XGBoost的工程师手册 = XGBoost论文理论解析 + XGBoost实战 + XGBoost面试题
编者:袁宵
XGBoost: A Scalable Tree Boosting System
树提升(Tree boosting)算法是一种非常有效且被广泛使用的机器学习方法。 在本文中,我们描述了一个名为 XGBoost (Extreme Gradient Boosting 极限提升树)的有扩展性的端到端的树提升系统,数据科学家们广泛使用该系统来实现许多机器学习挑战的最新成果。我们提出了一种新颖的稀疏数据感知算法(sparsity-aware algorithm)用于稀疏数据,一种带权值的分位数略图(weighted quantile sketch) 来近似实现树的学习。更重要的是,我们提供有关缓存访问模式(cache access patterns),数据压缩和分片(data compression and sharding)的见解,以构建有延展性的提升树系统。通过结合这些见解,XGBoost可用比现系统少得多的资源来处理数十亿规模的数据。
XGBoost极限梯度提升树的三要素
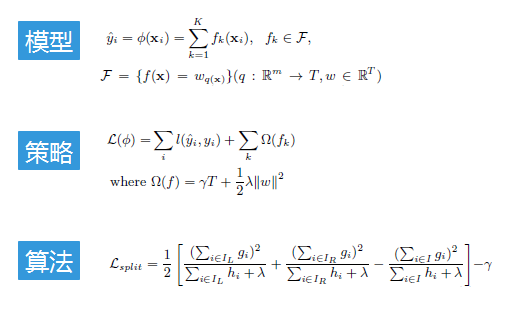
XGBoost模型
给定一个拥有 $n$ 个样例,每个样例有 $m$ 个特征的数据集 $D = \{( \textbf{x}_i, y_i) \} (|D| = n, \textbf{x}_i \in \mathbb R^m, y_i \in \mathbb R)$,一个树集成模型使用 $K$ 个相加的函数去预测输出(如图 1 所示)。
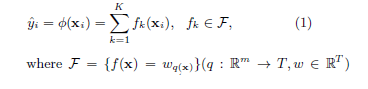
| 符号 | 说明 |
|---|---|
| $F$ | 函数的假设空间,这里指回归树空间,比如CART树 |
| $q(\textbf{x})$ | 表示树结构,作用是把样例 $\textbf{x}$ 映射至对应的树的叶子节点 index |
| $T$ | 树的叶子节点个数 |
| $f_k$ | 第 $k$ 颗树,每颗树对应独立的树结构 $q$ 和叶子节点权重 $w$ |
| $w_i$ | 第 $i$ 个叶子节点的权重 score |
预测过程:对于给定的样例,使用决策树的规则(由 $q(x)$ 树结构决定)把样例映射至每棵树的叶子节点,然后相应叶节点得分score相加(由 $w$ 决定分数score)为最终预测结果。
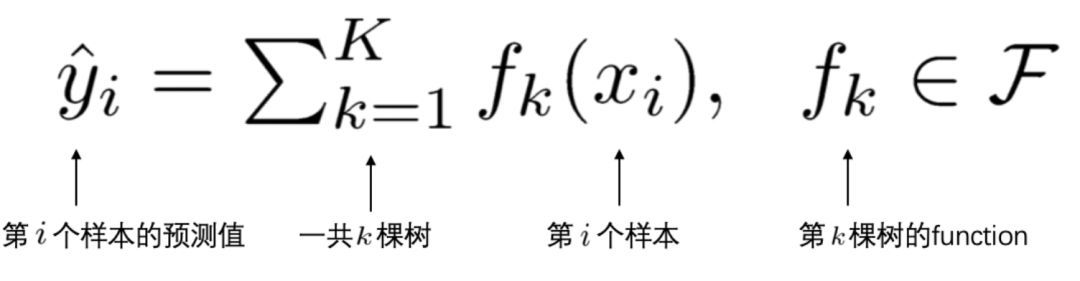
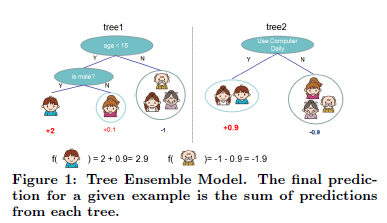
XGBoost策略
