视频分类理论和实践研究
| 标题 | 内容 | 时间 |
|---|---|---|
| 基于视觉的视频分类入门 | 20180408 | |
| 爱奇艺“多模态视频人物识别”课程分享学习总结 | 20181005 | |
| Five video classification methods implemented in Keras and TensorFlow | 对应的代码 five-video-classification-methods | 20190504 |
| HHTseng/video-classification | Tutorial for video classification/ action recognition using 3D CNN/ CNN+RNN on UCF101 | 20190601 |
实战项目
Multimodal-short-video-dataset-and-baseline-classification-model
500,000 multimodal short video data and baseline models. 50万条多模态短视频数据集和基线模型(TensorFlow2.0)。
论文和数据集资源
2019 爱奇艺短视频分类技术解析
简介
近年来,短视频领域一直广受关注,且发展迅速。每天有大量UGC短视频被生产、分发和消费,为生产系统带来了巨大的压力,其中的难点之一就是为每个短视频快速、准确地打上标签。为了解决人工编辑的时效和积压问题,自动化标签技术成为各大内容领域公司都非常关注的关键课题。短视频大规模层次分类作为内容理解技术的一个重要方向,为爱奇艺的短视频智能分发业务提供着强力支持,其输出被称为“类型标签”。
技术难点
分类体系复杂。短视频分类体系是一棵人工精心制定的层次结构,体系和规则都比较复杂:层级最少有3级,最多有5级,总计近800个有效类别,类别间有互斥和共同出现的需求。
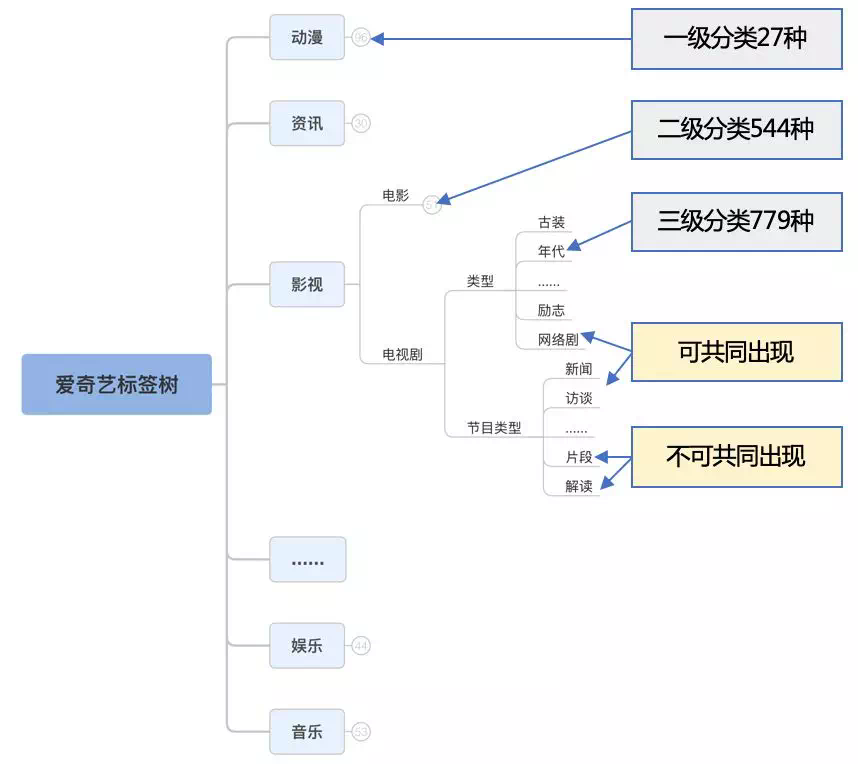
需要文本、图像、生态信息等多模态特征综合判断。短视频具有标题、描述、封面图、视频、音频等媒体信息。同时,一个短视频也不一定是独立存在的,它可能来自一个影视、综艺片段,它的上传者可能是一个垂直领域的内容贡献者,所以,关联正片、视频来源、上传者等信息对分类也可能有帮助。
解决方案
短视频分类可以分为特征表示(Feature Representation) 和层次分类(Hierarchical Classification) 两个模块,前者基于多模态特征建模短视频的整体表达(在我们的模型中通过Feature Representation和Representation Fusion两个子网络级联建模完成),后者基于前者完成分类任务。我们模型的整体结构如下图: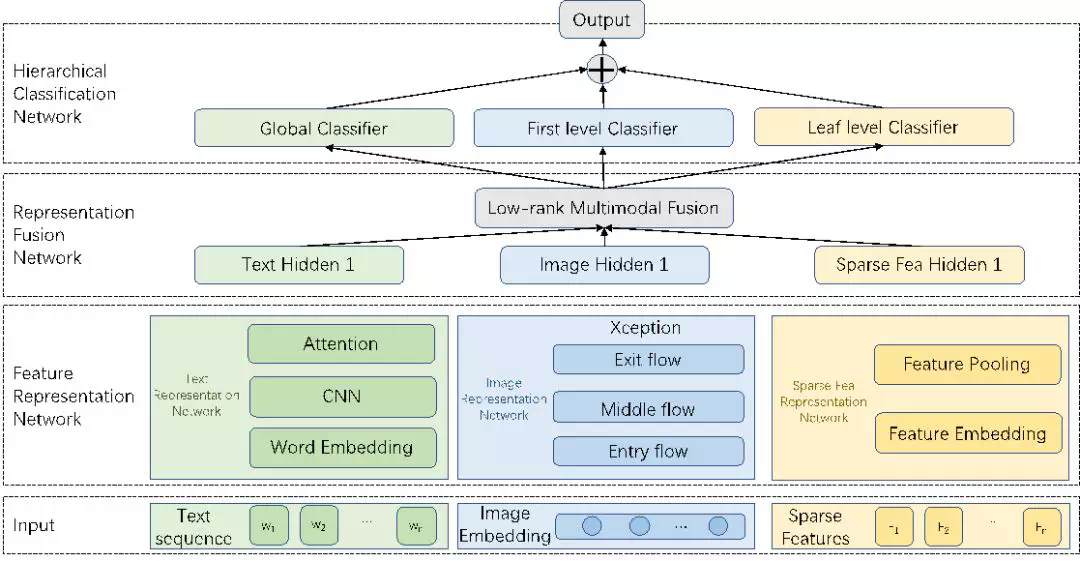
PRCV2018 美图短视频实时分类挑战赛第一名解决方案介绍
视频解码
