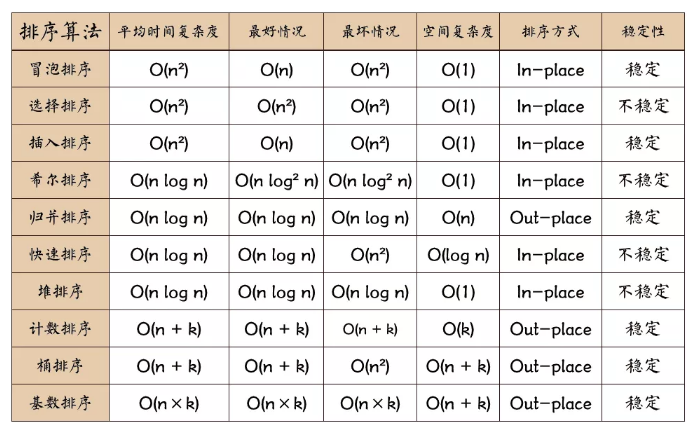
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
| import sys
import random
"""
排序算法 https://baike.baidu.com/item/排序算法/5399605
排序算法,即通过特定的算法因式将一组或多组数据按照既定模式进行重新排序。
这种新序列遵循着一定的规则,体现出一定的规律,因此,经处理后的数据便于筛选和计算,大大提高了计算效率。
对于排序,我们首先要求其具有一定的稳定性,即当两个相同的元素同时出现在某个序列之中,
则经过一定的排序算法之后,两者在排序前后的相对位置不发生变化。
换言之,即便是两个完全相同的元素,它们在排序过程中也是各有区别的,不允许混淆不清。
排序(Sorting) 是计算机程序设计中的一种重要操作,
它的功能是将一个数据元素(或记录)的任意序列,重新排列成一个关键字有序的序列。
排序就是把集合中的元素按照一定的次序排序在一起。
一般来说有升序排列和降序排列2种排序,在算法中有8中基本排序:
(1)冒泡排序;
(2)选择排序;
(3)插入排序;
(4)希尔排序;
(5)归并排序;
(6)快速排序;
(7)基数排序;
(8)堆排序。
"""
def bubble_sort(input_list):
"""
冒泡排序
冒泡排序算法是把较小的元素往前调或者把较大的元素往后调。这种方法主要是通过对相邻两个元素进行大小的比较,
根据比较结果和算法规则对该二元素的位置进行交换,这样逐个依次进行比较和交换,就能达到排序目的。
冒泡排序的基本思想是,首先将第1个和第2个记录的关键字比较大小,如果是逆序的,就将这两个记录进行交换,
再对第2个和第3个记录的关键字进行比较,依次类推,重复进行上述计算,直至完成第(n一1)个和第n个记录的关键字之间的比较,
此后,再按照上述过程进行第2次、第3次排序,直至整个序列有序为止。排序过程中要特别注意的是,
当相邻两个元素大小一致时,这一步操作就不需要交换位置,因此也说明冒泡排序是一种严格的稳定排序算法,
它不改变序列中相同元素之间的相对位置关系。
"""
output_list = input_list.copy()
input_list_len = len(input_list)
for ordered_item_num in range(input_list_len - 1):
flag = True
for idx in range(input_list_len - ordered_item_num - 1):
if output_list[idx] > output_list[idx + 1]:
output_list[idx], output_list[idx + 1] = output_list[idx + 1], output_list[idx]
flag = False
if flag:
break
return output_list
def select_sort(input_list):
"""
选择排序
选择排序算法的基本思路是为每一个位置选择当前最小的元素。
选择排序的基本思想是,基于直接选择排序和堆排序这两种基本的简单排序方法。
首先从第1个位置开始对全部元素进行选择,选出全部元素中最小的给该位置,
再对第2个位置进行选择,在剩余元素中选择最小的给该位置即可;
以此类推,重复进行“最小元素”的选择,直至完成第(n-1)个位置的元素选择,
则第厅个位置就只剩唯一的最大元素,此时不需再进行选择。
使用这种排序时,要注意其中一个不同于冒泡法的细节。
举例说明:序列58539.我们知道第一遍选择第1个元素“5”会和元素“3”交换,
那么原序列中的两个相同元素“5”之间的前后相对顺序就发生了改变。
因此,我们说选择排序不是稳定的排序算法,它在计算过程中会破坏稳定性。
"""
output_list = input_list.copy()
input_list_len = len(input_list)
for ordered_item_num in range(input_list_len - 1):
min_number_idx = ordered_item_num
for idx in range(ordered_item_num + 1, input_list_len):
if output_list[idx] < output_list[min_number_idx]:
min_number_idx = idx
output_list[ordered_item_num], output_list[min_number_idx] = \
output_list[min_number_idx], output_list[ordered_item_num]
return output_list
def insert_sort(input_list):
"""
插入排序
插入排序算法是基于某序列已经有序排列的情况下,通过一次插入一个元素的方式按照原有排序方式增加元素。
这种比较是从该有序序列的最末端开始执行,即要插入序列中的元素最先和有序序列中最大的元素比较,
若其大于该最大元素,则可直接插入最大元素的后面即可,否则再向前一位比较查找直至找到应该插入的位置为止。
插入排序的基本思想是,每次将1个待排序的记录按其关键字大小插入到前面已经排好序的子序列中,寻找最适当的位置,
直至全部记录插入完毕。执行过程中,若遇到和插入元素相等的位置,则将要插人的元素放在该相等元素的后面,
因此插入该元素后并未改变原序列的前后顺序。我们认为插入排序也是一种稳定的排序方法。
插入排序分直接插入排序、折半插入排序和希尔排序3类。 """
output_list = list()
output_list.append(input_list[0])
input_list_len = len(input_list)
for item_idx in range(1, input_list_len):
insert_number_value = input_list[item_idx]
