本文介绍了一种新的语言表征模型 BERT——来自 Transformer 的双向编码器表征。与最近的语言表征模型不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。BERT 是首个在大批句子层面和 token 层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统,刷新了 11 项 NLP 任务的当前(2018年)最优性能记录。
推荐动手实战 Entity-Relation-Extraction,基于TensorFlow和BERT的管道式实体及关系抽取,2019语言与智能技术竞赛信息抽取任务解决方案。
BERT 论文内容精要
推荐结合 BERT论文 全文中译 阅读
模型结构
其中的主要模块 Transformer 来自 Attention Is All You Need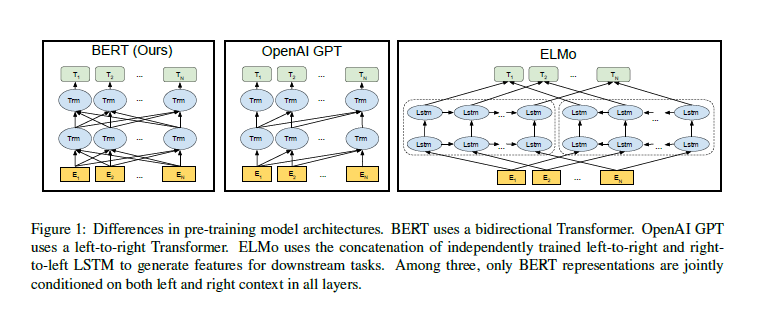
模型输入
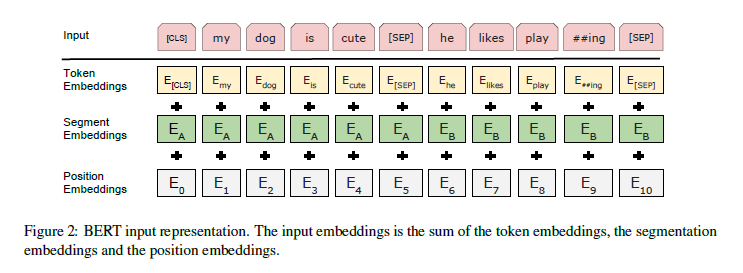
预训练方法
遮蔽语言模型(完形填空)和预测下一句任务。
实验
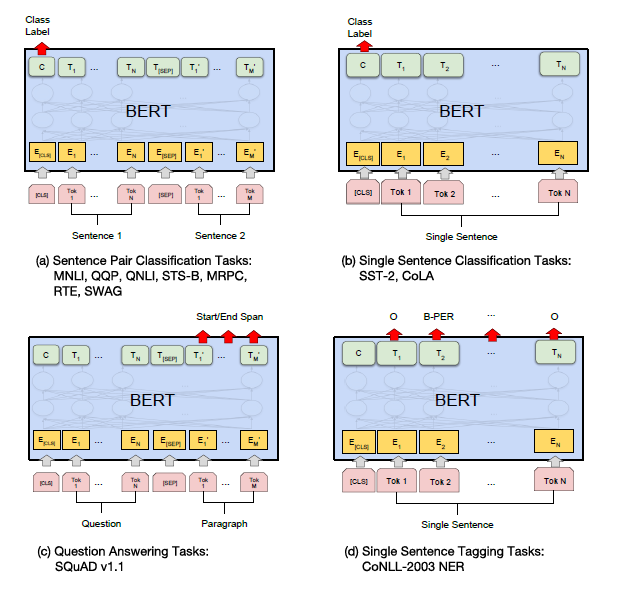

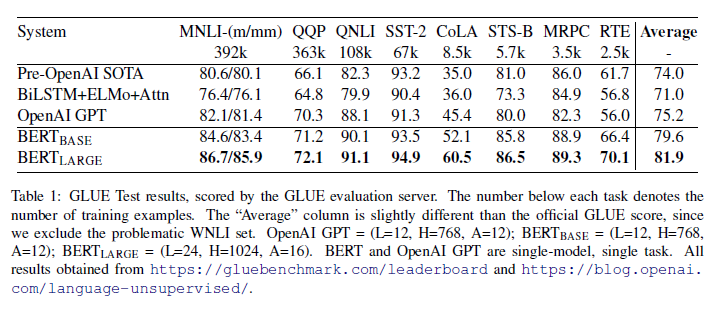
模型分析
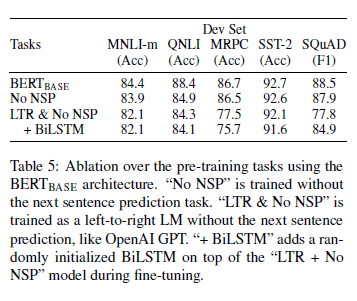
Effect of Pre-training Tasks
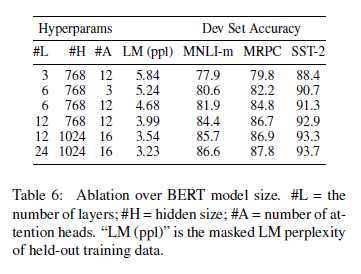
Effect of Model Size
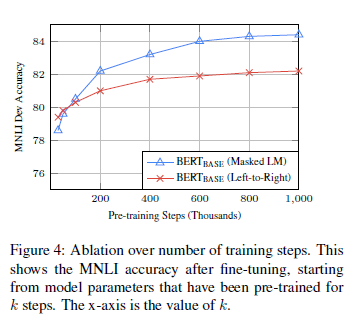
Effect of Number of Training Steps
Feature-based Approach with BERT

结论
Recent empirical improvements due to transfer learning with language models have demonstrated that rich, unsupervised pre-training is an integral part of many language understanding systems. Inparticular, these results enable even low-resource tasks to benefit from very deep unidirectional architectures.Our major contribution is further generalizing these findings to deep bidirectional architectures, allowing the same pre-trained model to successfully tackle a broad set of NLP tasks. While the empirical results are strong, in some cases surpassing human performance, important future work is to investigate the linguistic phenomena that may or may not be captured by BERT.
BERT 论文解析
| 标题 | 说明 | 附加 | |
|---|---|---|---|
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding | 原始论文 | 20181011 | |
| Reddit 讨论 | 作者讨论 | ||
| BERT-pytorch | Google AI 2018 BERT pytorch implementation | ||
| 论文解读:BERT模型及fine-tuning | 习翔宇 论文解读 | ||