为了学习一系列XGBoost模型中的树,最小化以下带正则化的目标函数:
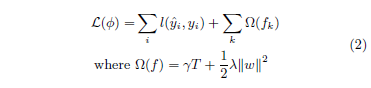
| 符号 | 说明 |
|---|---|
| $l(\hat y_i, y_i)$ | 一个可微分的凸损失函数,用来度量预测值 $\hat y_i$ 与 目标值 $y_i$ 之间的差异 |
| $\Omega(f_k)$ | 正则项,用来惩罚模型(回归树函数)的复杂性 |
目标函数 2 表达的是:

XGBoost优化算法

由于XGBoost中的树集成模型的目标函数(式子2)不能使用传统的在欧几里得空间中的优化算法,而是用以一种相加的方式进行训练的。让 $\hat y_i^{(i)}$ 表示在第 $t$ 次迭代中第 $i$ 个示例的预测值,我们需要加上 $f_t$ 来最小化下面的目标函数:
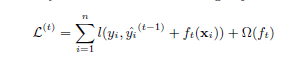
上式意味着我们使用贪心算法(根据)来添加最能提升模型效果的(上述的带正则化的目标函数)函数 $f_t$ 。在一般情况下,二阶近似可用于快速优化目标。
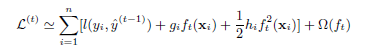
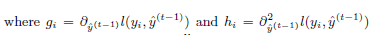
我们可以移除常数项来获得简化形式的第 $t$ 步目标函数。
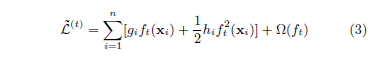
定义: $I_j = \{ i | q(\textbf{x}) = j \}$ 为叶子 $j$ 的实例集。我们可以重写式子3:
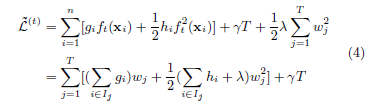
对于一个固定结构的树结构 $q(\textbf{x})$,我们可以计算出树的叶子节点 $j$ 的最优权重 $w^{\star}_j$:
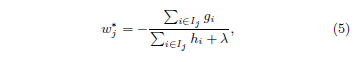
并且可以计算出对应的目标函数最优值:
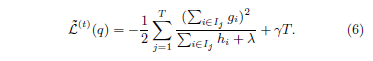
式子6可以作为一个评分函数来衡量一个树结构 $q$ 的质量,这个分数类似于评价决策树的杂质分数,只是它是针对更大范围的目标函数推导出来的。图2说明了如何计算这个分数。
通常不可能枚举所有可能的树结构 $q$。取而代之的是一个贪婪算法,它从一片叶子开始,迭代地向树中添加分支。假设 $I_L$ 和 $I_R$ 是左边的实例集以及分裂后的右结点。令 $I = I_L \cup IR$ 分拆后的损失减少量(也成为增益)为:
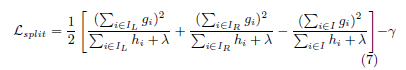
