatula, Russell Power
(Submitted on 29 Apr 2017)
Pre-trained word embeddings learned from unlabeled text have become a standard component of neural network architectures for NLP tasks. However, in most cases, the recurrent network that operates on word-level representations to produce context sensitive representations is trained on relatively little labeled data. In this paper, we demonstrate a general semi-supervised approach for adding pre- trained context embeddings from bidirectional language models to NLP systems and apply it to sequence labeling tasks. We evaluate our model on two standard datasets for named entity recognition (NER) and chunking, and in both cases achieve state of the art results, surpassing previous systems that use other forms of transfer or joint learning with additional labeled data and task specific gazetteers.
Comments: To appear in ACL 2017
Subjects: Computation and Language (cs.CL)
Cite as: arXiv:1705.00108 [cs.CL]
(or arXiv:1705.00108v1 [cs.CL] for this version)

