This chapter shows how to implement various SVM methods with TensorFlow. We first create a linear SVM and also show how it can be used for regression. We then introduce kernels (RBF Gaussian kernel) and show how to use it to split up non-linear data. We finish with a multi-dimensional implementation of non-linear SVMs to work with multiple classes.
Model We will aim to maximize the margin width, 2/||A||, or minimize ||A||. We allow for a soft margin by having an error term in the loss function which is the max(0, 1-pred*actual).
This function shows how to use TensorFlow to create a soft margin SVM We will use the iris data, specifically:
$x_1 =$ Sepal Length
$x_2 =$ Petal Width
Class 1 : I. setosa
Class -1: not I. setosa
We know here that x and y are linearly seperable for I. setosa classification.
Note that we implement the soft margin with an allowable margin of error for points. The margin of error term is given by ‘alpha’ below. To behave like a hard margin SVM, set alpha = 0. (in notebook code block #7)
1 2 3 4 5 6
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from sklearn import datasets from tensorflow.python.framework import ops ops.reset_default_graph()
Set a random seed and start a computational graph.
# Create variables for SVM A = tf.Variable(tf.random_normal(shape=[2, 1])) b = tf.Variable(tf.random_normal(shape=[1, 1]))
Declare our model and L2 Norm
SVM linear model is given by the equation:
Our loss function will be the above quantity and we will tell TensorFlow to minimize it. Note that $n$ is the number of points (in a batch), $A$ is the hyperplane-normal vector (to solve for), $b$ is the hyperplane-offset (to solve for), and $\alpha$ is the soft-margin parameter.
1 2 3 4 5
# Declare model operations model_output = tf.subtract(tf.matmul(x_data, A), b)
# Declare vector L2 'norm' function squared l2_norm = tf.reduce_sum(tf.square(A))
Here we make our special loss function based on the classification of the points (which side of the line they fall on).
Also, note that alpha is the soft-margin term and an be increased to allow for more erroroneous classification points. For hard-margin behaviour, set alpha = 0.
1 2 3 4 5 6 7 8 9 10 11
# Declare loss function # Loss = max(0, 1-pred*actual) + alpha * L2_norm(A)^2 # L2 regularization parameter, alpha
alpha = tf.constant([0.01])
# Margin term in loss classification_term = tf.reduce_mean(tf.maximum(0., tf.subtract(1., tf.multiply(model_output, y_target))))
# Put terms together loss = tf.add(classification_term, tf.multiply(alpha, l2_norm))
Creat the prediction function, optimization algorithm, and initialize the variables.
if (i + 1) % 75 == 0: print('Step #{} A = {}, b = {}'.format( str(i+1), str(sess.run(A)), str(sess.run(b)) )) print('Loss = ' + str(temp_loss))
Step #75 A = [[0.65587175]
[0.73911524]], b = [[0.8189382]]
Loss = [3.477592]
Step #150 A = [[0.30820864]
[0.37043768]], b = [[1.1588708]]
Loss = [1.8782018]
Step #225 A = [[0.05466489]
[0.01620324]], b = [[1.3756151]]
Loss = [0.61904156]
Step #300 A = [[ 0.0723089 ]
[-0.10384972]], b = [[1.2969997]]
Loss = [0.50430346]
Step #375 A = [[ 0.08872697]
[-0.21590038]], b = [[1.214785]]
Loss = [0.5581]
Step #450 A = [[ 0.10302152]
[-0.33577552]], b = [[1.1402861]]
Loss = [0.60070616]
Step #525 A = [[ 0.12028296]
[-0.46366042]], b = [[1.0620526]]
Loss = [0.47809908]
Step #600 A = [[ 0.145114 ]