在实践中通常使用式子7来评估候选的数结构(选取增益最大的树)。
(补充推导过程开始)
式子2->式子3:
在式子2中提到,XGBoost 是一个加法模型,假设我们第 $t$ 次迭代要训练的树模型是 $f_t$,则有:
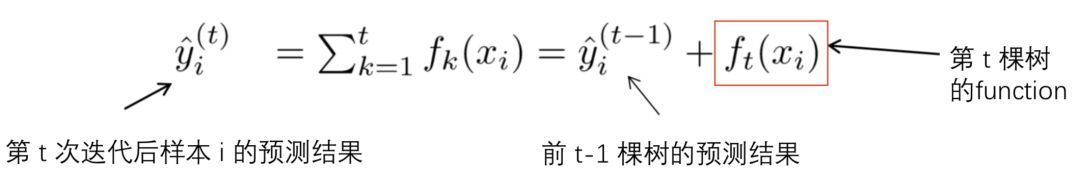
将上式代入2中,注意上式中,只有一个变量,那就是第 $t$ 次迭代要训练的树模型 $f_t$:

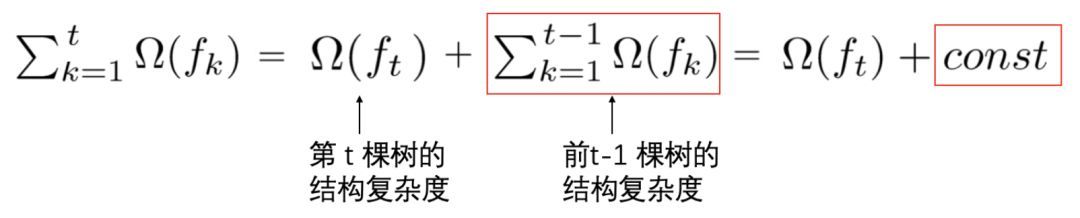
这里我们将正则化项进行了拆分,由于前 $t-1$ 棵树的结构已经确定,因此,前 $t-1$ 棵树的复杂度之和可以用一个常量表示:
已知泰勒公式:

令 $\Delta x = x - x_0$,则 $x = x_0 + \Delta x$,那么泰勒公式的二阶展开形式如下:
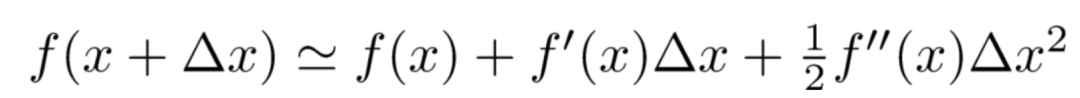
定义损失函数关于 $\hat y ^{(t-1)}$ 的一阶偏导数和二阶偏导数:
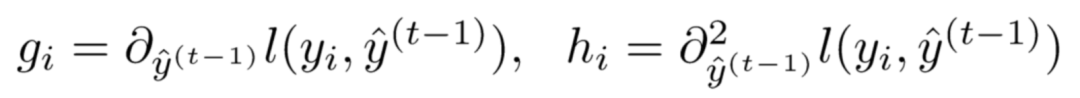
那么,我们的损失函数就可以转化为下式:

将上述二阶展开式,带入到的目标函数 Obj 中,可以得到目标函数 Obj 的近似值:
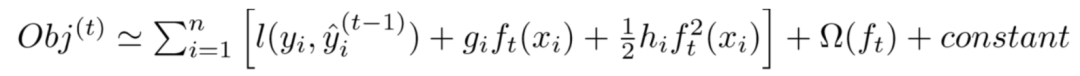
去掉全部常数项,得到目标函数:
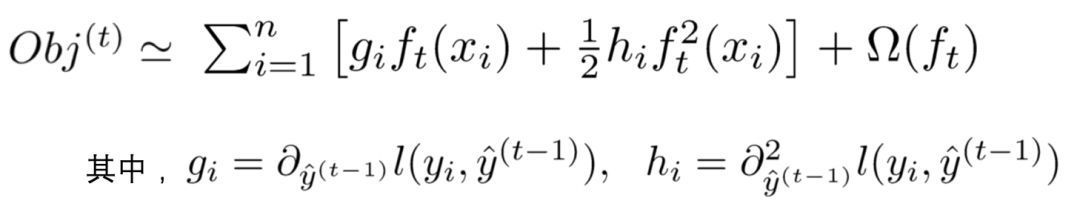
即式子3:
为了便于理解和记忆,归纳上述推导思路如下:
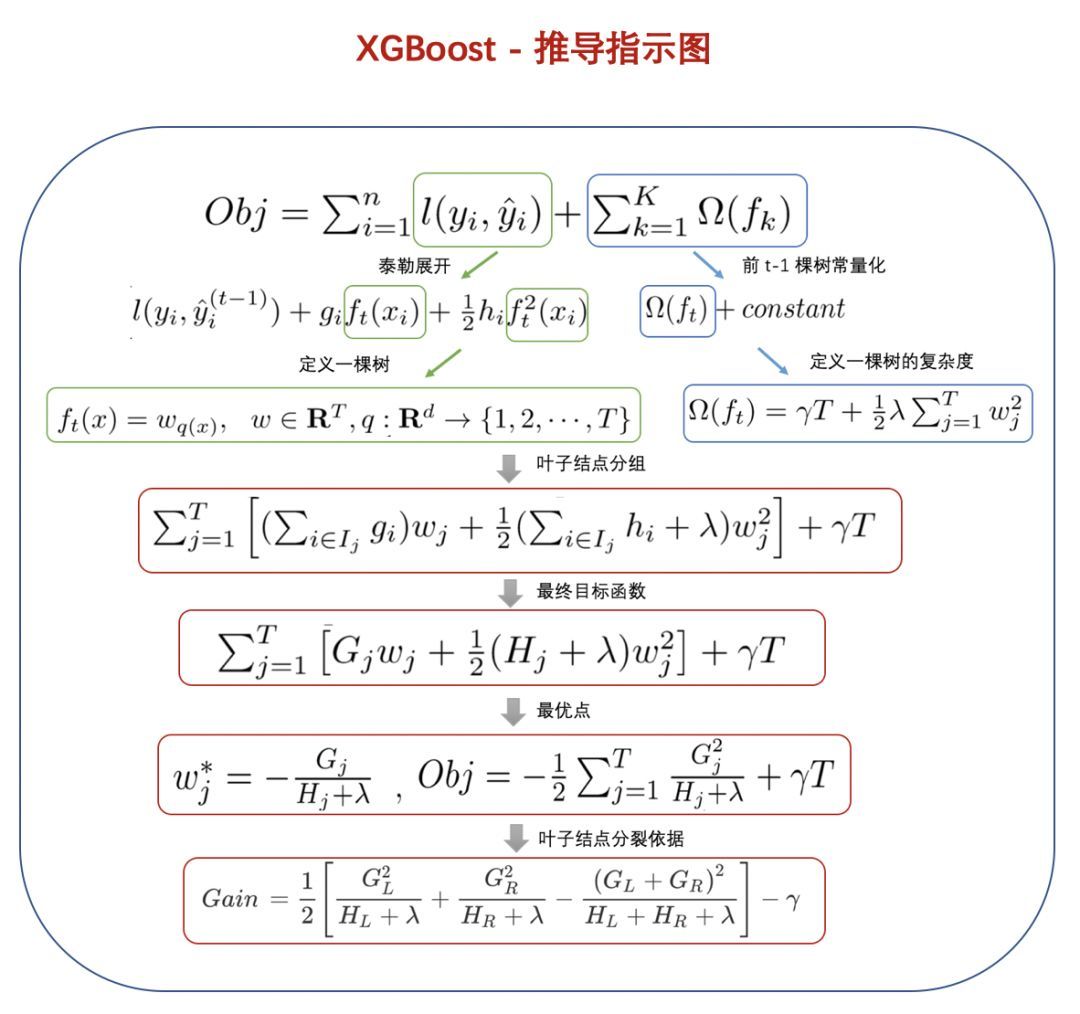
(补充推导过程结束)
收缩和列采样(Shrinkage and Column Subsampling)
除了第二节中提到的正规化目标。另外两种技术被用来进一步防止过度拟合。 第一项技术是收缩(Shrinkage)。 在树木生长的每个步骤之后,收缩率将新增加的权重按因子 $\eta$ 缩放。 与随机优化中的学习率相似,收缩可以减少每棵树的影响,并为将来的树留出空间来改进模型。 第二种技术是列(特征)子采样(Column Subsampling)。 该技术用于RandomForest中,在用于梯度增强的商业软件TreeNet 4中实现,但在现有的开源软件包中未实现。 根据用户反馈,使用列子采样比传统的行子采样(也受支持)可以防止过度拟合。 列子样本的使用也加快了稍后描述的并行算法的计算。
树分裂算法
此处仅仅介绍树分裂算法的原理,深入证明请看陈天齐的论文 XGBoost: A Scalable Tree Boosting System。
