线性回归
Linear Regression (function) https://en.wikipedia.org/wiki/Linear_regression
在现实世界中,存在着大量这样的情况:两个变量例如X和Y有一些依赖关系。由X可以部分地决定Y的值,但这种决定往往不很确切。常常用来说明这种依赖关系的最简单、直观的例子是体重与身高,用Y表示他的体重。众所周知,一般说来,当X大时,Y也倾向于大,但由X不能严格地决定Y。又如,城市生活用电量Y与气温X有很大的关系。在夏天气温很高或冬天气温很低时,由于室内空调、冰箱等家用电器的使用,可能用电就高,相反,在春秋季节气温不高也不低,用电量就可能少。但我们不能由气温X准确地决定用电量Y。类似的例子还很多,变量之间的这种关系称为“相关关系”,回归模型就是研究相关关系的一个有力工具。
Linear Regression
Here we show how to implement various linear regression techniques in TensorFlow. The first two sections show how to do standard matrix linear regression solving in TensorFlow. The remaining six sections depict how to implement various types of regression using computational graphs in TensorFlow.
1. Linear Regression: Inverse Matrix Method
Using the Matrix Inverse Method
Here we implement solving 2D linear regression via the matrix inverse method in TensorFlow.
Model
Given A * x = b, we can solve for x via:
(t(A) A) x = t(A) * b
x = (t(A) A)^(-1) t(A) * b
Here, note that t(A) is the transpose of A.
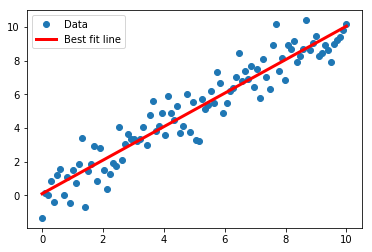
This script explores how to accomplish linear regression with TensorFlow using the matrix inverse.
Given the system $ A \cdot x = y $, the matrix inverse way of linear regression (equations for overdetermined systems) is given by solving for x as follows.
As a reminder, here, $x$ is our parameter matrix (vector of length $F+1$, where $F$ is the number of features). Here, $A$, our design matrix takes the form
Where $F$ is the number of independent features, and $n$ is the number of points. For an overdetermined system, $n>F$. Remember that one observed point in our system will have length $F+1$ and the $i^{th}$ point will look like
For this recipe, we will consider only a 2-dimensional system ($F=1$), so that we can plot the results at the end.
We start by loading the necessary libraries.
1 | import matplotlib.pyplot as plt |
Next we start a graph session.
1 | sess = tf.Session() |
For illustration purposes, we randomly generate data to fit.
The x-values will be a sequence of 100 evenly spaced values between 0 and 100.
The y-values will fit to the line: $y=x$, but we will add normally distributed error according to $N(0,1)$.
1 | # Create the data |
We create the design matrix, $A$, which will be a column of ones and the x-values.
1 | # Create design matrix |
We now create the y-values as a matrix with Numpy.
After we have the y-values and the design matrix, we create tensors from them.
1 | # Format the y matrix |
Now we solve for the parameter matrix with TensorFlow operations.
1 | # Matrix inverse solution |
Run the solutions and extract the slope and intercept from the parameter matrix.
1 | solution_eval = sess.run(solution) |
Now we print the solution we found and create a best fit line.
1 | print('slope: ' + str(slope)) |
slope: 0.9953458430212332
y_intercept: 0.0956584431188145
We use Matplotlib to plot the results.
1 | # Plot the results |
2. Linear Regression: Using a Decomposition (Cholesky Method)
Using the Cholesky Decomposition Method
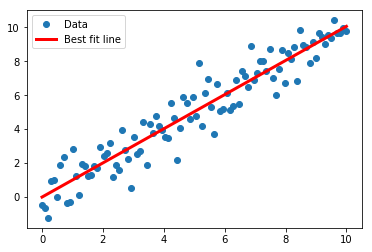
Here we implement solving 2D linear regression via the Cholesky decomposition in TensorFlow.
Model
Given A x = b, and a Cholesky decomposition such that A = LL’ then we can get solve for x via
- Solving L y = t(A) b for y
- Solving L’ * x = y for x.
This script will use TensorFlow’s function, tf.cholesky() to decompose our design matrix and solve for the parameter matrix from linear regression.
For linear regression we are given the system $A \cdot x = y$. Here, $A$ is our design matrix, $x$ is our parameter matrix (of interest), and $y$ is our target matrix (dependent values).
For a Cholesky decomposition to work we assume that $A$ can be broken up into a product of a lower triangular matrix, $L$ and the transpose of the same matrix, $L^{T}$.
