For a more pragmatic approach and introduction to neural networks, Andrej Karpathy has written a great summary and JavaScript examples called A Hacker’s Guide to Neural Networks. The write up is located here: http://karpathy.github.io/neuralnets/
Another site that summarizes some good notes on deep learning is called Deep Learning for Beginners by Ian Goodfellow, Yoshua Bengio, and Aaron Courville. This web page can be found here: http://randomekek.github.io/deep/deeplearning.html
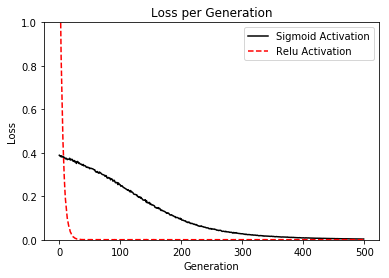
# Declare the loss function as the difference between # the output and a target value, 0.75. loss1 = tf.reduce_mean(tf.square(tf.subtract(sigmoid_activation, 0.75))) loss2 = tf.reduce_mean(tf.square(tf.subtract(relu_activation, 0.75)))
# Run loop across gate print('\nOptimizing Sigmoid AND Relu Output to 0.75') loss_vec_sigmoid = [] loss_vec_relu = [] for i in range(500): rand_indices = np.random.choice(len(x), size=batch_size) x_vals = np.transpose([x[rand_indices]]) sess.run(train_step_sigmoid, feed_dict={x_data: x_vals}) sess.run(train_step_relu, feed_dict={x_data: x_vals})
The model will have one hidden layer. If the hidden layer has 10 nodes, then the model will look like the following:
We will use the ReLU activation functions.
For the loss function, we will use the average MSE across the batch. We will illustrate how to create a one hidden layer NN
We will use the iris data for this exercise
We will build a one-hidden layer neural network to predict the fourth attribute, Petal Width from the other three (Sepal length, Sepal width, Petal length).
1 2 3 4 5
import matplotlib.pyplot as plt import numpy as np import tensorflow as tf from sklearn import datasets from tensorflow.python.framework import ops
1
ops.reset_default_graph()
1 2 3
iris = datasets.load_iris() x_vals = np.array([x[0:3] for x in iris.data]) y_vals = np.array([x[3] for x in iris.data])
1 2
# Create graph session sess = tf.Session()
1 2 3 4
# make results reproducible seed = 2 tf.set_random_seed(seed) np.random.seed(seed)
Generation: 50. Loss = 0.5279015
Generation: 100. Loss = 0.22871476
Generation: 150. Loss = 0.17977345
Generation: 200. Loss = 0.10849865
Generation: 250. Loss = 0.24002916
Generation: 300. Loss = 0.15323998
Generation: 350. Loss = 0.1659011
Generation: 400. Loss = 0.09752482
Generation: 450. Loss = 0.121614255
Generation: 500. Loss = 0.1300937
1 2 3 4 5 6 7 8 9
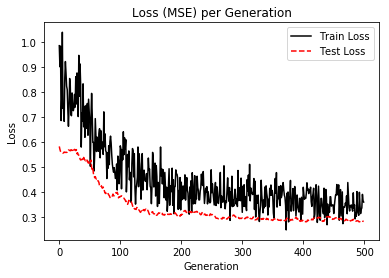
%matplotlib inline # Plot loss (MSE) over time plt.plot(loss_vec, 'k-', label='Train Loss') plt.plot(test_loss, 'r--', label='Test Loss') plt.title('Loss (MSE) per Generation') plt.legend(loc='upper right') plt.xlabel('Generation') plt.ylabel('Loss') plt.show()
We will illustrate how to use different types of layers in TensorFlow
The layers of interest are:
Convolutional Layer
Activation Layer
Max-Pool Layer
Fully Connected Layer
We will generate two different data sets for this script, a 1-D data set (row of data) and a 2-D data set (similar to picture)
1 2 3 4 5 6 7 8
import tensorflow as tf import matplotlib.pyplot as plt import csv import os import random import numpy as np import random from tensorflow.python.framework import ops
#--------Convolution-------- # both [batch#, width, height, channels] and [batch#, height, width, channels] are correct.Nut (input, filter, strides, padding) dimensional relations should keep correspondence. defconv_layer_1d(input_1d, my_filter,stride): # TensorFlow's 'conv2d()' function only works with 4D arrays: # [batch#, width, height, channels], we have 1 batch, and # width = 1, but height = the length of the input, and 1 channel. # So next we create the 4D array by inserting dimension 1's. input_2d = tf.expand_dims(input_1d, 0) input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Perform convolution with stride = 1, if we wanted to increase the stride, # to say '2', then strides=[1,1,2,1] convolution_output = tf.nn.conv2d(input_4d, filter=my_filter, strides=[1,1,stride,1], padding="VALID") # Get rid of extra dimensions conv_output_1d = tf.squeeze(convolution_output) return(conv_output_1d)
