AUC基础
AUC定义
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
AUC常用的定义:随机从正样本和负样本中各选一个,分类器对于该正样本打分大于该负样本打分的概率。
从AUC 判断分类器(预测模型)优劣的标准:
AUC = 1,是完美分类器。
AUC = [0.85, 0.95], 效果很好
AUC = [0.7, 0.85], 效果一般
AUC = [0.5, 0.7],效果较低,但用于预测股票已经很不错了
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测
AUC的计算

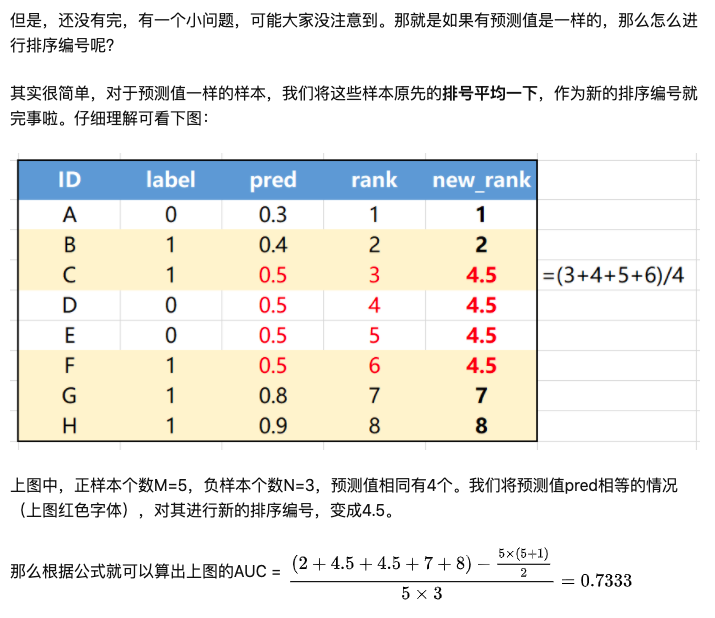
label = [0, 1, 1, 0, 0, 1, 1, 1]
pred = [0.3, 0.4, 0.5, 0.5, 0.5, 0.5, 0.8, 0.9]
1 | # -*- coding: utf-8 -*- |
AUC问题拓展
如果单机内存无法装下计算AUC所需的数据,请问如何解决?
知道问题答案的可以与我交流,哈哈哈。
AUC的优点:“稳定性”
AUC为啥对正负样本比例不敏感?
AUC表示ROC曲线下方面积,而ROC横轴FPR只关注负样本,与正样本无关;纵轴TPR只关注正样本,与负样本无关。所以横纵轴都不受正负样本比例影响,积分当然也不受其影响。
AUC对均匀正负样本采样不敏感
正由于AUC对分值本身不敏感,故常见的正负样本采样,并不会导致auc的变化。比如在点击率预估中,处于计算资源的考虑,有时候会对负样本做负采样,但由于采样完后并不影响正负样本的顺序分布。
即假设采样是随机的,采样完成后,给定一条正样本,模型预测为score1,由于采样随机,则大于score1的负样本和小于score1的负样本的比例不会发生变化。
但如果采样不是均匀的,比如采用word2vec的negative sample,其负样本更偏向于从热门样本中采样,则会发现auc值发生剧烈变化。
AUC与准确率的关系
在机器学习中AUC和accuracy有什么内在关系?
AUC衡量的是一个模型的好坏,是它给所有sample排序的合理程度(是不是正确地把负例排在了正例的前面);而accuracy衡量的是一个模型在一个特定threshold(比如,logistic regression模型在阈值1/2)下的预测准确度(是不是正确地把负例排在了阈值之前,正例排在了阈值之后)。
模型大最大值AUC
来自:多高的AUC才算高?
结论:
- Max AUC的高低只和特征取值的多样性有关。
- 贝叶斯错误率与Max AUC有着密切的关系。由于这两个指标衡量的都是数据集中不可约错误(irreducible error),所以他们在数值上表现出了很强的相关性。
- 更高的Max AUC并不代表更高的真实模型AUC。虽然更高的Max AUC代表了更多的特征取值可能性,但是影响真实AUC的,还有特征的具体区分度,也就是泛化能力。
启发:
假设我们拥有一个无比强大的模型,可以准确预测每一条样本的概率,那么该模型的AUC是否为1呢?现实常常很残酷,样本数据中本身就会存在大量的歧义样本,即特征集合完全一致,但label却不同。因此就算拥有如此强大的模型,也不能让AUC为1.
因此,当我们拿到样本数据时,第一步应该看看有多少样本是特征重复,但label不同,这部分的比率越大,代表其“必须犯的错误”越多。学术上称它们为Bayes Error Rate,也可以从不可优化的角度去理解。
我们花了大量精力做的特征工程,很大程度上在缓解这个问题。当增加一个特征时,观察下时候减少样本中的BER,可作为特征构建的一个参考指标。
AUC与模型
AUC提升没有带来线上效果提升原因
在推荐系统实践中,我们往往会遇到一个问题:线下AUC提升并不能带来线上效果提升,这个问题在推荐系统迭代的后期往往会更加普遍。
在排除了低级失误bug以后,造成这个问题可能有下面几点原因:
样本
- 线下评测基于历史出现样本,而线上测试存在新样本。因此线下AUC提升可能只是在历史出现样本上有提升,但是对于线上新样本可能并没有效果。
- 历史数据本身由老模型产生,本身也是存在偏置的。
- 线上和线下特征不一致。例如包含时间相关特征,存在特征穿越。或者线上部分特征缺失等等。
评估目标
- AUC计算的时候,不仅会涉及同一个用户的不同item,也会涉及不同用户的不同item,而线上排序系统每次排序只针对同一个用户的不同item进行打分。
- 线上效果只跟相关性有关,是和position等偏置因素无关的。而线下一般是不同position的样本混合训练,因此线上和线下评估不对等。
分布变化
DNN模型相比传统模型,一般得分分布会更平滑,和传统模型相比打分布不一致。而线上有些出价策略依赖了打分分布,例如有一些相关阈值,那么就可能产生影响。这个可以绘制CTR概率分布图来检查。
那么如何解决呢?可以考虑下面的办法:
- 使用无偏样本作为测试集。随机样本最好,不行的话,最好不要是基于老模型产生的线上样本。
- 使用gauc等指标,同时从测试集中去除无点击的用户。gauc基于session进行分组。例如对于搜索业务,把一次搜索query对应的一次用户的曝光点击行为作为一个session进行计算。
相关论文
An introduction to ROC analysis

