对于计算机是如何字符的理解难度主要来源于不同文献对字符编码概念的混淆,本文就是为了厘清字符相关概念,解决困扰程序员的字符编码、解码和乱码问题。
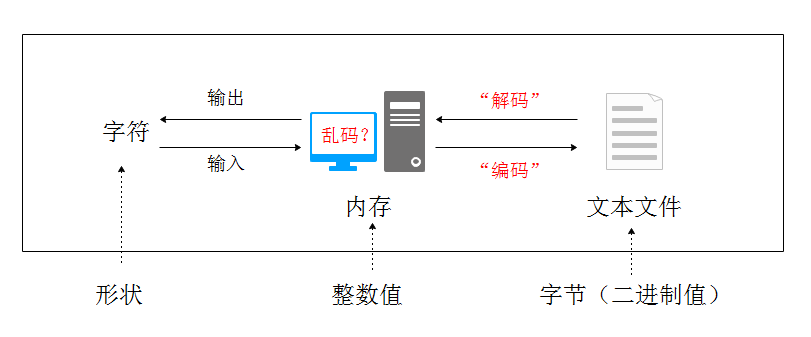
上图展示计算机中字符和字节的转换过程,字符在计算中有字符对应的形状、字符对应的整数值和字符对应的字节形式三种表示方法。本文讲述计算机是如何处理字符的问题,即字符这三种表示的转换过程,特别是字符的编码问题。
基本概念
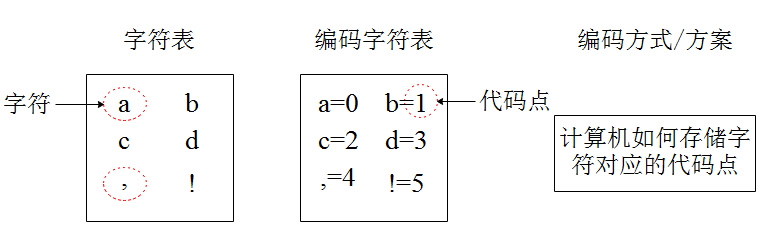
字符、字符表、和编码字符表以及代码点的概念如下:
- 字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
- 字符表(character repertoire),也称为字符集、字符库和字符列表等等,是由一个或多个确定的字符所构成的整体,即字符的集合。
- 【编码】字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。其实准确的应该称这些字符集为编码字符集(coded character set),因为这些字符集给其包含的每一个字符都对应了唯一确定的一个整数值,这个整数值称为代码点(code point)。
这些概念示意图如下所示:
到此你可能产生疑问,如果有了编码字符表,那么每个字符都有对应的代码点(整数值),那么计算机直接把这个代码点存起来不就行了(整数如何在计算机中存储不是本文讨论的话题),为什么还要讨论字符编码问题。原因如下:
- 历史遗留问题。伴随着计算机的发展不同的编码字符集相继被推出,同时期不同的国家往往产生了互不兼容的编码字符表,比如对同一个字符不同的编码字符表的代码点不一样,那么根据这些不兼容编码字符表存储的文件信息不能交互;不同时期的编码字符表虽然会考虑兼容性问题,甚至如今有了统一全世界所有字符的编码字符表Unicode,但实际使用过程中会发现每个国家真正用的上的字符相对整个编码字符表来说比例非常低,所以至今仍然有许多编码字符表在广泛的使用中,我们需要考虑不同编码表的转换问题。
- 如何存储代码点问题。如今全球统一的编码字符表Unicode用数字 0x0~0x10FFFF(这是整数的十六进制表示) 表示所有字符,所以最多可以容纳1114112个字符。即使有了全球统一的编码字符表,也要考虑用多少字节来存储每一个字符对应的代码点,比如为了让存储的效率更高(显然让常用字符对应的代码点小,这样用少量的字节就能存储该字符,参见哈夫曼编码),当然还有其它的编码方式,所以目前编码字符表Unicode中的字符对应的代码点有UTF-8,UTF-16和UTF-32三种不同的存储代码点的方法。
字符编码
对于字符编码理解的难度主要来源于不同文献对字符编码概念的混淆。
首先来看百度百科对字符编码的定义:
字符编码(Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和ASCII。其中,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以1个字节的方式存储。
根据以上字符编码的定义,就可以认为编码字符集已经对字符进行了编码(广义的编码,从编码字符表的名字也可以看出),因为每一个字符都被编码字符表编码为了唯一的整数值——代码点。而实际上我们需要解决的问题是,代码点如何转换成字节的编码问题,所以提出一个新的概念——字符编码方式(character encoding form)也称为字符编码方案(Character encoding schema),它是指将字符对应代码点转换成字节的方式或方案。很多文献将字符编码方式(character encoding form)或字符编码方案(Character encoding schema)简称为“编码”,这里的“编码”是狭义的编码。
注意:有的文献中字符集概念是指编码字符集概念,有的文件中编码字符集概念包含了字符编码方式的概念,需要根据上下文来理解,也正是这些概念的相互指代,以及混乱的简称,提高了程序员的理解难度!
计算机处理字符的原理
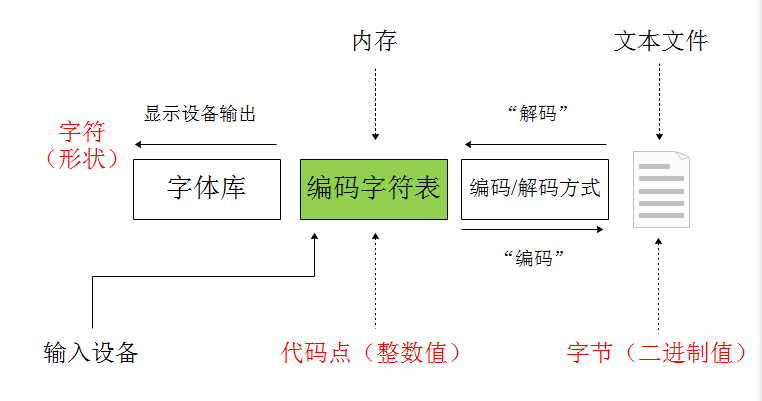
上图展示了计算机处理字符的基本原理:
- 通过输入设备比如键盘可以将字符输入到电脑的内存中,比如输入字符C,那么通过编码字符表其实在内存中存的就是该字符对应的代码点;
- 内存中的字符可以通过编码字符表转换成对应的字符,然后再根据字体库输出格式化的字符(比如调整字符的大小和颜色等);
- 一般本文献中所谓的字符的编码和解码其实就是指内存中的代码点与文本文件交互时的两个过程,可以按照某种编码方式把代码点编码成对应的字节也可以反过来把字节解码成对应的代码点。如果字符解码和编码的方式不兼容,那么就可能会出现乱码问题。
注意:
- 编码字符表的每种编码方式的具体实现都有其对应的解码方式,只要使用了兼容(放宽了要求,不一定要一一对应,因为有些编码字符表是兼容的)的编码和解码方式就可以保证代码点和字节的转换是正确的。
- 在不知道文件的编码方式的情况下可以通过一些字符编码检测器(比如chardet)来检测文件的文件的编码方式,进而使用其对应的解码方式正确来解码文件。
常见字符集与编码方式
常见字符集:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。Utf-8、Utf-16等Unicode字符集的编码方式。
针对不同编程语言的字符编码问题
对于代码源文件本身也要考虑字符编码问题,比如Python可以选择Unicode字符存储为UCS-2还是UCS-4。
- Java: Java字符的编码解码与乱码问题
- C++: C++ 编码、字符和字符串
- Python: Python字符串和编码