#--------Max Pool-------- defmax_pool(input_1d, width,stride): # Just like 'conv2d()' above, max_pool() works with 4D arrays. # [batch_size=1, width=1, height=num_input, channels=1] input_2d = tf.expand_dims(input_1d, 0) input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Perform the max pooling with strides = [1,1,1,1] # If we wanted to increase the stride on our data dimension, say by # a factor of '2', we put strides = [1, 1, 2, 1] # We will also need to specify the width of the max-window ('width') pool_output = tf.nn.max_pool(input_4d, ksize=[1, 1, width, 1], strides=[1, 1, stride, 1], padding='VALID') # Get rid of extra dimensions pool_output_1d = tf.squeeze(pool_output) return(pool_output_1d)
#--------Fully Connected-------- deffully_connected(input_layer, num_outputs): # First we find the needed shape of the multiplication weight matrix: # The dimension will be (length of input) by (num_outputs) weight_shape = tf.squeeze(tf.stack([tf.shape(input_layer),[num_outputs]])) # Initialize such weight weight = tf.random_normal(weight_shape, stddev=0.1) # Initialize the bias bias = tf.random_normal(shape=[num_outputs]) # Make the 1D input array into a 2D array for matrix multiplication input_layer_2d = tf.expand_dims(input_layer, 0) # Perform the matrix multiplication and add the bias full_output = tf.add(tf.matmul(input_layer_2d, weight), bias) # Get rid of extra dimensions full_output_1d = tf.squeeze(full_output) return(full_output_1d)
# Convolution defconv_layer_2d(input_2d, my_filter,stride_size): # TensorFlow's 'conv2d()' function only works with 4D arrays: # [batch#, width, height, channels], we have 1 batch, and # 1 channel, but we do have width AND height this time. # So next we create the 4D array by inserting dimension 1's. input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Note the stride difference below! convolution_output = tf.nn.conv2d(input_4d, filter=my_filter, strides=[1,stride_size,stride_size,1], padding="VALID") # Get rid of unnecessary dimensions conv_output_2d = tf.squeeze(convolution_output) return(conv_output_2d)
#--------Max Pool-------- defmax_pool(input_2d, width, height,stride): # Just like 'conv2d()' above, max_pool() works with 4D arrays. # [batch_size=1, width=given, height=given, channels=1] input_3d = tf.expand_dims(input_2d, 0) input_4d = tf.expand_dims(input_3d, 3) # Perform the max pooling with strides = [1,1,1,1] # If we wanted to increase the stride on our data dimension, say by # a factor of '2', we put strides = [1, 2, 2, 1] pool_output = tf.nn.max_pool(input_4d, ksize=[1, height, width, 1], strides=[1, stride, stride, 1], padding='VALID') # Get rid of unnecessary dimensions pool_output_2d = tf.squeeze(pool_output) return(pool_output_2d)
#--------Fully Connected-------- deffully_connected(input_layer, num_outputs): # In order to connect our whole W byH 2d array, we first flatten it out to # a W times H 1D array. flat_input = tf.reshape(input_layer, [-1]) # We then find out how long it is, and create an array for the shape of # the multiplication weight = (WxH) by (num_outputs) weight_shape = tf.squeeze(tf.stack([tf.shape(flat_input),[num_outputs]])) # Initialize the weight weight = tf.random_normal(weight_shape, stddev=0.1) # Initialize the bias bias = tf.random_normal(shape=[num_outputs]) # Now make the flat 1D array into a 2D array for multiplication input_2d = tf.expand_dims(flat_input, 0) # Multiply and add the bias full_output = tf.add(tf.matmul(input_2d, weight), bias) # Get rid of extra dimension full_output_2d = tf.squeeze(full_output) return(full_output_2d)
