槽填充和意图识别任务的基本概念
Their objective is to identify the intention of the user and the parameters of the query. The developer can then use this to determine the appropriate action or response. cite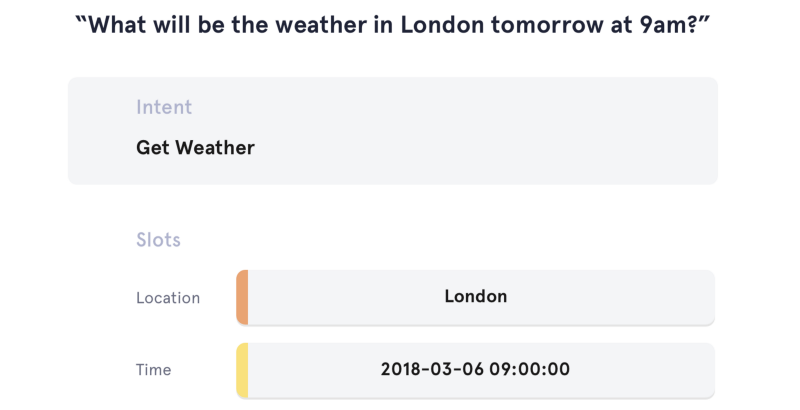
以 snips-nlu 为例讲解
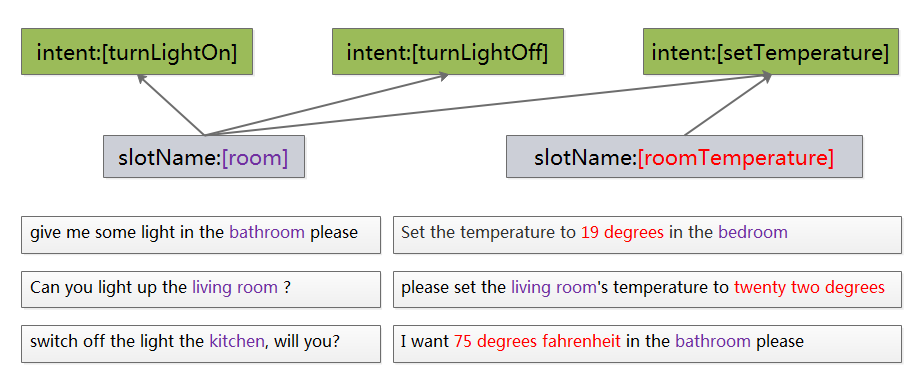
开关灯和控制房间温度的例子
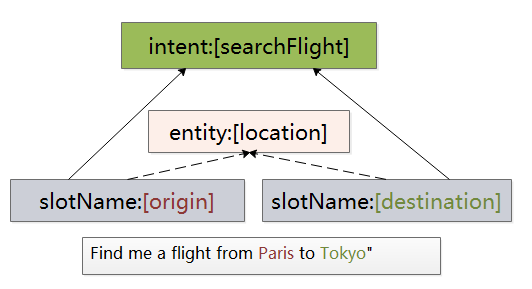
查询航班的例子
把上面的例子分析一下,可知道句子中词语与槽名称、实体名和意图之间的关系,如下图所示。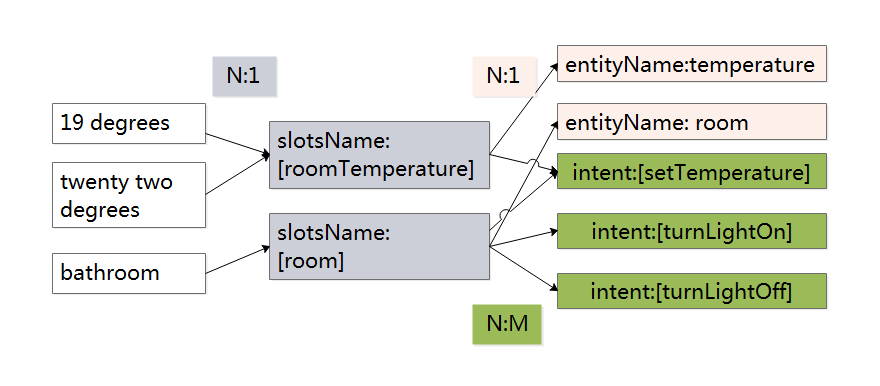
槽、意图、实体的基本信息和定义
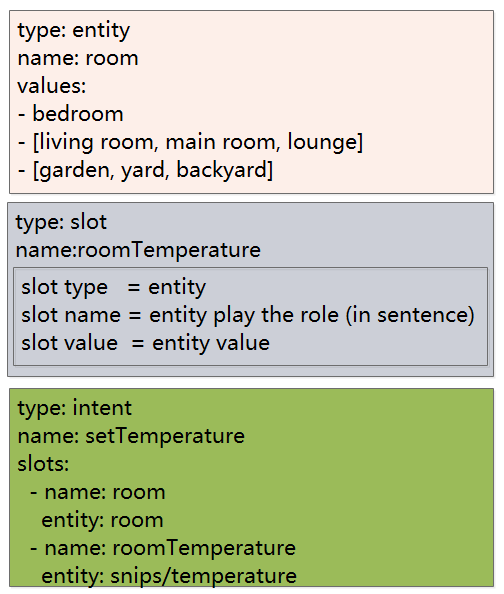
把这些内容写成 yaml 文件的形式:
它们之间的关系是:
用图来表达它们之间的关系: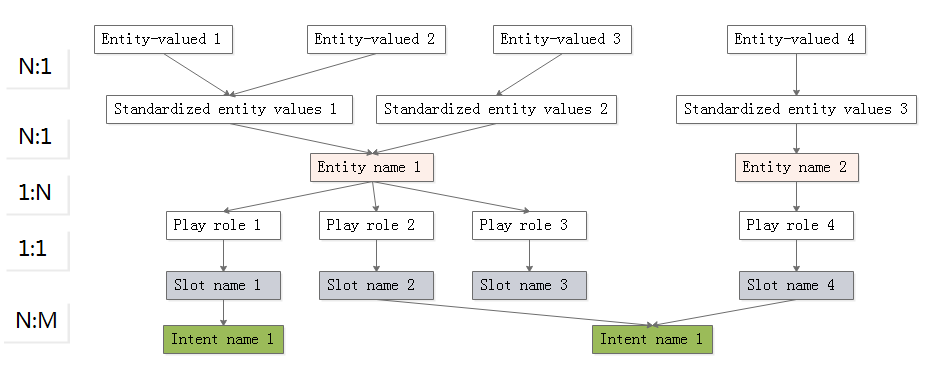
以论文 Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces 讲解基本概念
口语理解、技能、意图、槽和语音助手基本概念
The Snips ecosystem comprises a web console to build voice assistants and train the corresponding Spoken Language Understanding (SLU) engine, made of an Automatic Speech Recognition (ASR) engine and a Natural Language Understanding (NLU) engine.