因为时间是一个很重要的因素,而视频解码又是一个很费时间的过程,所以如何设计解码模块是本次竞赛中的一个关键。我们采用了多线程软解提取关键帧的方法。
主流的视频编码方式中,每个视频主要包含三种图片帧,分别叫做:Intra-coded frame(I 帧),Predictive frame(P 帧)和 Bi-Predictive frame(B 帧)。其中 I 帧是一张完整的图片。P 帧记录了与之前的帧的差别,所以在解码 P 帧时必须要参考之前的图片帧。而 B 帧不仅需要参考之前的图片帧,还需要参考之后的图片帧才能完整解码。图片 4 阐明了这三个概念 [2]。
显而易见,P 帧和 B 帧的解码是相对较慢的,而直接解码 I 帧则可以获得更快的速度。同时,由于我们需要解码不止一帧,所以我们采用了多线程的方式,每一个线程负责解码一个关键帧。整个解码过程使用 FFmpeg 实现。
模型设计
解决了解码问题后,接下来的问题在于如何用所得的多帧来进行分类。
主流方法
目前主流的视频分类的方法有三大类:基于 LSTM 的方法,基于 3D 卷积的方法和基于双流的方法。图片 5 展示了这三种框架的大体结构 [3]。
- 基于 LSTM 的方法将视频的每一帧用卷积网络提取出每一帧的特征,然后将每一个特征作为一个时间点,依次输入到 LSTM 中。由于 LSTM 并不限制序列的长度,所以这种方法可以处理任意长度的视频。但同时,因为 LSTM 本身有梯度消失和爆炸的问题,往往难以训练出令人满意的效果。而且,由于 LSTM 需要一帧一帧得进行输入,所以速度也比不上其他的方法。
- 基于 3D 卷积的方法将原始的 2D 卷积核扩展到 3D。类似于 2D 卷积在空间维度的作用方式,它可以在时间维度自底向上地提取特征。基于 3D 卷积的方法往往能得到不错的分类精度。但是,由于卷积核由 2D 扩展到了 3D,其参数量也成倍得增加了,所以网络的速度也会相应下降。
- 基于双流网络的方法会将网络分成两支。其中一支使用 2D 卷积网络来对稀疏采样的图片帧进行分类,另一支会提取采样点周围帧的光流场信息,然后使用一个光流网络来对其进行分类。两支网络的结果会进行融合从而得到最终的类标。基于双流的方法可以很好地利用已有的 2D 卷积网络来进行预训练,同时光流又可以建模运动信息,所以精度往往也很高。但是由于光流的提取过程很慢,所以整体上制约了这一方法的速度。

综上所述,主流的方法都不太适用于短视频实时分类的任务,所以我们特别设计了一个适用于短视频实时分类的框架。
我们的方法
图片 4 展示了我们的解决方案的整体框架:给定一个视频,我们首先会从中稀疏采样固定数量的图片帧,然后将这些帧组成一个 batch,送入到一个 BaseNet 中。这个 BaseNet 是在已有的 2D 卷积网络基础上优化改进得到的,具有较强的特征提取能力。BaseNet 输出的高层的特征往往具有很强的语义信息,但是却没有时间上的融合。所以我们特别设计了一个基于帧间注意力机制的融合模型,将 BaseNet 提取的不同帧的特征作为一个输入送入融合模型中,最终由融合模型得到预测的结果。由于融合模型比较小,推理速度很快,而且参数量较少,也比较容易训练。整个模型在 mxnet 上进行构建和训练。基于这样的设计,我们的模型可以得到很快的推理速度,同时又不会损失太多精度。