We will illustrate how to use a Multiple Layer Network in TensorFlow
Low Birthrate data:
1 2 3 4 5 6 7 8 9 10 11 12 13
#Columns Variable Abbreviation #--------------------------------------------------------------------- # Low Birth Weight (0 = Birth Weight >= 2500g, LOW # 1 = Birth Weight < 2500g) # Age of the Mother in Years AGE # Weight in Pounds at the Last Menstrual Period LWT # Race (1 = White, 2 = Black, 3 = Other) RACE # Smoking Status During Pregnancy (1 = Yes, 0 = No) SMOKE # History of Premature Labor (0 = None 1 = One, etc.) PTL # History of Hypertension (1 = Yes, 0 = No) HT # Presence of Uterine Irritability (1 = Yes, 0 = No) UI # Birth Weight in Grams BWT #---------------------------------------------------------------------
The multiple neural network layer we will create will be composed of three fully connected hidden layers, with node sizes 50, 25, and 5
1 2 3 4 5 6 7 8 9 10
import tensorflow as tf import matplotlib.pyplot as plt import csv import os import os.path import random import numpy as np import random import requests from tensorflow.python.framework import ops
# name of data file birth_weight_file = 'birth_weight.csv'
# download data and create data file if file does not exist in current directory ifnot os.path.exists(birth_weight_file): birthdata_url = 'https://github.com/nfmcclure/tensorflow_cookbook/raw/master/01_Introduction/07_Working_with_Data_Sources/birthweight_data/birthweight.dat' birth_file = requests.get(birthdata_url) birth_data = birth_file.text.split('\r\n') birth_header = birth_data[0].split('\t') birth_data = [[float(x) for x in y.split('\t') if len(x)>=1] for y in birth_data[1:] if len(y)>=1] with open(birth_weight_file, "w") as f: writer = csv.writer(f) writer.writerows([birth_header]) writer.writerows(birth_data) f.close()
# read birth weight data into memory birth_data = [] with open(birth_weight_file, newline='') as csvfile: csv_reader = csv.reader(csvfile) birth_header = next(csv_reader) for row in csv_reader: birth_data.append(row)
birth_data = [[float(x) for x in row] for row in birth_data]
birth_data = [data for data in birth_data if len(data)==9]
# Extract y-target (birth weight) y_vals = np.array([x[8] for x in birth_data])
# Filter for features of interest cols_of_interest = ['AGE', 'LWT', 'RACE', 'SMOKE', 'PTL', 'HT', 'UI'] x_vals = np.array([[x[ix] for ix, feature in enumerate(birth_header) if feature in cols_of_interest] for x in birth_data])
Train model
Here we reset any graph in memory and then start to create our graph and vectors.
Now we scale our dataset by the min/max of the _training set_. We start by recording the mins and maxs of the training set. (We use this on scaling the test set, and evaluation set later on).
1 2 3 4 5 6 7 8 9 10
# Record training column max and min for scaling of non-training data train_max = np.max(x_vals_train, axis=0) train_min = np.min(x_vals_train, axis=0)
# Normalize by column (min-max norm to be between 0 and 1) defnormalize_cols(mat, max_vals, min_vals): return (mat - min_vals) / (max_vals - min_vals)
Generation: 25. Loss = 15990.672
Generation: 50. Loss = 4621.7314
Generation: 75. Loss = 2795.2063
Generation: 100. Loss = 2217.2898
Generation: 125. Loss = 2295.6526
Generation: 150. Loss = 2047.0446
Generation: 175. Loss = 1915.7665
Generation: 200. Loss = 1732.4609
Generation: 225. Loss = 1684.7881
Generation: 250. Loss = 1576.6495
Generation: 275. Loss = 1579.0376
Generation: 300. Loss = 1456.1991
Generation: 325. Loss = 1521.6523
Generation: 350. Loss = 1294.7655
Generation: 375. Loss = 1507.561
Generation: 400. Loss = 1221.8282
Generation: 425. Loss = 1636.6687
Generation: 450. Loss = 1306.686
Generation: 475. Loss = 1564.3484
Generation: 500. Loss = 1360.876
Here is code that will plot the loss by generation.