精确贪婪算法(Basic Exact Greedy Algorithm)

树学习的关键问题之一是找到由式(7)所示的最佳分割。为了做到这一点,一个分割查找算法列举了所有特性的所有可能的分割。我们称之为精确贪婪算法(Basic Exact Greedy Algorithm),如算法图1所示。枚举连续特性的所有可能的分割是计算上的要求。为了提高效率,算法必须先根据特征值对数据进行排序,然后访问排序后的数据,累积式(7)中结构得分的梯度统计量。
近似算法(Approximate Algorithm)

精确的贪心算法是非常强大的,因为它贪婪地遍历所有可能的分裂点。然而,当数据不能完全装入内存时,就不可能有效地这样做。同样的问题也会出现在分布式设置中。为了在这两种情况下支持有效的梯度树提升(gradient tree boosting),需要一种近似算法。
我们总结了一个近似的框架,该首先根据特征分布的百分位数提出候选分割点。 然后,该算法将连续特征映射到按这些候选点划分的存储桶中,汇总统计信息,并根据汇总的统计信息找到建议(proposal)中的最佳解决方案。
该算法有两种变体,具体取决于何时给出建议(proposal)。 全局变量建议( global variant proposes )在树构建的初始阶段提出所有候选分割,并在所有级别使用相同的分割发现建议。 局部变量建议(local variant re-proposes)每次拆分后都会重新提出局部变量。 全局方法比本地方法需要更少的建议步骤。 但是,对于全局提案,通常需要更多的候选点,因为在每次拆分后都不会重新定义候选。 本地提案对拆分后的候选者进行了筛选,可能更适合于较深的树木。 图3给出了希格斯玻色子数据集上不同算法的比较。我们发现,本地提议确实需要较少的候选者。 如果有足够的候选项,全球提案可能与本地提案一样准确。
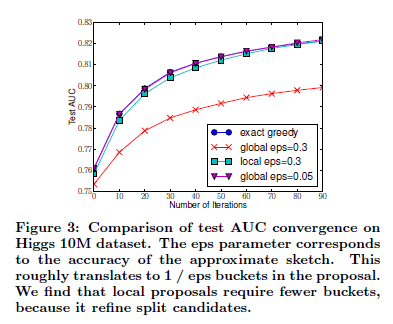
归纳:
- 全局变量建议( global variant proposes )需要更多数据点,速度更快。
- 局部变量建议(local variant re-proposes)适合更深的树木,更准确。
- 如果有足够的候选项,全球提案可能与本地提案一样准确。
加权分位数略图(Weighted Quantile Sketch)
分布式加权直方图算法是XGBoost提出的一种可并行的算法,树节点在进行分裂时,需要计算特征的信息增益,该算法用于高效地生成候选分裂点,对于大型的数据集,如果每个实例具有相等权重时,quantile sketch算法可以解决,但对于加权数据集来说,则不适用,为了解决该问题,XGBoost提出了分布式加权分位数略图(Weighted Quantile Sketch)算法。