| 最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录 | 论文浅析 | ||
| 【NLP】Google BERT详解 | 李入魔 解读 | ||
| 如何评价 BERT 模型? | 解读论文思想点 | ||
| NLP突破性成果 BERT 模型详细解读 | 章鱼小丸子 解读 | ||
| 谷歌最强 NLP 模型 BERT 解读 | AI科技评论 | ||
| 预训练BERT,官方代码发布前他们是这样用TensorFlow解决的 | 论文复现说明 | 20181030 | |
| 谷歌终于开源BERT代码:3 亿参数量,机器之心全面解读 | 20181101 | ||
| 为什么说 Bert 大力出奇迹? | 20181121 | ||
| 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 | 张俊林 | 20181111 | |
| BERT fine-tune 实践终极教程 | BERT在中文数据集上的fine tune全攻略 | 20181123 | |
| BERT在极小数据下带来显著提升的开源实现 | 张俊 | 20181127 | |
| Use google BERT to do CoNLL-2003 NER ! | kyzhouhzau | 201810 | |
| 图解BERT模型:从零开始构建BERT | 20190130 | ||
| Why BERT has 3 Embedding Layers and Their Implementation Details | 详解BERT的嵌入层输入构成,包括词Token 、Segment 和 Position 嵌入 | 20190219 | |
| BERT实战(源码分析+踩坑) | 20190309 | ||
| Bert时代的创新:Bert应用模式比较及其它 和 Bert时代的创新(应用篇):Bert在NLP各领域的应用进展 | 张俊林,综述从BERT 诞生到20190609时的发展 | 20190609 | |
| 一文读懂BERT(原理篇) | 20191027 |
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
(Submitted on 11 Oct 2018)
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%.
Comments: 13 pages摘要:本文介绍了一种新的语言表征模型 BERT,意为来自 Transformer 的双向编码器表征(Bidirectional Encoder Representations from Transformers)。与最近的语言表征模型(Peters et al., 2018; Radford et al., 2018)不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的 BERT 表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推断任务)创建当前最优模型,无需对任务特定架构做出大量修改。
BERT 的概念很简单,但实验效果很强大。它刷新了 11 个 NLP 任务的当前最优结果,包括将 GLUE 基准提升至 80.4%(7.6% 的绝对改进)、将 MultiNLI 的准确率提高到 86.7%(5.6% 的绝对改进),以及将 SQuAD v1.1 的问答测试 F1 得分提高至 93.2 分(提高 1.5 分)——比人类表现还高出 2 分。
Subjects: Computation and Language (cs.CL)
Cite as: arXiv:1810.04805 [cs.CL]
(or arXiv:1810.04805v1 [cs.CL] for this version)
Bibliographic data
Select data provider: Semantic Scholar [Disable Bibex(What is Bibex?)]