1 2 3 4 5 6 7 8 9
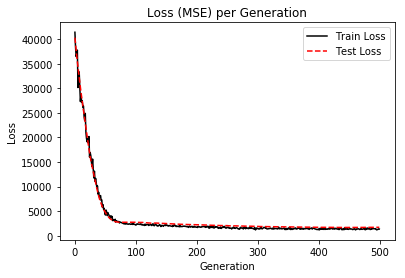
%matplotlib inline # Plot loss (MSE) over time plt.plot(loss_vec, 'k-', label='Train Loss') plt.plot(test_loss, 'r--', label='Test Loss') plt.title('Loss (MSE) per Generation') plt.legend(loc='upper right') plt.xlabel('Generation') plt.ylabel('Loss') plt.show()
Here is how to calculate the model accuracy:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# Model Accuracy actuals = np.array([x[0] for x in birth_data]) test_actuals = actuals[test_indices] train_actuals = actuals[train_indices] test_preds = [x[0] for x in sess.run(final_output, feed_dict={x_data: x_vals_test})] train_preds = [x[0] for x in sess.run(final_output, feed_dict={x_data: x_vals_train})] test_preds = np.array([1.0if x < 2500.0else0.0for x in test_preds]) train_preds = np.array([1.0if x < 2500.0else0.0for x in train_preds]) # Print out accuracies test_acc = np.mean([x == y for x, y in zip(test_preds, test_actuals)]) train_acc = np.mean([x == y for x, y in zip(train_preds, train_actuals)]) print('On predicting the category of low birthweight from regression output (<2500g):') print('Test Accuracy: {}'.format(test_acc)) print('Train Accuracy: {}'.format(train_acc))
On predicting the category of low birthweight from regression output (<2500g):
Test Accuracy: 0.5
Train Accuracy: 0.6225165562913907
Evaluate new points on the model
1 2 3 4 5 6 7 8
# Need new vectors of 'AGE', 'LWT', 'RACE', 'SMOKE', 'PTL', 'HT', 'UI' new_data = np.array([[35, 185, 1., 0., 0., 0., 1.], [18, 160, 0., 1., 0., 0., 1.]]) new_data_scaled = np.nan_to_num(normalize_cols(new_data, train_max, train_min)) new_logits = [x[0] for x in sess.run(final_output, feed_dict={x_data: new_data_scaled})] new_preds = np.array([1.0if x < 2500.0else0.0for x in new_logits])
print('New Data Predictions: {}'.format(new_preds))
# name of data file birth_weight_file = 'birth_weight.csv'
# download data and create data file if file does not exist in current directory ifnot os.path.exists(birth_weight_file): birthdata_url = 'https://github.com/nfmcclure/tensorflow_cookbook/raw/master/01_Introduction/07_Working_with_Data_Sources/birthweight_data/birthweight.dat' birth_file = requests.get(birthdata_url) birth_data = birth_file.text.split('\r\n') birth_header = birth_data[0].split('\t') birth_data = [[float(x) for x in y.split('\t') if len(x)>=1] for y in birth_data[1:] if len(y)>=1] with open(birth_weight_file, "w") as f: writer = csv.writer(f) writer.writerows(birth_data) f.close()
# read birth weight data into memory birth_data = [] with open(birth_weight_file, newline='') as csvfile: csv_reader = csv.reader(csvfile) birth_header = next(csv_reader) for row in csv_reader: birth_data.append(row)
birth_data = [[float(x) for x in row] for row in birth_data] birth_data = [data for data in birth_data if len(data)==9]
# Pull out target variable y_vals = np.array([x[0] for x in birth_data]) # Pull out predictor variables (not id, not target, and not birthweight) x_vals = np.array([x[1:8] for x in birth_data])
# set for reproducible results seed = 99 np.random.seed(seed) tf.set_random_seed(seed)
# Create a logistic layer definition deflogistic(input_layer, multiplication_weight, bias_weight, activation = True): linear_layer = tf.add(tf.matmul(input_layer, multiplication_weight), bias_weight) # We separate the activation at the end because the loss function will # implement the last sigmoid necessary if activation: return(tf.nn.sigmoid(linear_layer)) else: return(linear_layer)
Loss = 0.68008155
Loss = 0.54981357
Loss = 0.54257077
Loss = 0.55420905
Loss = 0.52513915
Loss = 0.5386876
Loss = 0.5331423
Loss = 0.4861947
Loss = 0.58909637
Loss = 0.5264541
Display model performance
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
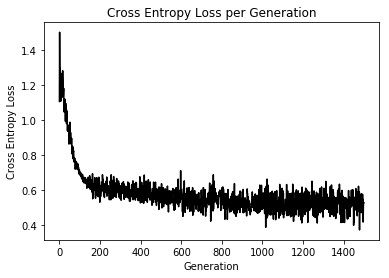
%matplotlib inline # Plot loss over time plt.plot(loss_vec, 'k-') plt.title('Cross Entropy Loss per Generation') plt.xlabel('Generation') plt.ylabel('Cross Entropy Loss') plt.show()
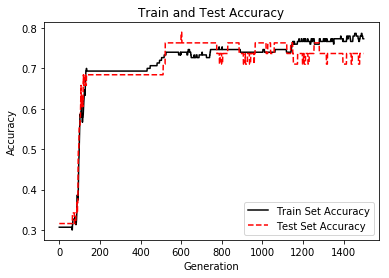
# Plot train and test accuracy plt.plot(train_acc, 'k-', label='Train Set Accuracy') plt.plot(test_acc, 'r--', label='Test Set Accuracy') plt.title('Train and Test Accuracy') plt.xlabel('Generation') plt.ylabel('Accuracy') plt.legend(loc='lower right') plt.show()