insert_location = len(output_list)
for ordered_number_value in output_list[::-1]:
if insert_number_value < ordered_number_value:
insert_location = insert_location - 1
else:
break
output_list.insert(insert_location, insert_number_value)
return output_list
def shell_sort(input_list):
"""
希尔排序
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
"""
output_list = input_list.copy()
input_list_len = len(input_list)
gap = input_list_len // 2
while gap > 0:
for i in range(gap, input_list_len):
while i >= gap and output_list[i - gap] > output_list[i]:
output_list[i], output_list[i - gap] = output_list[i - gap], output_list[i]
i = i - gap
gap = gap // 2
return output_list
def shell_sort_2(input_list):
"""
希尔排序
"""
output_list = input_list.copy()
input_list_len = len(input_list)
gap = input_list_len // 2
while gap > 0:
for i in range(gap, input_list_len):
for j in range(i, gap - 1, -gap):
if output_list[j] < output_list[j - gap]:
output_list[j], output_list[j - gap] = output_list[j - gap], output_list[j]
else:
break
gap = gap // 2
return output_list
def merge_sort(input_list):
"""
归并排序
归并排序算法就是把序列递归划分成为一个个短序列,
以其中只有1个元素的直接序列或者只有2个元素的序列作为短序列的递归出口,
再将全部有序的短序列按照一定的规则进行排序为长序列。
归并排序融合了分治策略,即将含有n个记录的初始序列中的每个记录均视为长度为1的子序列,
再将这n个子序列两两合并得到n/2个长度为2(当凡为奇数时会出现长度为l的情况)的有序子序列;
将上述步骤重复操作,直至得到1个长度为n的有序长序列。需要注意的是,在进行元素比较和交换时,
若两个元素大小相等则不必刻意交换位置,因此该算法不会破坏序列的稳定性,即归并排序也是稳定的排序算法。
"""
def _merge_operation_of_merge_sort(input_list_A, input_list_B):
output_list = list()
list_A_len = len(input_list_A)
list_B_len = len(input_list_B)
i, j = 0, 0
while i < list_A_len and j < list_B_len:
a = input_list_A[i]
b = input_list_B[j]
if a <= b:
output_list.append(a)
i += 1
else:
output_list.append(b)
j += 1
if i == list_A_len:
output_list.extend(input_list_B[j:])
else:
output_list.extend(input_list_A[i:])
return output_list
input_list_len = len(input_list)
if input_list_len <= 1:
return input_list
middle = input_list_len // 2
left_list = merge_sort(input_list[:middle])
right_list = merge_sort(input_list[middle:])
return _merge_operation_of_merge_sort(left_list, right_list)
def quick_sort(input_list):
"""
快速排序
从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
https://www.jianshu.com/p/2b2f1f79984e
"""
def _partition(input_list, left, right):
"""
返回基准pivot值的位置,并且满足input_list[left, right]这段区间内,
大于基准值的数值都在基准值的右侧,小于基准值的数值都在基准值左侧。
:param input_list: 待处理的列表
:param left: 列表起始位置left
:param right: 列表结束位置right
:return: 基准pivot值的位置
1. 最初left所指位置的值被选做基准pivot
当 left < right 时(说明[left, right]区间的值还未处理)执行:
2. 然后left所指位置被当做交换区,right所指位置被当做判断区。
当满足要求(left < right 且 right所指的值大于基准pivot)时,一直执行right所指位置向左推进一位。
当不满足要求时则将right所指位置的值移动到left所指交换区。