Note that this is when $A$ is square. Of course, with an over determined system, $A$ is not square. So we factor the product $A^{T} \cdot A$ instead. We then assume:
For more information on the Cholesky decomposition and it’s uses, see the following wikipedia link: The Cholesky Decomposition
Given that $A$ has a unique Cholesky decomposition, we can write our linear regression system as the following:
Then we break apart the system as follows:
and
The steps we will take to solve for $x$ are the following
Compute the Cholesky decomposition of $A$, where $A^{T} \cdot A = L^{T} \cdot L$.
Solve ($L^{T} \cdot z = A^{T} \cdot y$) for $z$.
Finally, solve ($L \cdot x = z$) for $x$.
We start by loading the necessary libraries.
1 | import matplotlib.pyplot as plt |
Next we create a graph session
1 | sess = tf.Session() |
We use the same method of generating data as in the prior recipe for consistency.
1 | # Create the data |
We generate the design matrix, $A$.
1 | # Create design matrix |
Next, we generate the
1 | # Create y matrix |
Now we calculate the square of the matrix $A$ and the Cholesky decomposition.
1 | # Find Cholesky Decomposition |
We solve the first equation. (see step 2 in the intro paragraph above)
1 | # Solve L*y=t(A)*b |
We finally solve for the parameter matrix by solving the second equation (see step 3 in the intro paragraph).
1 | # Solve L' * y = sol1 |
Extract the coefficients and create the best fit line.
1 | # Extract coefficients |
slope: 1.006032728766641
y_intercept: -0.0033007871888138603
Finally, we plot the fit with Matplotlib.
1 | # Plot the results |
3. Linear Regression: The TensorFlow Way
Learning the TensorFlow Way of Regression
In this section we will implement linear regression as an iterative computational graph in TensorFlow. To make this more pertinent, instead of using generated data, we will instead use the Iris data set. Our x will be the Petal Width, our y will be the Sepal Length. Viewing the data in these two dimensions suggests a linear relationship.
Model
The the output of our model is a 2D linear regression:
y = A * x + b
The x matrix input will be a 2D matrix, where it’s dimensions will be (batch size x 1). The y target output will have the same dimensions, (batch size x 1).
The loss function we will use will be the mean of the batch L2 Loss:
loss = mean( (y_target - model_output)^2 )
We will then iterate through random batch size selections of the data.
For this script, we introduce how to perform linear regression in the context of TensorFlow.
We will solve the linear equation system:
With the Sepal length (y) and Petal width (x) of the Iris data.
Performing linear regression in TensorFlow is a lot easier than trying to understand Linear Algebra or Matrix decompositions for the prior two recipes. We will do the following:
- Create the linear regression computational graph output. This means we will accept an input, $x$, and generate the output, $Ax + b$.
- We create a loss function, the L2 loss, and use that output with the learning rate to compute the gradients of the model variables, $A$ and $b$ to minimize the loss.
The benefit of using TensorFlow in this way is that the model can be routinely updated and tweaked with new data incrementally with any reasonable batch size of data. The more iterative we make our machine learning algorithms, the better.
We start by loading the necessary libraries.
1 | import matplotlib.pyplot as plt |
We create a graph session.
1 | sess = tf.Session() |
Next we load the Iris data from the Scikit-Learn library.
1 | # Load the data |
With most TensorFlow algorithms, we will need to declare a batch size for the placeholders and operations in the graph. Here, we set it to 25. We can set it to any integer between 1 and the size of the dataset.
For the effect of batch size on the training, see Chapter 2: Batch vs Stochastic Training
1 | # Declare batch size |
We now initialize the placeholders and variables in the model.
1 | # Initialize placeholders |
We add the model operations (linear model output) and the L2 loss.
1 | # Declare model operations |
We have to tell TensorFlow how to optimize and back propagate the gradients. We do this with the standard Gradient Descent operator (tf.train.GradientDescentOptimizer), with the learning rate argument of $0.05$.
Then we initialize all the model variables.
1 | # Declare optimizer |
We start our training loop and run the optimizer for 100 iterations.
1 | # Training loop |
Step #25 A = [[1.5073389]] b = [[3.7461321]]
Loss = 0.53326994
Step #50 A = [[1.2745976]] b = [[4.1358175]]
Loss = 0.42734933
Step #75 A = [[1.1166353]] b = [[4.4049253]]
Loss = 0.29555324
Step #100 A = [[1.0541962]] b = [[4.5658007]]
Loss = 0.23579143
We pull out the optimal coefficients and get the best fit line.
