异常检测
异常检测(Anomaly detection) 的假设是入侵者活动异常于正常主体的活动。根据这一理念建立主体正常活动的“活动简档”,将当前主体的活动状况与“活动简档”相比较,当违反其统计规律时,认为该活动可能是“入侵”行为。异常检测的难题在于如何建立“活动简档”以及如何设计统计算法,从而不把正常的操作作为“入侵”或忽略真正的“入侵”行为。
异常检测(Anomaly-based detection)方法首先定义一组系统处于“正常”情况时的数据,如CPU利用率、内存利用率、文件校验和等然后进行分析确定是否出现异常。
开发和评价一个异常检测系统
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量y的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
例如:我们有10000台正常引擎的数据,有20台异常引擎的数据。我们这样分配数据:
- 6000台正常引擎的数据作为训练集
- 2000台正常引擎和10台异常引擎的数据作为交叉检验集
- 2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建P(x)函数
- 对交叉检验集,我们尝试使用不同的ε值作为阀值,并预测数据是否异常,根据F1值或者查准率与查全率的比例来选择ε
- 选出ε后,针对测试集进行预测,计算异常检验系统的F1值,或者查准率与查全率之比
异常检测与监督学习对比
之前我们构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面的对比有助于选择采用监督学习还是异常检测:
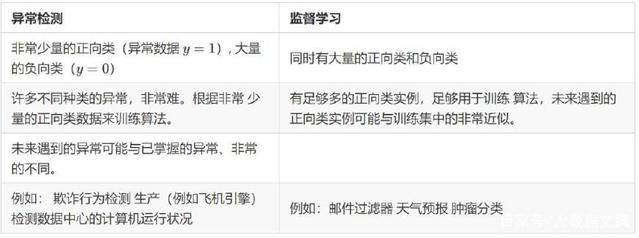
对于很多技术公司可能会遇到的一些问题,通常来说,正样本的数量很少,甚至有时候是0,也就是说,出现了太多没见过的不同的异常类型,那么对于这些问题,通常应该使用的算法就是异常检测算法。
异常检查与不平衡分类的关系
一般情况下,可以把异常检测看成是数据不平衡下的分类问题。因此,如果数据条件允许,优先使用有监督的异常检测。实验结果发现直接用XGBOOST进行有监督异常检测往往也能得到不错的结果,没有思路时不妨一试。而在仅有少量标签的情况下,也可采用半监督异常检测模型。比如把无监督学习作为一种特征抽取方式来辅助监督学习,和stacking比较类似。这种方法也可以理解成通过无监督的特征工程对数据进行预处理后,喂给有监督的分类模型。但在现实情况中,异常检测问题往往是没有标签的,训练数据中并未标出哪些是异常点,因此必须使用无监督学习。
异常检测的应用场景
- 数据预处理
- 病毒木马检测
- 工业制造产品检测
- 网络流量检测
由于在以上场景中,异常的数据量都是很少的一部分,因此诸如:SVM、逻辑回归等分类算法,都不适用,因为:监督学习算法适用于有大量的正向样本,也有大量的负向样本,有足够的样本让算法去学习其特征,且未来新出现的样本与训练样本分布一致。
异常检测的相关算法
异常值检测的常见四种方法,分别为 Numeric Outlier、Z-Score、DBSCAN以及Isolation Forest
异常检查相关软件
pyod A Python Toolbox for Scalable Outlier Detection (Anomaly Detection)