3. 然后right所指位置被当做交换区,left所指位置被当做判断区。
当满足要求(left < right 且 left所指的值小于基准pivot)时,一直执行left所指位置向右推进一位。
当不满足要求时则将left所指位置的值移动到right所指的交换区。
当 left == right时(说明只剩下left所指位置没有处理):
此时已经满足left所指位置的左侧值小于基准pivot,left所指位置的右侧值大于基准pivot。
直接将基准值放入left所指位置即可。
4. 返回基准值所在的位置 left
"""
pivot_value = input_list[left]
while left < right:
while left < right and input_list[right] >= pivot_value:
right -= 1
input_list[left] = input_list[right]
while left < right and input_list[left] < pivot_value:
left += 1
input_list[right] = input_list[left]
input_list[left] = pivot_value
return left
def _quick_sort(input_list, left, right):
if left < right:
pivot = _partition(input_list, left, right)
_quick_sort(input_list, left, pivot - 1)
_quick_sort(input_list, pivot + 1, right)
return input_list
input_list_len = len(input_list)
return _quick_sort(input_list, 0, input_list_len - 1)
def quick_sort_2(input_list):
"""
快速排序
快速排序的基本思想是:通过一趟排序算法把所需要排序的序列的元素分割成两大块,
其中,一部分的元素都要小于或等于另外一部分的序列元素,
然后仍根据该种方法对划分后的这两块序列的元素分别再次实行快速排序算法,
排序实现的整个过程可以是递归的来进行调用,最终能够实现将所需排序的无序序列元素变为一个有序的序列。
"""
length = len(input_list)
if length <= 1:
return input_list
else:
pivot = input_list.pop()
greater, lesser = [], []
for element in input_list:
if element > pivot:
greater.append(element)
else:
lesser.append(element)
return quick_sort_2(lesser) + [pivot] + quick_sort_2(greater)
def heap_sort(input_list):
"""
堆排序
https://www.cnblogs.com/cj723/archive/2011/04/22/2024269.html
https://www.jianshu.com/p/d174f1862601
"""
def _heap_adjust(array, start, end):
"""
调整列表array满足堆性质
:param array: 待调整为满足堆性质的列表
:param start: 要调整的堆的根节点位置
:param end: 列表要处理数值的最大位置
:return: 调整为满足堆性质的列表
1. 取出根节点的位置start对应的数值temp,计算出该根节点的左孩子位置child
当 child <= end(孩子位置没有超过列表要处理数值的最大位置时):
2. 如果有两个孩子(child <= end) 且左孩子的值小于右孩子的值(array[child] < array[child + 1])
,那么把孩子位置移动到右孩子位置;
3. 如果根节点temp值大于等于它所有孩子的值,则退出循环;
4. 将根节点的值调整为最大孩子的值 array[start] = array[child]
根节点位置调整为原来最大孩子的位置 start = child
更新该新的根节点对应的左孩子的位置 child = start * 2
5. 确定出temp最终所处的位置start,然后赋值array[start] = temp
"""
temp = array[start]
child = start * 2
while child <= end:
if child < end and array[child] < array[child + 1]:
child += 1
if temp >= array[child]:
break
array[start] = array[child]
start = child
child = start * 2
array[start] = temp
output_list = [0] + list(input_list)
input_list_len = len(input_list)
for start in range(input_list_len // 2, 0, -1):
_heap_adjust(output_list, start, input_list_len)
for end in range(input_list_len, 1, -1):
output_list[1], output_list[end] = output_list[end], output_list[1]
_heap_adjust(output_list, 1, end - 1)
del output_list[0]
return output_list
def count_sort(input_list):
"""
计数排序
什么时候不用计数排序?