No data available yet
Submission history
From: Jacob Devlin [view email]
[v1] Thu, 11 Oct 2018 00:50:01 GMT (227kb,D)
Reddit 讨论

官方复现 google-research bert
最近谷歌发布了基于双向 Transformer 的大规模预训练语言模型,该预训练模型能高效抽取文本信息并应用于各种 NLP 任务,该研究凭借预训练模型刷新了 11 项 NLP 任务的当前最优性能记录。如果这种预训练方式能经得起实践的检验,那么各种 NLP 任务只需要少量数据进行微调就能实现非常好的效果,BERT 也将成为一种名副其实的骨干网络。
除了官方复现 google-research bert,就推荐更加方便易用的huggingface/transformers
Introduction
BERT, or Bidirectional Encoder Representations from
Transformers, is a new method of pre-training language representations which
obtains state-of-the-art results on a wide array of Natural Language Processing
(NLP) tasks.
Our academic paper which describes BERT in detail and provides full results on a
number of tasks can be found here:
https://arxiv.org/abs/1810.04805.
To give a few numbers, here are the results on the
SQuAD v1.1 question answering
task:
| SQuAD v1.1 Leaderboard (Oct 8th 2018) | Test EM | Test F1 |
|---|---|---|
| 1st Place Ensemble - BERT | 87.4 | 93.2 |
| 2nd Place Ensemble - nlnet | 86.0 | 91.7 |
| 1st Place Single Model - BERT | 85.1 | 91.8 |
| 2nd Place Single Model - nlnet | 83.5 | 90.1 |
And several natural language inference tasks:
| System | MultiNLI | Question NLI | SWAG |
|---|---|---|---|
| BERT | 86.7 | 91.1 | 86.3 |
| OpenAI GPT (Prev. SOTA) | 82.2 | 88.1 | 75.0 |
Plus many other tasks.
Moreover, these results were all obtained with almost no task-specific neural
network architecture design.
If you already know what BERT is and you just want to get started, you can