[-0.5994784]], b = [[0.97037107]]
Loss = [0.56837624]
Step #675 A = [[ 0.16354088]
[-0.7458743 ]], b = [[0.8814289]]
Loss = [0.5452542]
Step #750 A = [[ 0.17879468]
[-0.90772235]], b = [[0.7907687]]
Loss = [0.47175956]
Step #825 A = [[ 0.20936723]
[-1.0691159 ]], b = [[0.68023866]]
Loss = [0.41458404]
Step #900 A = [[ 0.236106 ]
[-1.2391785]], b = [[0.5687398]]
Loss = [0.29367676]
Step #975 A = [[ 0.25400215]
[-1.4175524 ]], b = [[0.46441486]]
Loss = [0.27020118]
Step #1050 A = [[ 0.28435734]
[-1.5984066 ]], b = [[0.34036276]]
Loss = [0.19518965]
Step #1125 A = [[ 0.28947413]
[-1.780023 ]], b = [[0.24134117]]
Loss = [0.17559259]
Step #1200 A = [[ 0.2927576]
[-1.930816 ]], b = [[0.15315719]]
Loss = [0.13242653]
Step #1275 A = [[ 0.3031533]
[-2.0399208]], b = [[0.06639722]]
Loss = [0.14762701]
Step #1350 A = [[ 0.29892927]
[-2.1220415 ]], b = [[0.00746888]]
Loss = [0.1029826]
Step #1425 A = [[ 0.29492435]
[-2.1905353 ]], b = [[-0.04703728]]
Loss = [0.11851373]
Step #1500 A = [[ 0.29012206]
[-2.2488031 ]], b = [[-0.09580647]]
Loss = [0.1065909]
Now we extract the linear coefficients and get the SVM boundary line.
# Extract x1 and x2 vals x1_vals = [d[1] for d in x_vals]
# Get best fit line best_fit = [] for i in x1_vals: best_fit.append(slope*i+y_intercept)
# Separate I. setosa setosa_x = [d[1] for i, d in enumerate(x_vals) if y_vals[i] == 1] setosa_y = [d[0] for i, d in enumerate(x_vals) if y_vals[i] == 1] not_setosa_x = [d[1] for i, d in enumerate(x_vals) if y_vals[i] == -1] not_setosa_y = [d[0] for i, d in enumerate(x_vals) if y_vals[i] == -1]
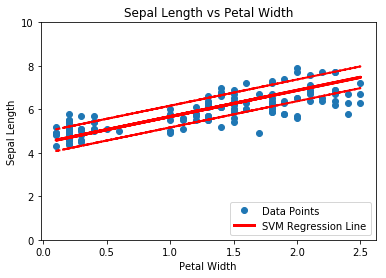
This function shows how to use TensorFlow to solve support vector regression. We are going to find the line that has the maximum margin which INCLUDES as many points as possible.
We will use the iris data, specifically:
$y =$ Sepal Length
$x =$ Pedal Width
To start, load the necessary libraries:
1 2 3 4 5 6
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from sklearn import datasets from tensorflow.python.framework import ops ops.reset_default_graph()
Create a TF Graph Session:
1
sess = tf.Session()
Load the iris data, use the Sepal Length and Petal width for SVM regression.
1 2 3 4 5 6 7 8 9 10 11 12 13
# Load the data # iris.data = [(Sepal Length, Sepal Width, Petal Length, Petal Width)] iris = datasets.load_iris() x_vals = np.array([x[3] for x in iris.data]) y_vals = np.array([y[0] for y in iris.data])
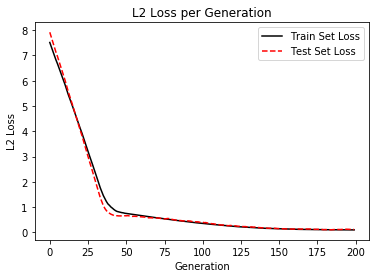
temp_test_loss = sess.run(loss, feed_dict={x_data: np.transpose([x_vals_test]), y_target: np.transpose([y_vals_test])}) test_loss.append(temp_test_loss) if (i+1)%50==0: print('-----------') print('Generation: ' + str(i+1)) print('A = ' + str(sess.run(A)) + ' b = ' + str(sess.run(b))) print('Train Loss = ' + str(temp_train_loss)) print('Test Loss = ' + str(temp_test_loss))
-----------
Generation: 50
A = [[2.4289258]] b = [[2.271079]]
Train Loss = 0.7553672
Test Loss = 0.65542704
-----------
Generation: 100
A = [[1.9204257]] b = [[3.4155781]]
Train Loss = 0.3573223
Test Loss = 0.39466858
-----------
Generation: 150
A = [[1.3823755]] b = [[4.095077]]
Train Loss = 0.14115657
Test Loss = 0.14801341
-----------
Generation: 200
A = [[1.204475]] b = [[4.462577]]
Train Loss = 0.09575871
Test Loss = 0.11255897
For plotting, we need to extract the coefficients and get the best fit line. (Also the upper and lower margins.)