1 | # Get the optimal coefficients |
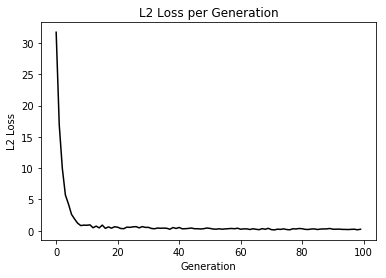
Plot the results with Matplotlib. Along with the linear fit, we will also plot the L2 loss over the model training iterations.
1 | # Plot the result |
4. Deming Regression
Model
The model will be the same as regular linear regression:
y = A * x + b
Instead of measuring the vertical L2 distance, we will measure the shortest distance between the line and the predicted point in the loss function.
loss = |y_target - (A * x_input + b)| / sqrt(A^2 + 1)
This function shows how to use TensorFlow to solve linear Deming regression.
$y = Ax + b$
We will use the iris data, specifically:
y = Sepal Length and x = Petal Width.
Deming regression is also called total least squares, in which we minimize the shortest distance from the predicted line and the actual (x,y) points.
If least squares linear regression minimizes the vertical distance to the line, Deming regression minimizes the total distance to the line. This type of regression minimizes the error in the y values and the x values. See the below figure for a comparison.

To implement this in TensorFlow, we start by loading the necessary libraries.
1 | import matplotlib.pyplot as plt |
Start a computational graph session:
1 | sess = tf.Session() |
We load the iris data.
1 | # Load the data |
Next we declare the batch size, model placeholders, model variables, and model operations.
1 | # Declare batch size |
For the demming loss, we want to compute:
Which will give us the shortest distance between a point (x,y) and the predicted line, $A \cdot x + b$.
1 | # Declare Deming loss function |
Next we declare the optimization function and initialize all model variables.
1 | # Declare optimizer |
Now we train our Deming regression for 250 iterations.
1 | # Training loop |
Step #100 A = [[3.0731559]] b = [[1.7809086]]
Loss = 0.47353575
Step #200 A = [[2.4822469]] b = [[2.522591]]
Loss = 0.41145653
Step #300 A = [[1.7613103]] b = [[3.6220071]]
Loss = 0.37061805
Step #400 A = [[1.0064616]] b = [[4.5484953]]
Loss = 0.26182547
Step #500 A = [[0.9593529]] b = [[4.610097]]
Loss = 0.2435131
Step #600 A = [[0.9646577]] b = [[4.624607]]
Loss = 0.26413646
Step #700 A = [[1.0198785]] b = [[4.6017494]]
Loss = 0.2845798
Step #800 A = [[0.99521935]] b = [[4.6001368]]
Loss = 0.27551532
Step #900 A = [[1.0415721]] b = [[4.6130023]]
Loss = 0.2898117
Step #1000 A = [[1.0065476]] b = [[4.6437864]]
Loss = 0.2525265
Step #1100 A = [[1.0090839]] b = [[4.6393313]]
Loss = 0.27818772
Step #1200 A = [[0.9649767]] b = [[4.581815]]
Loss = 0.25168285
Step #1300 A = [[1.006261]] b = [[4.5881867]]
Loss = 0.25499973
Step #1400 A = [[1.0311592]] b = [[4.618432]]
Loss = 0.2563808
Step #1500 A = [[0.9623312]] b = [[4.5966215]]
Loss = 0.2465789
Retrieve the optimal coefficients (slope and intercept).
1 | # Get the optimal coefficients |
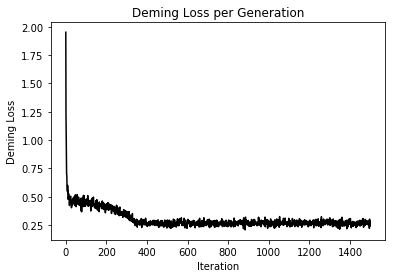
Here is matplotlib code to plot the best fit Deming regression line and the Demming Loss.