download the pre-trained models and
run a state-of-the-art fine-tuning in only a few
minutes.
BERT的数据集 GLUE
GLUE 来自论文 GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
摘要
For natural language understanding (NLU) technology to be maximally useful, both practically and as a scientific object of study, it must be general: it must be able to process language in a way that is not exclusively tailored to any one specific task or dataset. In pursuit of this objective, we introduce the General Language Understanding Evaluation benchmark (GLUE), a tool for evaluating and analyzing the performance of models across a diverse range of existing NLU tasks. GLUE is model-agnostic, but it incentivizes sharing knowledge across tasks because certain tasks have very limited training data. We further provide a hand-crafted diagnostic test suite that enables detailed linguistic analysis of NLU models. We evaluate baselines based on current methods for multi-task and transfer learning and find that they do not immediately give substantial improvements over the aggregate performance of training a separate model per task, indicating room for improvement in developing general and robust NLU systems.
解析BERT中的 Transformer 的注意力机制
| 标题 | 说明 | 时间 |
|---|---|---|
| 用可视化解构BERT,我们从上亿参数中提取出了6种直观模式 | 通过图解BERT中的注意力权重分析BERT的学习模式 | 20190121 |
| Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters | 用可视化解构BERT,我们从上亿参数中提取出了6种直观模式 原文 | 20181219 |
