Machine translation
Machine translation is the task of translating a sentence in a source language to a different target language.
Results with a * indicate that the mean test score over the the best window based on average dev-set BLEU score over
21 consecutive evaluations is reported as in Chen et al. (2018).
以下数据来自 NLP-progress
WMT 2014 EN-DE
Models are evaluated on the English-German dataset of the Ninth Workshop on Statistical Machine Translation (WMT 2014) based
on BLEU.
| Model | BLEU | Paper / Source |
|---|---|---|
| Transformer Big + BT (Edunov et al., 2018) | 35.0 | Understanding Back-Translation at Scale |
| DeepL | 33.3 | DeepL Press release |
| Transformer Big (Ott et al., 2018) | 29.3 | Scaling Neural Machine Translation |
| RNMT+ (Chen et al., 2018) | 28.5* | The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation |
| Transformer Big (Vaswani et al., 2017) | 28.4 | Attention Is All You Need |
| Transformer Base (Vaswani et al., 2017) | 27.3 | Attention Is All You Need |
| MoE (Shazeer et al., 2017) | 26.03 | Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer |
| ConvS2S (Gehring et al., 2017) | 25.16 | Convolutional Sequence to Sequence Learning |
WMT 2014 EN-FR
Similarly, models are evaluated on the English-French dataset of the Ninth Workshop on Statistical Machine Translation (WMT 2014) based
on BLEU.
| Model | BLEU | Paper / Source |
|---|---|---|
| DeepL | 45.9 | DeepL Press release |
| Transformer Big + BT (Edunov et al., 2018) | 45.6 | Understanding Back-Translation at Scale |
| Transformer Big (Ott et al., 2018) | 43.2 | Scaling Neural Machine Translation |
| RNMT+ (Chen et al., 2018) | 41.0* | The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation |
| Transformer Big (Vaswani et al., 2017) | 41.0 | Attention Is All You Need |
| MoE (Shazeer et al., 2017) | 40.56 | Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer |
| ConvS2S (Gehring et al., 2017) | 40.46 | Convolutional Sequence to Sequence Learning |
| Transformer Base (Vaswani et al., 2017) | 38.1 | Attention Is All You Need |
我的研究
Facebook AI fairseq
对应的论文 2017《Convolutional Sequence to Sequence Learning》
序列到序列学习的普遍方法通过递归神经网络将输入序列映射到可变长度输出序列。 我们介绍一种完全基于卷积神经网络的架构。 与循环模型相比,在训练期间可以完全并行化所有元素的计算,并且由于非线性的数量是固定的并且与输入长度无关,因此优化更容易。 我们使用门控线性单元简化了梯度传播,我们为每个解码器层配备了一个单独的注意模块。 我们的表现优于Wu等人的深LSTM设置的准确性。 (2016)关于WMT’14英语 - 德语和WMT’14英语 - 法语翻译,在GPU和CPU上的速度都快了一个数量级。
使用该框架预训练的模型,顺利跑完实验。
官方提示使用方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14$ curl https://s3.amazonaws.com/fairseq-py/models/wmt14.v2.en-fr.fconv-py.tar.bz2 | tar xvjf - -C data-bin
$ curl https://s3.amazonaws.com/fairseq-py/data/wmt14.v2.en-fr.newstest2014.tar.bz2 | tar xvjf - -C data-bin
$ python generate.py data-bin/wmt14.en-fr.newstest2014 \
--path data-bin/wmt14.en-fr.fconv-py/model.pt \
--beam 5 --batch-size 128 --remove-bpe | tee /tmp/gen.out
...
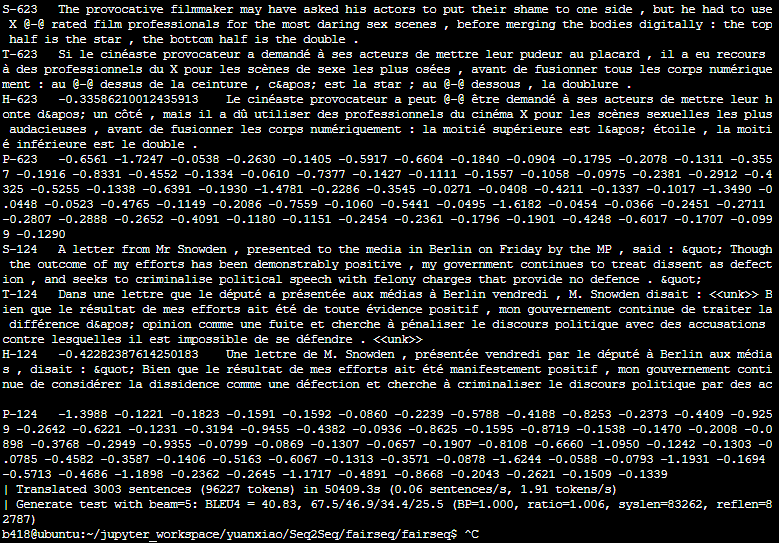
| Translated 3003 sentences (96311 tokens) in 166.0s (580.04 tokens/s)
| Generate test with beam=5: BLEU4 = 40.83, 67.5/46.9/34.4/25.5 (BP=1.000, ratio=1.006, syslen=83262, reflen=82787)
# Scoring with score.py:
$ grep ^H /tmp/gen.out | cut -f3- > /tmp/gen.out.sys
$ grep ^T /tmp/gen.out | cut -f2- > /tmp/gen.out.ref
$ python score.py --sys /tmp/gen.out.sys --ref /tmp/gen.out.ref
BLEU4 = 40.83, 67.5/46.9/34.4/25.5 (BP=1.000, ratio=1.006, syslen=83262, reflen=82787)
翻译过来就是:
- 下载模型和语料并且解压;
- 设置超参数运行模型,
python generate.py data-bin/wmt14.en-fr.newstest2014 \
—path data-bin/wmt14.en-fr.fconv-py/model.pt \
—beam 5 —batch-size 128 —remove-bpe | tee /tmp/gen.out - 运行 score.py 评测模型效果;
自己运行结果与官方结果一致,除了我慢了300多倍,实验室只有一台CPU服务器还N多人一起用,伤不起!