An assistant is composed of a set of skills – e.g. SmartLights, SmartThermostat, or SmartOven skills for a SmartHome assistant – that may be either selected from preexisting ones in a skill store or created from scratch on the web console. A given skill may contain several intents, or user intention – e.g. SwitchLightOn and SwitchLightOff for a SmartLights skill. Finally, a given intent is bound to a list of entities that must be extracted from the user’s query – e.g. room for the SwitchLightOn intent. We call slot the particular value of an entity in a query – e.g. kitchen for the entity room. When a user speaks to the assistant, the SLU engine trained on the different skills will handle the request by successively converting speech into text, classifying the user’s intent, and extracting the relevant slots.
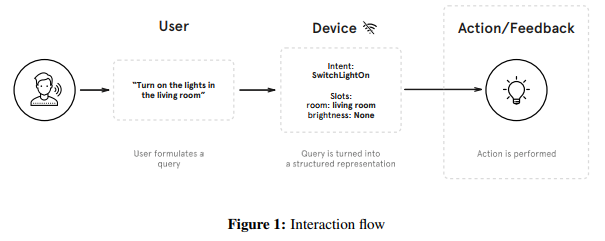
Once the user’s request has been processed and based on the information that has been extracted from the query and fed to the device, a dialog management component is responsible for providing a feedback to the user, or performing an action. It may take multiple forms, such as an audio response via speech synthesis or a direct action on a connected device – e.g. actually turning on the lights for a SmartLights skill. Figure 1 illustrates the typical interaction flow.
口语理解引擎
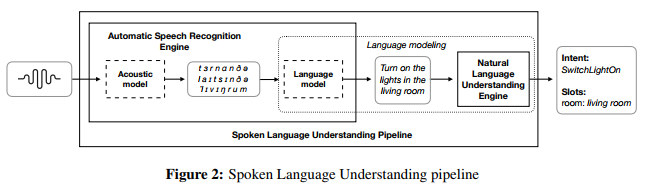
SLU engines are usually broken down into two parts: Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). The ASR engine translates a spoken utterance into text through an acoustic model, mapping raw audio to a phonetic representation, and a Language Model (LM), mapping this phonetic representation to text. The NLU then extracts intent and slots from the decoded query. As discussed in section 3, LM and NLU have to be mutually consistent in order to optimize the accuracy of the SLU engine. It is therefore useful to introduce a language modeling component composed of the LM and NLU. Figure 2 describes the building blocks of the SLU pipeline.
自然语言理解
The Natural Language Understanding component of the Snips Voice Platform extracts structured data from queries written in natural language. Snips NLU – a Python library – can be used for training and inference, with a Rust implementation focusing solely on inference. Both have been recently open-sourced [50, 49].
Three tasks are successively performed. Intent Classification consists in extracting the intent expressed in the query (e.g. SetTemperature or SwitchLightOn). Once the intent is known, Slot Filling aims to extract the slots, i.e. the values of the entities present in the query. Finally, Entity Resolution focuses on built-in entities, such as date and times, durations, temperatures, for which Snips provides an extra resolution step. It basically transforms entity values such as “tomorrow evening” into formatted values such as “2018-04-19 19:00:00 +00:00”. Snippet 1 illustrates a typical output of the NLU component.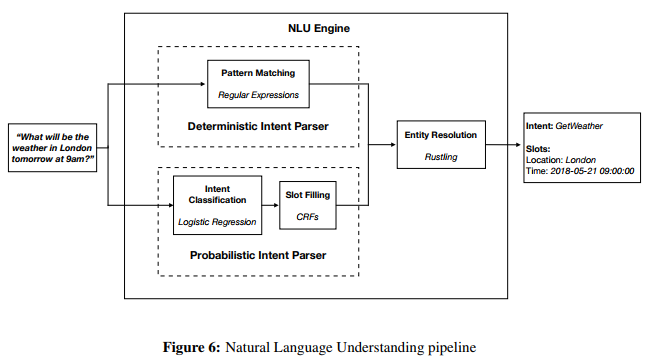
更多内容见GitHub资源 槽填充、意图预测(口语理解)论文整理和中文翻译