| Deconstructing BERT, Part 2: Visualizing the Inner Workings of Attention | 用可视化解构BERT,我们从上亿参数中提取出了6种直观模式 原文 | 20190108 |
| Attention isn’t all you need!BERT的力量之源远不止注意力 | 本文尝试从自然语言理解的角度解释 BERT 的强大能力。作者指出Transformer不只有注意力(解析),还注重组合,而解析and组合正是自然语言理解的框架。 | 20190305 |
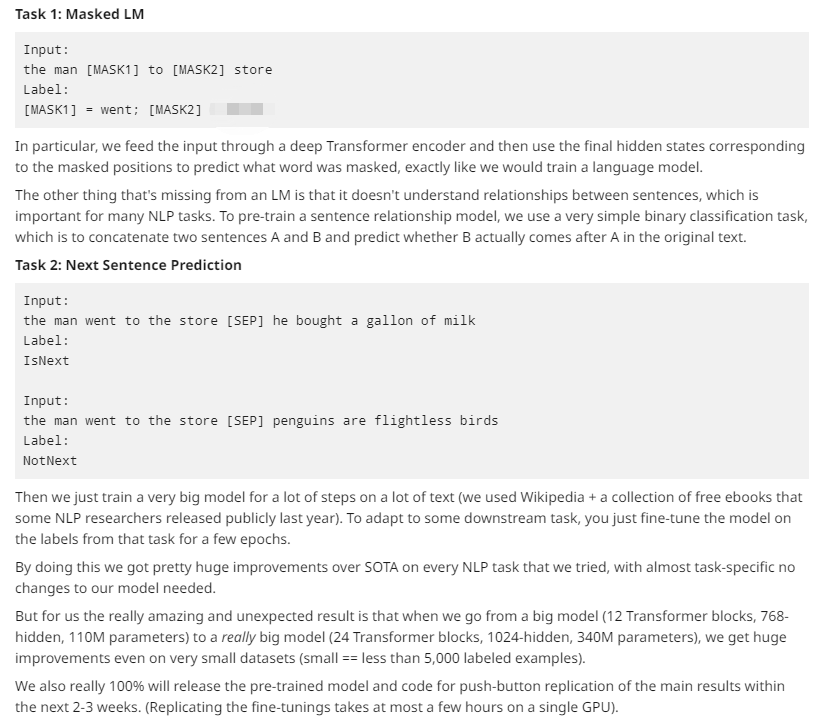
Tensor2Tensor有一个很好的工具,可用于可视化Transformer 模型中的注意力模式。因此我修改了一下,直接用在BERT的一个pytorch版本上。修改后的界面如下所示。你可以直接在这个 Colab notebook里运行,或在 Github 上找到源码。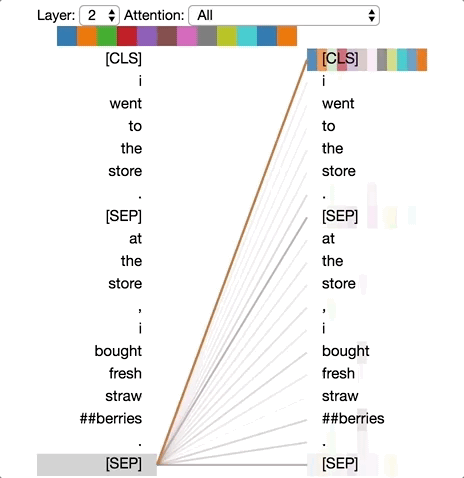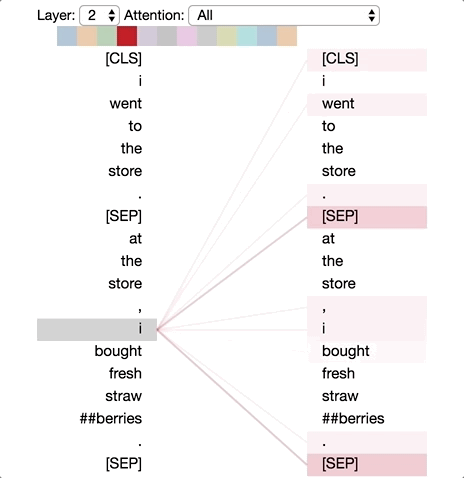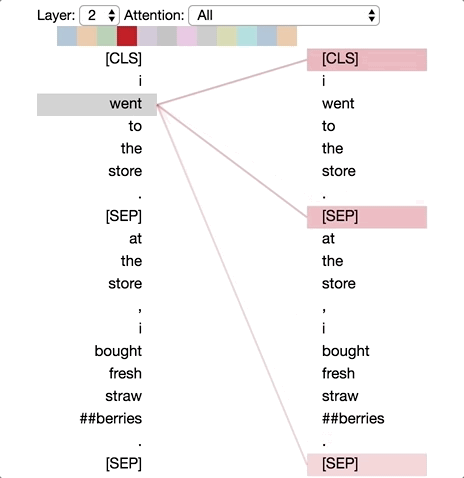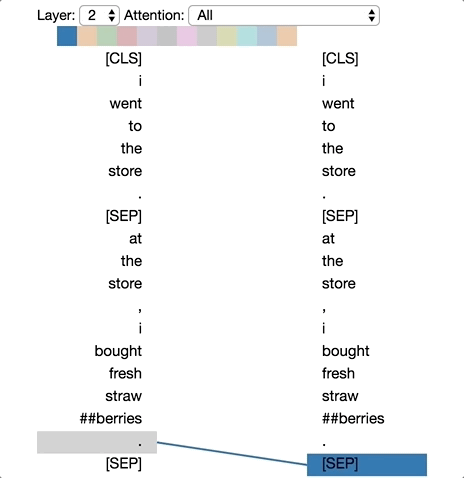
一个新的可视化工具将展示BERT如何形成其独特的注意力模式。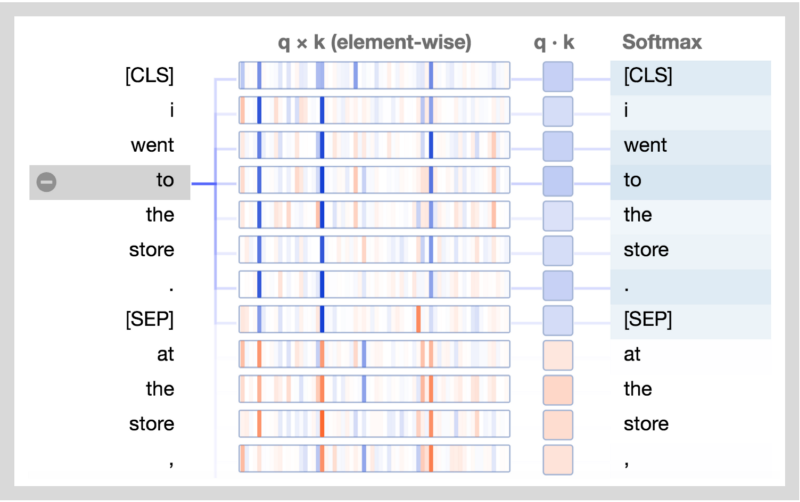
注意力解释
2-1
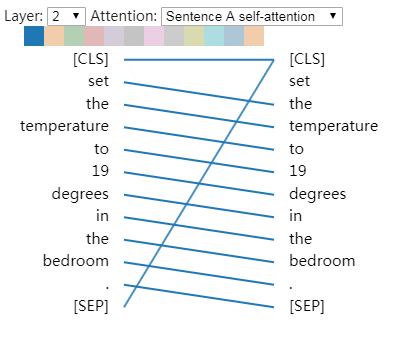
3-5 6-11


4-5


| 层数 | 注意力头 | 特征 |
|---|---|---|
| 2 | 1 | 关注句中下一个词语 |
| 3 | 5 | 关注句中上一个词语 |
| 4 | 5 | 关注句中短语结构 |
| 6 | 11 | 关注句中上一个词语 |
意外的是,我们发现了一个似乎在真正执行共指消解的注意力头(第六层的注意力头 #0)。此外,正如文章《Understanding BERT Part 2: BERT Specifics》中提到的,一些注意力头似乎为每个单词提供全局上下文(第 0 层的注意力头 #0)。
第六层的注意力头 #0 中发生的共指消解。

每个单词都会关注该句中所有其它的单词。这可能为每个单词创建一个粗略的上下文语境。
BERT的未来发展
BERT 在中文自然语言处理中应用
https://github.com/yumath/bertNER
https://github.com/Hoiy/berserker
https://github.com/GhibliField/Multiclass-Text-Classification-using-BERT
https://github.com/lonePatient/BERT-chinese-text-classification-pytorch
后BERT时代:15个预训练模型对比分析与关键点探索
参见 nlp中的预训练语言模型总结(单向模型、BERT系列模型、XLNet)
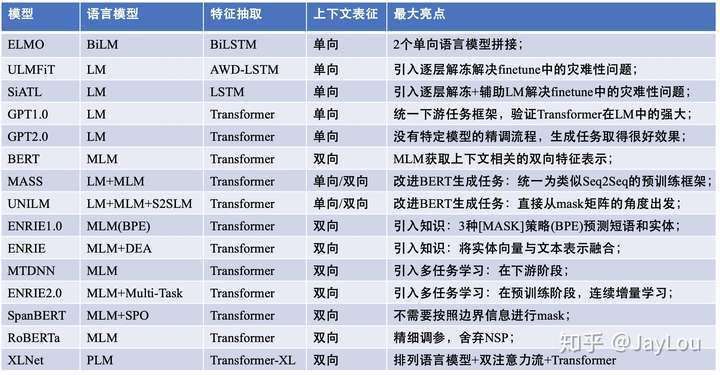
除了官方复现 google-research bert,就推荐更加方便易用集成了BERT各种改进版本的huggingface/transformers。

