XLNet是一种基于新型广义排列语言建模目标的新型无监督语言表示学习方法。 此外,XLNet采用Transformer-XL作为骨干模型,为涉及长时间环境的语言任务展示了出色的性能。 总体而言,XLNet在各种下游语言任务上实现了最先进的(SOTA)结果,包括问答,自然语言推理,情感分析和文档排名。
推荐阅读:XLNet论文 全文中译
2019 XLNet: Generalized Autoregressive Pretraining for Language Understanding
With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves better performance than pretraining approaches based on autoregressive language modeling. However, relying on corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into pretraining. Empirically, XLNet outperforms BERT on 20 tasks, often by a large margin, and achieves state-of-the-art results on 18 tasks including question answering, natural language inference, sentiment analysis, and document ranking.
由于具有双向上下文建模的能力,像BERT这样基于自动去噪的预训练语言模型比基于自回归的预训练语言模型的性能更好。然而,依赖于使用带掩码损坏的输入,BERT忽略了掩码位置之间的依赖性,进而受到了预训练-微调不一致的影响。根据这些优点和缺点,我们提出了XLNet,一种广义自回归预训练方法,它(1)通过最大化输入序列的因式分解的所有排列的似然函数的期望来学习双向上下文,并且(2)由于其自回归方法,克服了BERT的局限性。