# Get best fit line best_fit = [] best_fit_upper = [] best_fit_lower = [] for i in x_vals: best_fit.append(slope*i+y_intercept) best_fit_upper.append(slope*i+y_intercept+width) best_fit_lower.append(slope*i+y_intercept-width)
# Plot fit with data plt.plot(x_vals, y_vals, 'o', label='Data Points') plt.plot(x_vals, best_fit, 'r-', label='SVM Regression Line', linewidth=3) plt.plot(x_vals, best_fit_upper, 'r--', linewidth=2) plt.plot(x_vals, best_fit_lower, 'r--', linewidth=2) plt.ylim([0, 10]) plt.legend(loc='lower right') plt.title('Sepal Length vs Petal Width') plt.xlabel('Petal Width') plt.ylabel('Sepal Length') plt.show()
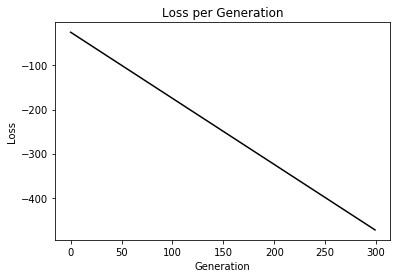
# Plot loss over time plt.plot(train_loss, 'k-', label='Train Set Loss') plt.plot(test_loss, 'r--', label='Test Set Loss') plt.title('L2 Loss per Generation') plt.xlabel('Generation') plt.ylabel('L2 Loss') plt.legend(loc='upper right') plt.show()
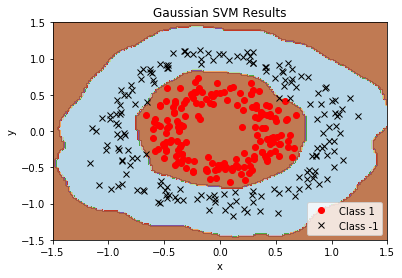
Linear SVMs are very powerful. But sometimes the data are not very linear. To this end, we can use the ‘kernel trick’ to map our data into a higher dimensional space, where it may be linearly separable. Doing this allows us to separate out non-linear classes. See the below example.
If we attempt to separate the below circular-ring shaped classes with a standard linear SVM, we fail.
But if we separate it with a Gaussian-RBF kernel, we can find a linear separator in a higher dimension that works a lot better.
This function wll illustrate how to implement various kernels in TensorFlow.
Linear Kernel:
Gaussian Kernel (RBF):
We start by loading the necessary libraries
1 2 3 4 5 6
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from sklearn import datasets from tensorflow.python.framework import ops ops.reset_default_graph()
Start a computational graph session:
1
sess = tf.Session()
For this example, we will generate fake non-linear data. The data we will generate is concentric ring data.
1 2 3 4 5 6 7
# Generate non-lnear data (x_vals, y_vals) = datasets.make_circles(n_samples=350, factor=.5, noise=.1) y_vals = np.array([1if y==1else-1for y in y_vals]) class1_x = [x[0] for i,x in enumerate(x_vals) if y_vals[i]==1] class1_y = [x[1] for i,x in enumerate(x_vals) if y_vals[i]==1] class2_x = [x[0] for i,x in enumerate(x_vals) if y_vals[i]==-1] class2_y = [x[1] for i,x in enumerate(x_vals) if y_vals[i]==-1]
We declare the batch size (large for SVMs), create the placeholders, and declare the $b$ variable for the SVM model.
# Create variables for svm b = tf.Variable(tf.random_normal(shape=[1,batch_size]))
Here we will apply the kernel. Note that the Linear Kernel is commented out. If you choose to use the linear kernel, then uncomment the linear my_kernel variable, and comment out the five RBF kernel lines.
