CoLA 数据集官网
Introduction
The Corpus of Linguistic Acceptability (CoLA) in its full form consists of 10657 sentences from 23 linguistics publications, expertly annotated for acceptability (grammaticality) by their original authors. The public version provided here contains 9594 sentences belonging to training and development sets, and excludes 1063 sentences belonging to a held out test set. Contact alexwarstadt [at] gmail [dot] com with any questions or issues. Read the paper or checkout the source code for baselines.
Data Format
Each line in the .tsv files consists of 4 tab-separated columns.
Column 1: the code representing the source of the sentence.
Column 2: the acceptability judgment label (0=unacceptable, 1=acceptable).
Column 3: the acceptability judgment as originally notated by the author.
Column 4: the sentence.
Corpus Sample
clc95 0 In which way is Sandy very anxious to see if the students will be able to solve the homework problem?
c-05 1 The book was written by John.
c-05 0 Books were sent to each other by the students.
swb04 1 She voted for herself.
swb04 1 I saw that gas can explode.
Neural Network Acceptability Judgments
Alex Warstadt, Amanpreet Singh, Samuel R. Bowman
(Submitted on 31 May 2018 (v1), last revised 11 Sep 2018 (this version, v2))
In this work, we explore the ability of artificial neural networks to judge the grammatical acceptability of a sentence. Machine learning research of this kind is well placed to answer important open questions about the role of prior linguistic bias in language acquisition by providing a test for the Poverty of the Stimulus Argument. In service of this goal, we introduce the Corpus of Linguistic Acceptability (CoLA), a set of 10,657 English sentences labeled as grammatical or ungrammatical by expert linguists. We train several recurrent neural networks to do binary acceptability classification. These models set a baseline for the task. Error-analysis testing the models on specific grammatical phenomena reveals that they learn some systematic grammatical generalizations like subject-verb-object word order without any grammatical supervision. We find that neural sequence models show promise on the acceptability classification task. However, human-like performance across a wide range of grammatical constructions remains far off.
Comments: 12 pages
Subjects: Computation and Language (cs.CL)
Cite as: arXiv:1805.12471 [cs.CL]
(or arXiv:1805.12471v2 [cs.CL] for this version)
CoLA-baselines
Model
Our general model structure looks like figure below. Follow paper for more in-depth details.
实验
论文中的基线结果
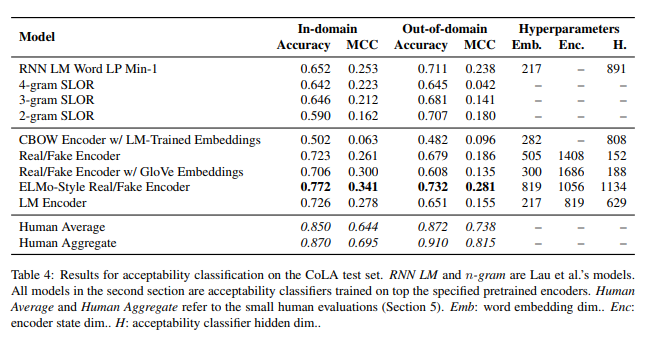
使用 BERT 模型的效果

训练过程
训练参数
训练输入
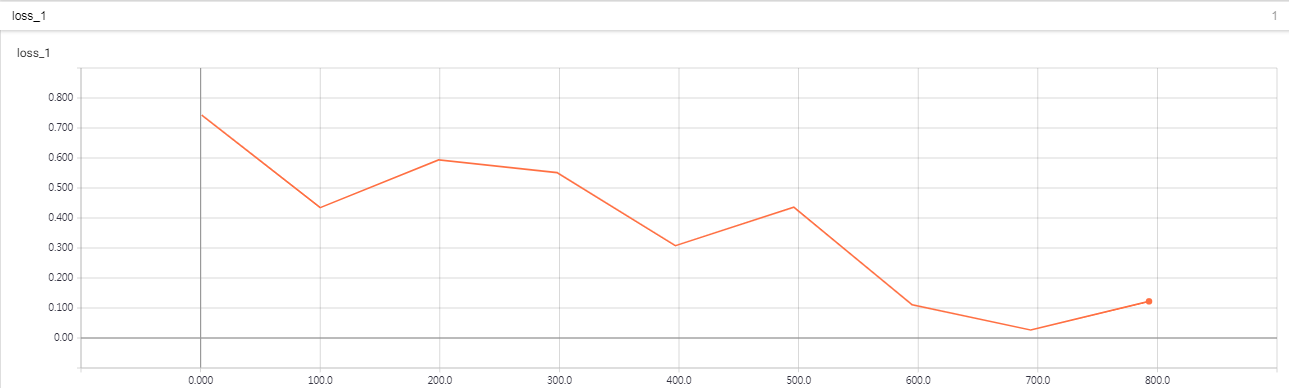
训练损失