此外,XLNet将最先进的自回归模型Transformer-XL的思想整合到预训练中。实验表明,XLNet在20个任务上常大幅度优于BERT的表现,并在18个任务中实现最先进的结果,包括问答、自然语言推理、情感分析和文档排名。
| 标题 | 说明 | 时间 |
|---|---|---|
| XLNet: Generalized Autoregressive Pretraining for Language Understanding | 原始论文 | 20190619 |
| xlnet | 官方实现 | 持续更新 |
| 他们创造了横扫NLP的XLNet:专访CMU博士杨植麟 | 原作者解读 | 20190802 |
| 拆解XLNet模型设计,回顾语言表征学习的思想演进 | 追一科技 Tony | 20190629 |
| XLNet:运行机制及和Bert的异同比较 | 张俊林,知乎专栏 | 20190622 |
| 从语言模型到Seq2Seq:Transformer如戏,全靠Mask | 张俊林 解读 | 20190918 |
| GitHub XLNet_Paper_Chinese_Translation | XLNet 中文翻译 | 20191011 |
XLNet 的思考与做法
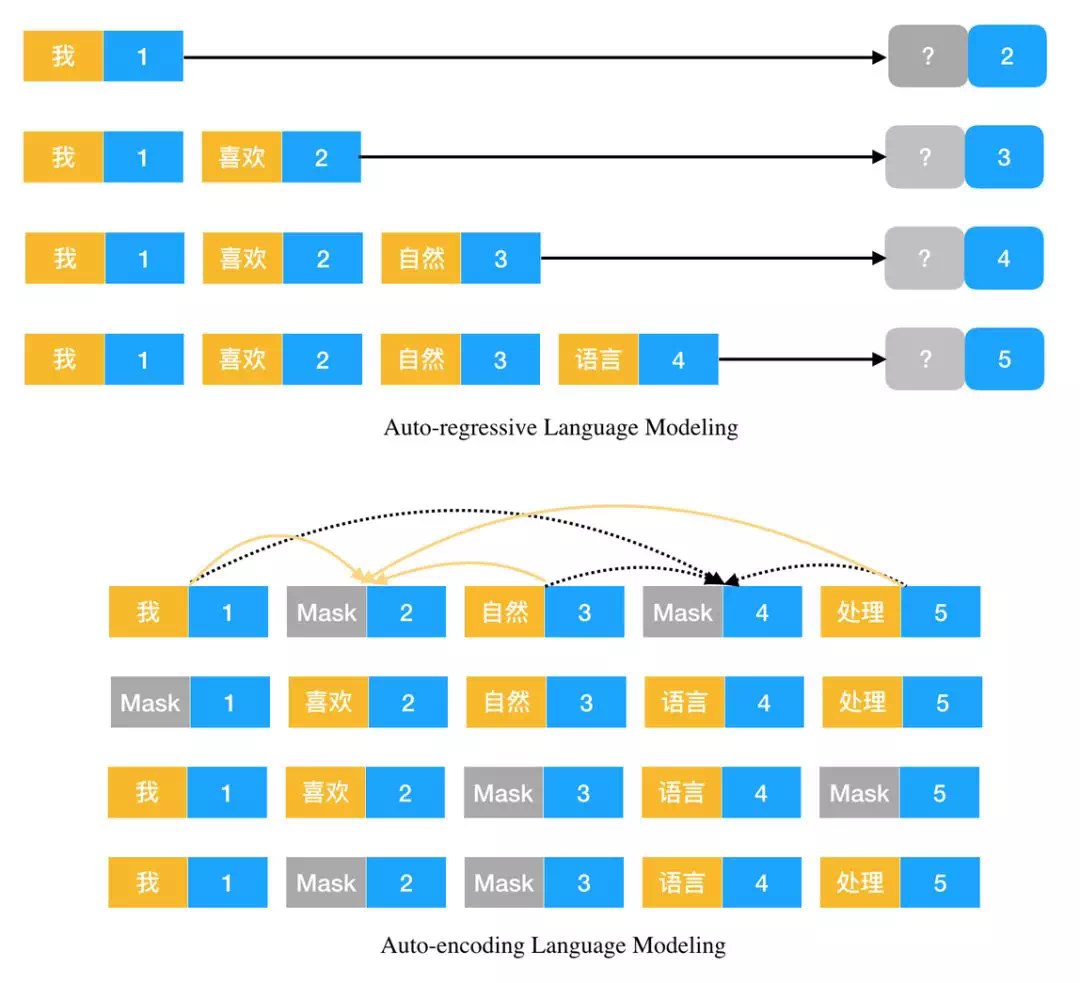
如上所示分别为自回归模型与自编码模型,其中黄色块为输入字符,蓝色块为字符的位置。对于自回归语言模型,它希望通过已知的前半句预测后面的词或字。对于自编码语言模型,它希望通过一句话预测被 Mask 掉的字或词,如上所示第 2 个位置的词希望通过第 1、3、5 个词进行预测。
我们需要更好的语言建模任务
以前,最常见的语言模型就是自回归式的了,它的计算效率比较高,且明确地建模了概率密度。但是自回归语言模型有一个缺陷,它只能编码单向语义,不论是从左到右还是从右到左都只是单向语义。这对于下游 NLP 任务来说是致命的,因此也就有了 BERT 那种自编码语言模型。