2019 重新认识快手:人工智能的从 0 到 1
多模态理解的挑战
过去几年,单模态内容理解能力在学术界还不够成熟,加上学术界对视频理解没有强烈的研究需求,导致始终没有形成一套针对视频理解的求解方案。在工业界,即使是全球最大的视频平台 YouTube,也因为其视频带有丰富的文本信息—标题、简介、标签,可以一定程度上绕开视频理解。
但快手不同。作为一款移动互联网时代兴起的短视频应用,快手给用户提供轻便新颖的拍视频体验,用户喜欢拍完就传,不爱文字编辑,描述视频的文字信息严重缺失。快手又需要理解内容来做推荐算法,视频理解成了一个绕不开的坎。李岩说,快手是较早对视频内容分析产生强烈刚需的公司。
复杂的应用场景和多元的用户分布给 MMU 带来了另一个维度的挑战。负责视频理解方向的朝旭是 MMU 组的老员工,他给机器之心举了一个例子:快手上有很多景色的视频内容,有些景色很美、有空灵感的画面犹如「仙境」,那么快手的标签里就需要描述「仙境」这类景色;但是在学术界的数据集里面,你是不会看到这种「诡异」的标签。
「这不再是一个具体的分类算法问题,而是说你怎么去定义一个合理的标签体系。」
语音组最直观的问题是方言口音。MMU 语音组的月朗介绍说,快手用户的地域分布结构和中国移动互联网的人群分布结构基本一致:一线城市人口占比只有 7% 左右,另外 93% 的人都生活在非一线城市,特别是许多小镇青年、或者是三四线以下的人们说话,都带有很强的口音,这就需要快手收集特定方言区域的语音和文本数据。
音乐组面临的一个难题是给用户唱歌打分。传统的歌唱打分是将用户所唱的歌曲和原唱音频做对比,匹配度越高分数越高。但在快手,许多用户是来自偏远地区的少数民族,他们所唱的民歌山歌在快手的检索库里根本找不到。
「我们现在要求解的不是 1+1 等于 2 的这个问题,而是你在算 1+1 的时候,你发现连纸和笔都没有,」朝旭说。
经过两年的摸索,MMU 组基于多模态技术,逐渐形成了两大业务体系:信息分发和人机交互。前者利用多模态实现精准地视频内容理解,后者利用多模态来辅助人们更好地记录生活。
为了更好地理解这两个方向,我们各举一例:冷启动项目属于内容分发,指的是在用户在刚打开快手 app 时,除了内容和视频中的人物,算法无法获得任何行为数据,因为用户打开快手的一个页面是「发现」而非「关注」,所以快手在冷启动阶段就要提供个性化的内容推荐。MMU 组在 2018 年参与了优化冷启动的项目。
人机交互上,视频配乐是一个典型的多模态理解场景。MMU 音乐组的水寒告诉机器之心,快手需要首先理解视频,包括人脸识别、年龄性别、动作时间地点场景的识别,然后对音乐的风格情感、节奏、主题、以及适合度做场景理解,这个过程涉及到多部门之间的协作,包括视频理解方面、人脸识别、自然语言处理、视频检索、音乐检索、以及最后的推荐算法。

