OpenAI 20180611日更新了一篇博客,他们利用一个任务无关的可扩展系统在多语言任务上取得了卓越进展。论文及代码已经公布。他们的方法结合了 transformers 和无监督学习两个已经存在的方法。项目结果证明了将监督学习和无监督预训练结合的方法十分有效。这是很多人设想过的方法,他们希望他们的成果可以激励更多人将该方法应用于更大更复杂的数据集上。
论文精要
3 Framework
Our training procedure consists of two stages. The first stage is learning a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to a discriminative task with labeled data.
3.1 Unsupervised pre-training

3.2 Supervised fine-tuning

3.3 Task-sepcific input transfoemations
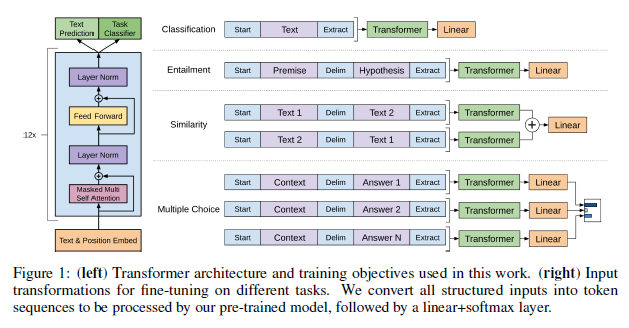

Experiments
4.1 Setup
Unsupervised pre-training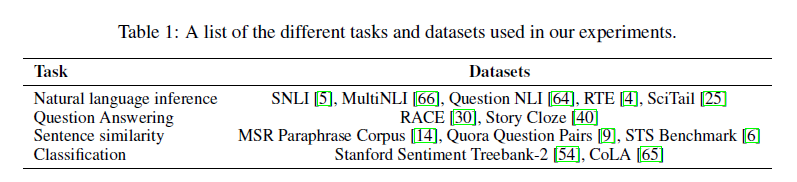
4.2 Supervised fine-tuning
Natural Language Inference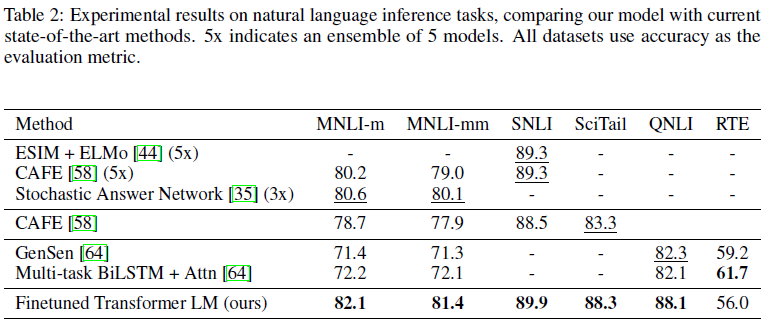
Question answering and commonsense reasoning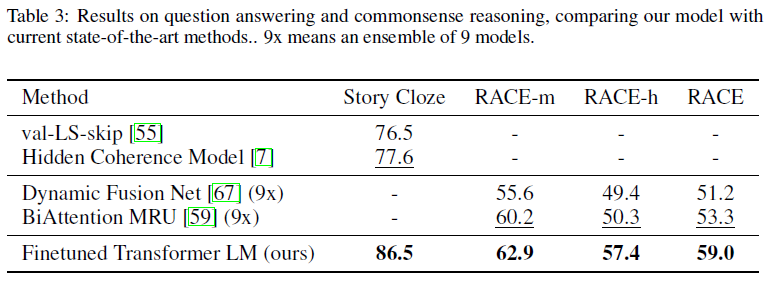
Semantic Similarity + Classification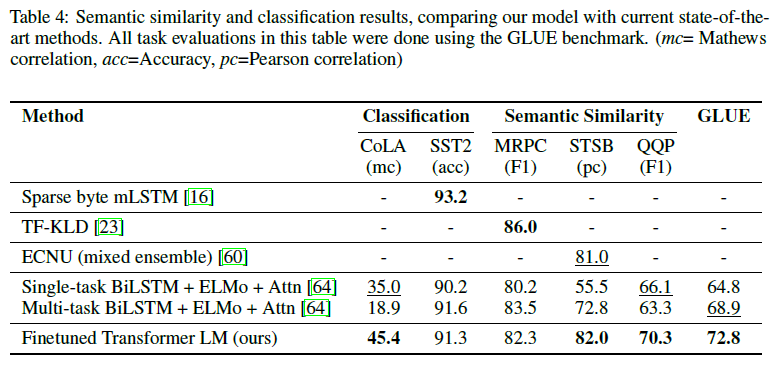
总的来说,我们的方法在我们评估的12个数据集中有9个获得了最新的结果,在很多情况下超过了整体表现。我们的研究结果还表明,我们的方法是有效的在不同大小的数据集,从较小的数据集,如STS-B (≈5.7 k训练例子)——最大的一个——SNLI (≈550 k训练例子)。
analysis
Impact of number of layers transferred(left) + Zero-shot Behaviors(right)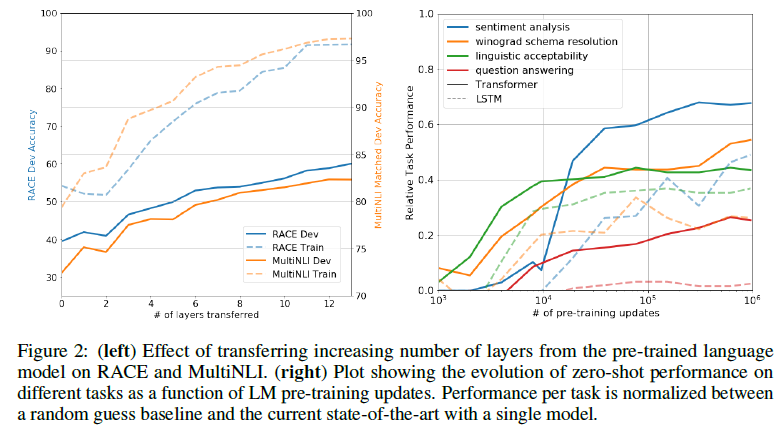
Ablation studies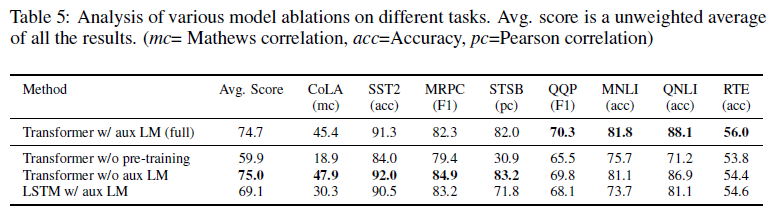
We perform three different ablation studies (Table 5). First, we examine the performance of our method without the auxiliary LM objective during fine-tuning. We observe that the auxiliary objective helps on the NLI tasks and QQP. Overall, the trend suggests that larger datasets benefit from the auxiliary objective but smaller datasets do not. Second, we analyze the effect of the Transformer by comparing it with a single layer 2048 unit LSTM using the same framework. We observe a 5.6 average score drop when using the LSTM instead of the Transformer. The LSTM only outperforms the Transformer on one dataset – MRPC. Finally, we also compare with our transformer architecture directly trained on supervised target tasks, without pre-training. We observe that the lack of pre-training hurts performance across all the tasks, resulting in a 14.8% decrease compared to our full model.
6 Conclusion

论文相关资源
| 标题 | 说明 | 附加 |
|---|---|---|
| Improving Language Understanding by Generative Pre-Training | 论文原文 | 20180611 |
| openai/finetune-transformer-lm | 官方代码实现 | 20180831 |
| Improving Language Understanding with Unsupervised Learning | 官方论文博客 | 20180611 |