稀疏感知算法(sparsity-aware algorithm)
稀疏感知分裂发现,在现实生活中,特征往往都是稀疏的,有几种可能的原因导致特征稀疏:
1)presence of missing values in the data;
2)frequent zero entries in the statistics;
3)artifacts of feature engineering such as one-hot encoding
XGBoost以统一的方式处理缺失的情况,分裂中只选择没有缺失的数据去进行节点分支,然后缺失情况默认指定一个方向。

XGBoost的系统设计
TODO:完善内容
Column Block for Parallel Learning
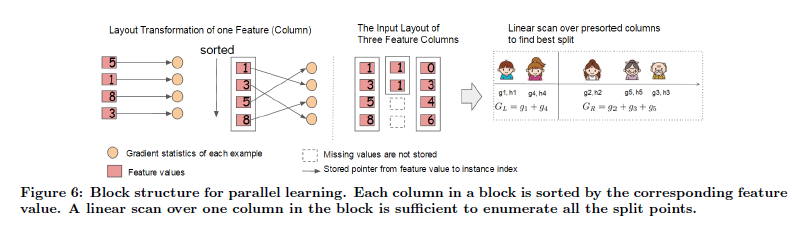
即按列分块并行化学习,XGBoost会对每个特征的值进行排序,使用CSC结构存储到块(block)中,训练过程对特征分枝点计算采用并行处理,寻找合适的分裂点。所以我们常说的XGBoost的并行计算指的是不是树的学习上,而是在特征上的并行处理。
所以,这里XGBoost在设计系统的时候,预留额外的空间(Block)赖储存排序好的数据,这里的排序,是按照每列的值排序,所以索引在不同特征之间是不一样的。
所以,特征预排序只需要在开始的时候做一次即可,后续可以重复调用,大大减少了每次排序的耗时,所以也可以实现并行化学习,计算每个特征的信息增益。
Cache-aware Access
缓存感知访问,对于有大量数据或者说分布式系统来说,我们不可能将所有的数据都放进内存里面。因此我们都需要将其放在外存上或者分布式存储。但是这有一个问题,这样做每次都要从外存上读取数据到内存,这将会是十分耗时的操作。
因此我们使用预读取(prefetching)将下一块将要读取的数据预先放进内存里面。其实就是多开一个线程,该线程与训练的线程独立并负责数据读取。此外,还要考虑Block的大小问题。如果我们设置最大的block来存储所有样本在k特征上的值和梯度的话,cache未必能一次性处理如此多的梯度做统计。如果我们设置过少block size,这样不能充分利用的多线程的优势,也就是训练线程已经训练完数据,但是prefetching thread还没把数据放入内存或者cache中。
经过测试,作者发现block size设置为2^16个examples最好。
Blocks for Out-of-core Computation