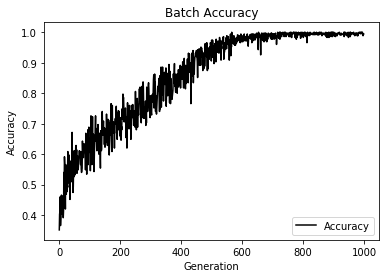
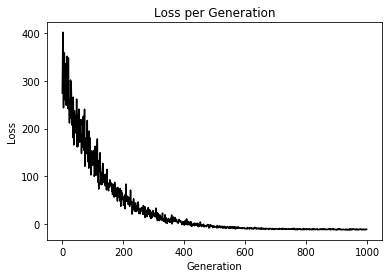
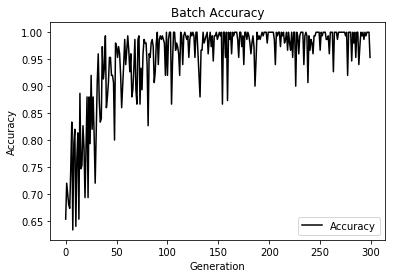
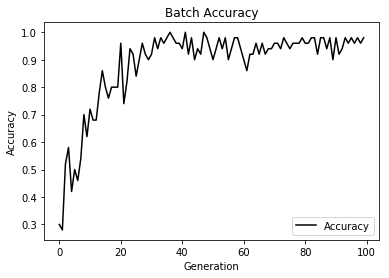
In order to use the kernel to classify points, we create a prediction operation. This prediction operation will be the sign ( positive or negative ) of the model outputs. The accuracy can then be computed if we know the actual target labels.
Step #250
Loss = 46.040836
Step #500
Loss = -5.635271
Step #750
Loss = -11.075392
Step #1000
Loss = -11.158321
To plot a pretty picture of the regions we fit, we create a fine mesh to run through our model and get the predictions. (This is very similar to the SVM plotting code from sci-kit learn).
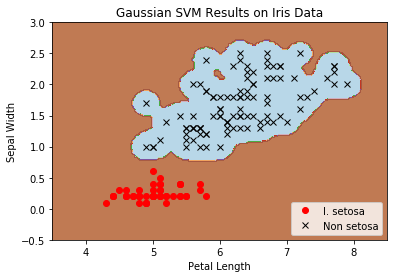
Here we show how to use the prior Gaussian RBF kernel to predict I.setosa from the Iris dataset.
This function wll illustrate how to implement the gaussian kernel on the iris dataset.
Gaussian Kernel:
We start by loading the necessary libraries and resetting the computational graph.
1 2 3 4 5 6
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from sklearn import datasets from tensorflow.python.framework import ops ops.reset_default_graph()
Create a graph session
1
sess = tf.Session()
Load the Iris Data
Our x values will be $(x_1, x_2)$ where,
$x_1 =$ ‘Sepal Length’
$x_2 =$ ‘Petal Width’
The Target values will be wether or not the flower species is Iris Setosa.
1 2 3 4 5 6 7 8 9
# Load the data # iris.data = [(Sepal Length, Sepal Width, Petal Length, Petal Width)] iris = datasets.load_iris() x_vals = np.array([[x[0], x[3]] for x in iris.data]) y_vals = np.array([1if y==0else-1for y in iris.target]) class1_x = [x[0] for i,x in enumerate(x_vals) if y_vals[i]==1] class1_y = [x[1] for i,x in enumerate(x_vals) if y_vals[i]==1] class2_x = [x[0] for i,x in enumerate(x_vals) if y_vals[i]==-1] class2_y = [x[1] for i,x in enumerate(x_vals) if y_vals[i]==-1]
Model Parameters
We now declare our batch size, placeholders, and the fitted b-value for the SVM kernel. Note that we will create a separate placeholder to feed in the prediction grid for plotting.
# Create variables for svm b = tf.Variable(tf.random_normal(shape=[1,batch_size]))
Gaussian (RBF) Kernel
We create the gaussian kernel that is used to transform the data points into a higher dimensional space.