BERT 通过预测被 Mask 掉的字或词,从而学习到双向语义信息。但这种任务又带来了新问题,它只是建模了近似的概率密度,因为 BERT 假设要预测的词之间是相互独立的,即 Mask 之间相互不影响。此外,自编码语言模型在预训练过程中会使用 MASK 符号,但在下游 NLP 任务中并不会使用,因此这也会造成一定的误差。
为此,杨植麟表示我们需要一种更好的预训练语言任务,从而将上面两类模型的优点结合起来。XLNet 采用了一种新型语言建模任务,它通过随机排列自然语言而预测某个位置可能出现的词。如下图所示为排列语言模型的预测方式:
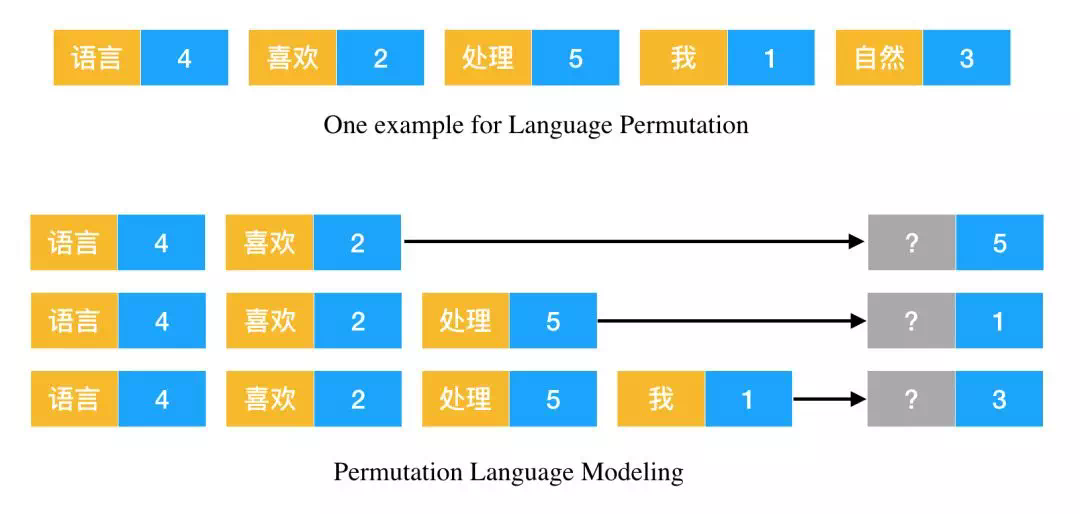
如上排列语言示例,因为随机排列是带有位置信息的,所以扰乱顺序并不影响建模效果。随机排列语言后,模型就开始依次预测不同位置的词。
如果我们知道所有词的内容及位置,那么是不是顺序地分解句子并不太重要。相反这种随机的分解顺序还能构建双向语义,因为如上利用「语言」和「喜欢」预测「处理」就利用了上下文的词。如下原论文展示了不同分解顺序预测同一词的差别,如果第一个分解的词的「3」,那么它就只能利用之前的隐藏状态 mem 进行预测。
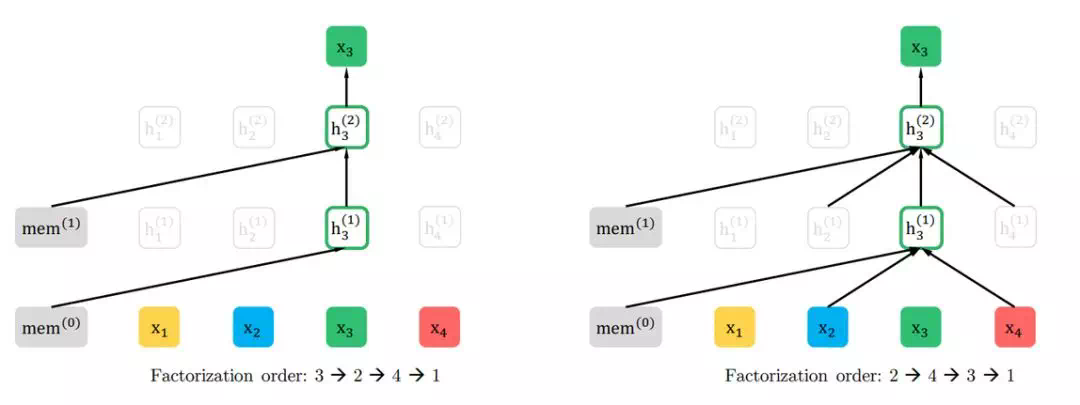
这理解起来其实也非常直观,如果我们知道某些词及词的位置,那么完形填空式地猜某个位置可能出现哪些词也是没问题的。此外,我们可以发现,这种排列语言模型就是传统自回归语言模型的推广,它将自然语言的顺序拆解推广到随机拆解。当然这种随机拆解要保留每个词的原始位置信息,不然就和词袋模型没什么差别了。
我们需要更好的结构
前面我们为预训练语言模型构建了新的任务目标,这里就需要调整 Transformer 以适应任务。如果读者了解一些 Transformer,那么就会知道某个 Token 的内容和位置向量在输入到模型前就已经加在一起了,后续的隐向量同时具有内容和位置的信息。但杨植麟说:「新任务希望在预测下一个词时只能提供位置信息,不能提供内容相关的信息。因此模型希望同时做两件事,首先它希望预测自己到底是哪个字符,其次还要能预测后面的字符是哪个。」