1 | # Plot the result |
5. LASSO and Ridge Regression
This function shows how to use TensorFlow to solve lasso or ridge regression for $\boldsymbol{y} = \boldsymbol{Ax} + \boldsymbol{b}$
We will use the iris data, specifically: $\boldsymbol{y}$ = Sepal Length, $\boldsymbol{x}$ = Petal Width
1 | # import required libraries |
1 | # Specify 'Ridge' or 'LASSO' |
1 | # clear out old graph |
Load iris data
1 | # iris.data = [(Sepal Length, Sepal Width, Petal Length, Petal Width)] |
Model Parameters
1 | # Declare batch size |
Loss Functions
1 | # Select appropriate loss function based on regression type |
Optimizer
1 | # Declare optimizer |
Run regression
1 | # Initialize variables |
Step #300 A = [[0.7717163]] b = [[1.8247688]]
Loss = [[10.26617]]
Step #600 A = [[0.75910366]] b = [[3.2217226]]
Loss = [[3.059304]]
Step #900 A = [[0.74844867]] b = [[3.9971633]]
Loss = [[1.2329929]]
Step #1200 A = [[0.73754]] b = [[4.429276]]
Loss = [[0.57923675]]
Step #1500 A = [[0.72945035]] b = [[4.672014]]
Loss = [[0.40877518]]
Extract regression results
1 | # Get the optimal coefficients |
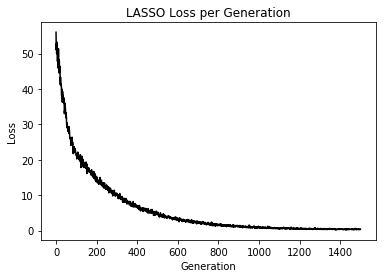
Plot results
1 | %matplotlib inline |
6. Elastic Net Regression
This function shows how to use TensorFlow to solve elastic net regression.
$y = Ax + b$
Setup model1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31# make results reproducible
seed = 13
np.random.seed(seed)
tf.set_random_seed(seed)
# Declare batch size
batch_size = 50
# Initialize placeholders
x_data = tf.placeholder(shape=[None, 3], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
# Create variables for linear regression
A = tf.Variable(tf.random_normal(shape=[3,1]))
b = tf.Variable(tf.random_normal(shape=[1,1]))
# Declare model operations
model_output = tf.add(tf.matmul(x_data, A), b)
# Declare the elastic net loss function
elastic_param1 = tf.constant(1.)
elastic_param2 = tf.constant(1.)
l1_a_loss = tf.reduce_mean(tf.abs(A))
l2_a_loss = tf.reduce_mean(tf.square(A))
e1_term = tf.multiply(elastic_param1, l1_a_loss)
e2_term = tf.multiply(elastic_param2, l2_a_loss)
loss = tf.expand_dims(tf.add(tf.add(tf.reduce_mean(tf.square(y_target - model_output)), e1_term), e2_term), 0)
# Declare optimizer
my_opt = tf.train.GradientDescentOptimizer(0.001)
train_step = my_opt.minimize(loss)
7. Logistic Regression
Implementing Logistic Regression
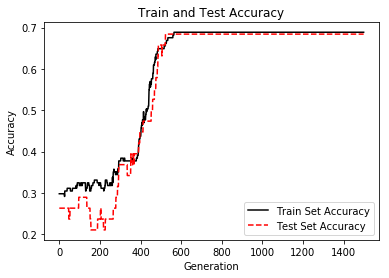
Logistic regression is a way to predict a number between zero or one (usually we consider the output a probability). This prediction is classified into class value ‘1’ if the prediction is above a specified cut off value and class ‘0’ otherwise. The standard cutoff is 0.5. For the purpose of this example, we will specify that cut off to be 0.5, which will make the classification as simple as rounding the output.
The data we will use for this example will be the UMASS low birth weight data.
Model
The the output of our model is the standard logistic regression:
y = sigmoid(A * x + b)
The x matrix input will have dimensions (batch size x # features). The y target output will have the dimension batch size x 1.
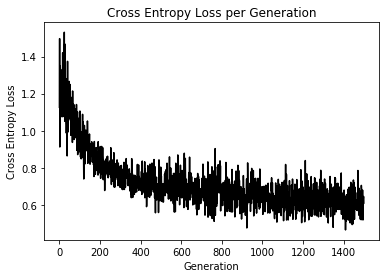
The loss function we will use will be the mean of the cross-entropy loss:
loss = mean( - y log(predicted) + (1-y) log(1-predicted) )
TensorFlow has this cross entropy built in, and we can use the function, ‘tf.nn.sigmoid_cross_entropy_with_logits()’
We will then iterate through random batch size selections of the data.
This function shows how to use TensorFlow to solve logistic regression.
$ \textbf{y} = sigmoid(\textbf{A}\times \textbf{x} + \textbf{b})$
We will use the low birth weight data, specifically:1
2# y = 0 or 1 = low birth weight
# x = demographic and medical history data
1 | import matplotlib.pyplot as plt |
1 | ops.reset_default_graph() |
Obtain and prepare data for modeling
1 | # name of data file |
Define Tensorflow computational graph
1 | # Declare batch size |
Train model
1 | # Initialize variables |
Loss = 0.6944471
Loss = 0.7304496
Loss = 0.62496805
Loss = 0.69695
Loss = 0.6096429
Display model performance
1 | %matplotlib inline |