The Kernel of two points, $x$ and $x’$ is given as
For $\gamma$ very small, the kernel is very wide, and vice-versa for large $\gamma$ values. This means that large $\gamma$ leads to high bias and low variance models.
If we have a vector of points, $x$ of size (batch_size, 2), then our kernel calculation becomes
Format the test points together with the predictions:
1 2 3
for ix, point in enumerate(test_points): point_pred = test_predictions.ravel()[ix] print('Point {} is predicted to be in class {}'.format(point, point_pred))
Point [4. 0.] is predicted to be in class 1.0
Point [5. 0.] is predicted to be in class 1.0
Point [6. 0.] is predicted to be in class 1.0
Point [7. 0.] is predicted to be in class 1.0
Point [4. 1.] is predicted to be in class 1.0
Point [5. 1.] is predicted to be in class -1.0
Point [6. 1.] is predicted to be in class -1.0
Point [7. 1.] is predicted to be in class 1.0
Point [4. 2.] is predicted to be in class 1.0
Point [5. 2.] is predicted to be in class 1.0
Point [6. 2.] is predicted to be in class -1.0
Point [7. 2.] is predicted to be in class -1.0
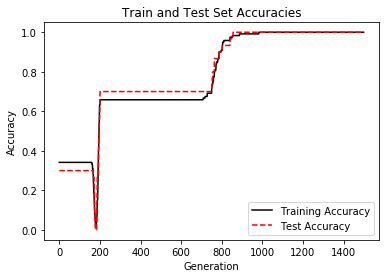
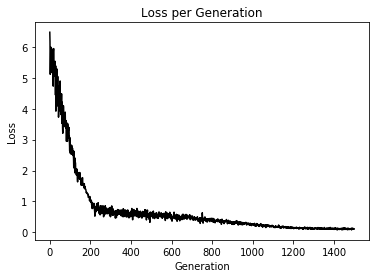
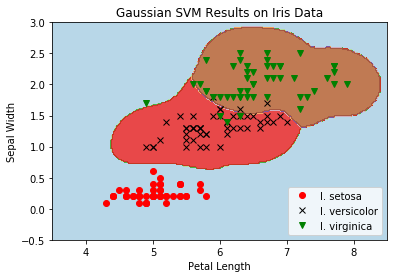
Here, we implement a 1-vs-all voting method for a multiclass SVM. We attempt to separate the three Iris flower classes with TensorFlow.
This function wll illustrate how to implement the gaussian kernel with multiple classes on the iris dataset.
Gaussian Kernel:
X : (Sepal Length, Petal Width)
Y: (I. setosa, I. virginica, I. versicolor) (3 classes)
Basic idea: introduce an extra dimension to do one vs all classification.
The prediction of a point will be the category with the largest margin or distance to boundary.
We start by loading the necessary libraries.
1 2 3 4 5 6
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from sklearn import datasets from tensorflow.python.framework import ops ops.reset_default_graph()
Start a computational graph session.
1
sess = tf.Session()
Now we load the iris data.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Load the data # iris.data = [(Sepal Length, Sepal Width, Petal Length, Petal Width)] iris = datasets.load_iris() x_vals = np.array([[x[0], x[3]] for x in iris.data]) y_vals1 = np.array([1if y==0else-1for y in iris.target]) y_vals2 = np.array([1if y==1else-1for y in iris.target]) y_vals3 = np.array([1if y==2else-1for y in iris.target]) y_vals = np.array([y_vals1, y_vals2, y_vals3]) class1_x = [x[0] for i,x in enumerate(x_vals) if iris.target[i]==0] class1_y = [x[1] for i,x in enumerate(x_vals) if iris.target[i]==0] class2_x = [x[0] for i,x in enumerate(x_vals) if iris.target[i]==1] class2_y = [x[1] for i,x in enumerate(x_vals) if iris.target[i]==1] class3_x = [x[0] for i,x in enumerate(x_vals) if iris.target[i]==2] class3_y = [x[1] for i,x in enumerate(x_vals) if iris.target[i]==2]
Declare the batch size
1
batch_size = 50
Initialize placeholders and create the variables for multiclass SVM