因为XGBoost是要设计一个高效使用资源的系统,所以各种机器资源都要用上,除了CPU和内存之外,磁盘空间也可以利用来处理数据。为了实现这个功能,我们可以将数据分成多个块并将每个块储存在磁盘上。
在计算过程中,使用独立的线程将Block预提取到主内存缓冲区,这样子数据计算和磁盘读取可以同步进行,但由于IO非常耗时,所以还有2种技术来改善这种核外计算:
Block Compression: 块压缩,并当加载到主内存时由独立线程动态解压缩;
Block Sharding: 块分片,即将数据分片到多个磁盘,为每个磁盘分配一个线程,将数据提取到内存缓冲区,然后每次训练线程的时候交替地从每个缓冲区读取数据,有助于在多个磁盘可用时,增加读取的吞吐量。
XGBoost相关证明
TODO:完善内容
XGBoost应用
实战
TODO:完善内容
调参
Complete Guide to Parameter Tuning in XGBoost with codes in Python
XGBoost面试题
- 简单介绍一下XGB
- XGBoost为什么使用泰勒二阶展开?为什么用二阶信息不用一阶?
- XGBoost在什么地方做的剪枝,怎么做的?
- XGBoost如何分布式?特征分布式和数据分布式? 各有什么存在的问题?
- XGBoost里处理缺失值的方法?
- XGBoost有那些优化?
- XGBoost如何寻找最优特征?是又放回还是无放回的呢?
- GBDT和XGBoost的区别是什么?
- lightgbm和xgboost有什么区别?他们的loss一样么? 算法层面有什么区别?
- 比较一下LR和GBDT?GBDT在什么情况下比逻辑回归算法要差?
- RF和GBDT的区别;RF怎么解决的过拟合问题;
- 怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感?
- 随机森林是怎样避免ID3算法信息增益的缺点的?
- gbdt对标量特征要不要onehot编码?
- CART为什么选择基尼系数作为特征选择标准 ?
- 如何解决类别不平衡问题?
- GBDT 如何用于分类 ?
参考文献
- 理解XGBoost原理,查看陈天齐的PPT Introduction to Boosted Trees 和论文 XGBoost: A Scalable Tree Boosting System。
- 使用XGBoost,查看GitHub 可扩展,可移植和分布式梯度提升(GBDT,GBRT或GBM)库 xgboost。
- 阅读:XGBoost超详细推导,终于有人讲明白了! / 珍藏版 | 20道XGBoost面试题,你会几个?(上篇) / 珍藏版 | 20道XGBoost面试题,你会几个?(下篇)
- 带你撸一遍 XGBoost论文