这两件事是有冲突的,如果模型需要预测位置 2 的「喜欢」,那么肯定不能用该位置的内容向量。但与此同时,位置 2 的完整向量还需要参与位置 5 的预测,且同时不能使用位置 5 的内容向量。
这类似于条件句:如果模型预测当前词,则只能使用位置向量;如果模型预测后续的词,那么使用位置加内容向量。因此这就像我们既需要标准 Transformer 提供内容向量,又要另一个网络提供对应的位置向量。
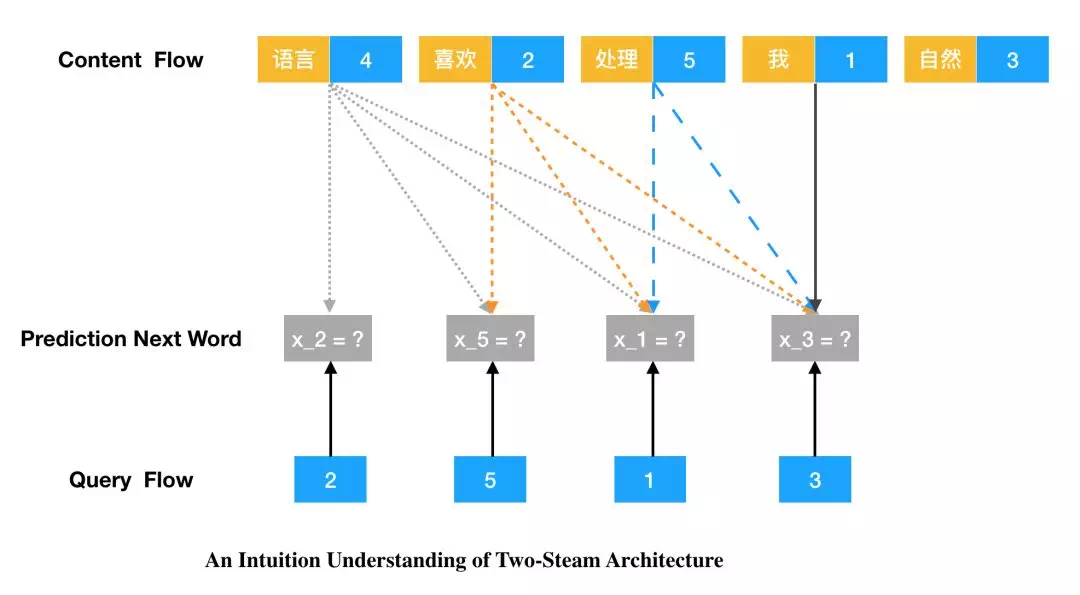
针对这种特性,研究者提出了 Two-Stream Self-Attention,它通过构建两条路径解决这个条件句。如下所示为 Two-Stream 的结构,其中左上角的 a 为 Content 流,左下角的 b 为 Query 流,右边的 c 为排列语言模型的整体建模过程。注:这只是解决“内容-位置”冲突的其中一种方法。
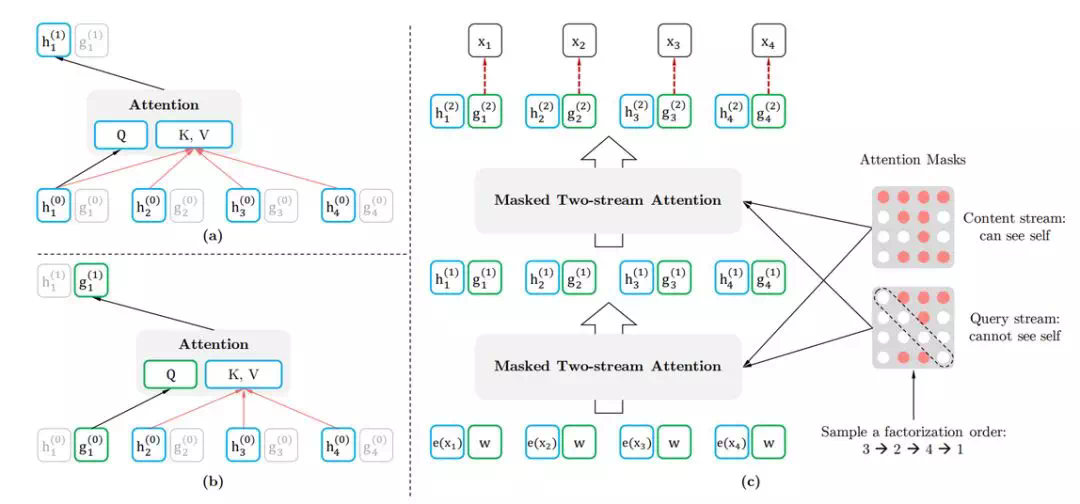
在 Content 流中,它和标准的 Transformer 是一样的,第 1 个位置的隐藏向量 h_1 同时编码了内容与位置。在 Query 流中,第 1 个位置的隐向量 g_1 只编码了位置信息,但它同时还需要利用其它 Token 的内容隐向量 h_2、h_3 和 h_4,它们都通过 Content 流计算得出。因此,我们可以直观理解为,Query 流就是为了预测当前词,而 Content 流主要为 Query 流提供其它词的内容向量。
上图 c 展示了 XLNet 的完整计算过程,e 和 w 分别是初始化的词向量的 Query 向量。注意排列语言模型的分解顺序是 3、2、4、1,因此 Content 流的 Mask 第一行全都是红色、第二行中间两个是红色,这表明 h_1 需要用所有词信息、h_2 需要用第 2 和 3 个词的信息。此外,Query 流的对角线都是空的,表示它们不能使用自己的内容向量 h。