当数组最大最小值差距过大时,并不适用计数排序
当数组元素不是整数,并不适用计数排序
所以当数组最大最小值差远小于数组长度时,使用计数排序更快,比如年龄。
"""
if not isinstance(input_list[0], int):
raise ValueError("This count_sort code only handles integers!")
max, min = input_list[0], input_list[0]
for i in input_list:
if i > max: max = i
if i < min: min = i
nums = [0 for _ in range(max - min + 1)]
for i in input_list:
nums[i - min] += 1
output_list = []
for i in range(len(nums)):
output_list += [min + i] * nums[i]
return output_list
def bucket_sort(input_list, bucket_size=5):
"""
桶排序
https://github.com/TheAlgorithms/Python/blob/master/sorts/bucket_sort.py
"""
min_value, max_value = (min(input_list), max(input_list))
bucket_count = ((max_value - min_value) // bucket_size + 1)
buckets = [[] for _ in range(int(bucket_count))]
for i in range(len(input_list)):
buckets[int((input_list[i] - min_value) // bucket_size)
].append(input_list[i])
return sorted([buckets[i][j] for i in range(len(buckets))
for j in range(len(buckets[i]))])
def bucket_sort_2(input_list, bucket_size=5):
"""
桶排序
https://blog.csdn.net/sty945/article/details/81530774
设置固定数量的空桶。
把数据放到对应的桶中。
对每个不为空的桶中数据进行排序。
拼接不为空的桶中数据,得到结果。
"""
min_value, max_value = (min(input_list), max(input_list))
bucket_count = int(((max_value - min_value) // bucket_size + 1))
buckets = [[] for _ in range(bucket_count)]
for item in input_list:
item_buckets_idx = int((item - min_value) // bucket_size)
buckets[item_buckets_idx].append(item)
for i in range(bucket_count):
buckets[i].sort()
output_list = [item for bucket in buckets for item in bucket]
return output_list
def radix_sort(input_list):
"""
基数排序
这个代码仅仅能处理整数
https://github.com/TheAlgorithms/Python/blob/master/sorts/radix_sort.py
"""
if not isinstance(input_list[0], int):
raise ValueError("This radix sorting code only handles integers!")
RADIX = 10
placement = 1
min_int_digit = int(min(input_list)) - 1
normal_lst = [item - min_int_digit for item in input_list]
max_digit = max(normal_lst)
print(normal_lst)
while placement < max_digit:
buckets = [list() for _ in range(RADIX)]
for item in normal_lst:
tmp = int((item / placement) % RADIX)
buckets[tmp].append(item)
a = 0
for b in range(RADIX):
buck = buckets[b]
for i in buck:
normal_lst[a] = i
a += 1
print(normal_lst)
placement *= RADIX
output_list = [item + min_int_digit for item in normal_lst]
return output_list
def produce_random_int_list(number=1000, start=-100, stop=1000):
input_list = [random.randint(start, stop) for _ in range(number)]
return input_list
def produce_random_float_list(number=1000, start=-100.0, stop=1000.0):
input_list = [random.uniform(start, stop) for _ in range(number)]
return input_list
def fack_sort(input_list):
return input_list
def check_sort_function(sort_function, number=1000):
for i in range(100):
if i % 2 == 0:
input_list = produce_random_int_list(number)
else:
input_list = produce_random_float_list(number)
stand_sort_out = sorted(input_list)
custom_sort_medthod_out = sort_function(input_list)
for a, b in zip(custom_sort_medthod_out, stand_sort_out):
if a != b:
print(f"stand {a} != custom {b}")
print("stand_sort_out:\t", stand_sort_out)
print("custom_sort_medthod_out:\t", custom_sort_medthod_out)
raise ValueError("sort_function error!")
return True
def check_sort_process(sort_function):
input_list = produce_random_int_list(number=5, start=-100, stop=1000)
print("---input_list---", input_list)
output_list = sort_function(input_list)
print("---output_list---", output_list)
print()
if __name__ == "__main__":
sort_function_list = [bubble_sort, select_sort, insert_sort,
shell_sort, shell_sort_2, merge_sort,
quick_sort, quick_sort_2, heap_sort,
bubble_sort, bucket_sort_2]
sort_int_fuction_list = [count_sort, radix_sort]
sort_function_index = None
if len(sys.argv) == 2:
sort_function_index = int(sys.argv[1])
if sort_function_index is None:
for sort_f in sort_function_list:
print(f"check {str(sort_f)}...")
check_sort_function(sort_f, 1000)
else:
check_sort_process(sort_function_list[sort_function_index])
|