网页版是最新的,PDF版不定期更新,建议直接从网页版导出PDF
| 《机器学习中的常识性问题》 | 手机扫码阅读 |
|---|---|
| 机器学习中的常识性问题定义:作为一名合格的机器学习从业人员必须理解和熟练掌握的机器学习领域的问题。 1. 网页版:https://yuanxiaosc.github.io/2019/08/16/机器学习中的常识性问题/ 2. 百度网盘 链接:https://pan.baidu.com/s/1NG-xnDm0_4OYkpvMfBDKIw, 提取码:5kra 3. 《机器学习宝典》(涵盖本文及扩展内容): https://github.com/yuanxiaosc/Machine-Learning-Book 欢迎Star和分享 4. 编者:袁宵 |
 |
机器学习的预备知识
概率论和信息论
《机器学习相关的概率论和信息论基础知识》 系统性总结了学习机器学习所需的概率论和信息论基础知识。
通过使用概率论,可以计算事件Y在事件X发生时的概率,这是很多机器学习的算法的构建模型的基础,比如建模Y=f(X)。通过使用信息论,可以描述随机事件的信息量也可以计算两种概率分布的差异,而后者是机器学习模型通常要优化的目标,比如度量模型预测分布和数据分布的差异。
张量
神经网络的输入、输出、权重都是张量,神经网络中的各种计算和变换就是对张量操作,张量这种数据结构是神经网络的基石,可以说没有理解张量就没有真正理解神经网络和人工智能。《理解张量》系统性总结了学习机器学习所需的张量知识。
张量(tensor)是一个多维数组(multidimensional arrays),即一种存储数字集合的数据结构,这些数字可通过索引(index)单独访问,并可通过多个索引进行索引。
机器学习知识点(彩图版)
机器学习知识点(彩图版)以生动形象的图片描述机器学习中的知识点,是入门机器学习的好资源也是本文内容的补充。

机器学习和深度学习的概念
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径。
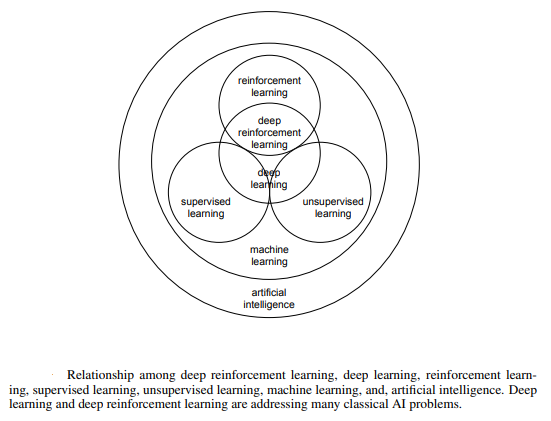
(图片来自论文 Deep Reinforcement Learning)
机器学习和深度学习的关系
参见《动手学深度学习》 阿斯顿·张(Aston Zhang) / 李沐(Mu Li)第一章 深度学习简介
机器学习研究如何使计算机系统利用经验改善性能。它是人工智能领域的分支,也是实现人工智能的一种手段。在机器学习的众多研究方向中,表征学习关注如何自动找出表示数据的合适方式,以便更好地将输入变换为正确的输出。在每一级(从原始数据开始),深度学习通过简单的函数将该级的表示变换为更高级的表示。因此,深度学习模型也可以看作是由许多简单函数复合而成的函数。当这些复合的函数足够多时,深度学习模型就可以表达非常复杂的变换。
深度学习可以逐级表示越来越抽象的概念或模式。以图像为例,它的输入是一堆原始像素值。深度学习模型中,图像可以逐级表示为特定位置和角度的边缘、由边缘组合得出的花纹、由多种花纹进一步汇合得到的特定部位的模式等。最终,模型能够较容易根据更高级的表示完成给定的任务,如识别图像中的物体。值得一提的是,作为表征学习的一种,深度学习将自动找出每一级表示数据的合适方式。
深度学习的一个外在特点是端到端的训练。也就是说,并不是将单独调试的部分拼凑起来组成一个系统,而是将整个系统组建好之后一起训练。比如说,计算机视觉科学家之前曾一度将特征抽取与机器学习模型的构建分开处理,像是Canny边缘探测和SIFT特征提取曾占据统治性地位达10年以上,但这也就是人类能找到的最好方法了。当深度学习进入这个领域后,这些特征提取方法就被性能更强的自动优化的逐级过滤器替代了。
相似地,在自然语言处理领域,词袋模型多年来都被认为是不二之选。词袋模型是将一个句子映射到一个词频向量的模型,但这样的做法完全忽视了单词的排列顺序或者句中的标点符号。不幸的是,我们也没有能力来手工抽取更好的特征。但是自动化的算法反而可以从所有可能的特征中搜寻最好的那个,这也带来了极大的进步。例如,语义相关的词嵌入能够在向量空间中完成如下推理:“柏林 - 德国 + 中国 = 北京”。可以看出,这些都是端到端训练整个系统带来的效果。
相对其它经典的机器学习方法而言,深度学习的不同在于:对非最优解的包容、对非凸非线性优化的使用,以及勇于尝试没有被证明过的方法。这种在处理统计问题上的新经验主义吸引了大量人才的涌入,使得大量实际问题有了更好的解决方案。尽管大部分情况下需要为深度学习修改甚至重新发明已经存在数十年的工具,但是这绝对是一件非常有意义并令人兴奋的事。
统计机器学习三要素:模型、策略与算法的区别与联系
参见李航《统计学习方法》第1章 统计学习方法概论
统计机器学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。统计机器学习方法的三要素就是:模型、策略和算法。
- 模型。在监督学习过程中,模型就是所要学习的条件概率分布或决策函数。数据构成假设空间,在这个假设空间中包含所有可能的条件概率分布或者决策函数,每一个条件概率分布或者决策函数对应一个模型,那么这个样本空间中的模型个数有无数个。
- 策略。策略即从假设空间中挑选出参数最优的模型的准则。模型的分类或预测结果与实际情况的误差(损失函数)越小,模型就越好。
- 算法。算法是指学习模型的具体计算方法,也就是如何求解全局最优解,并使得这个过程高效而且准确,本质上就是计算机算法,怎么去求数学问题的最优化解。
统计机器学习基于训练数据集,根据学习策略,从假设空间中选择最优模型、最后需要考虑用什么样的计算方法(算法)求解最优模型,所以我们可以认为统计机器学习都是由模型、策略和算法构成的。统计学习方法之间的不同,主要来自其模型、策略、算法的不同。确定了模型、策略、算法,统计学习的方法也就确定了。
在深度学习中,可以更加狭隘地理解为:模型就是模型结构(DNN、CNN、LSTM、Transformer),策略就是损失函数(均方差、交叉熵),算法就是优化算法(SGD、Adam)。
模型训练、预测与评估的关系

以文本分类为例说明解决机器学习问题的工作流程
更多内容参见 文本分类_谷歌机器学习指南
以下是用于解决机器学习问题的工作流程的高度概述:
- Step 1: Gather Data 获取数据
- Step 2: Explore Your Data 探索数据
- Step 2.5: Choose a Model* 选择模型
- Step 3: Prepare Your Data 准备数据
- Step 4: Build, Train, and Evaluate Your Model 构建、训练和评估模型
- Step 5: Tune Hyperparameters 调参
- Step 6: Deploy Your Model 发布模型
归纳偏置:奥卡姆剃刀
更多内容参见 归纳偏置 百度百科 和 Mitchell, T.M. (1980). The need for biases in learning generalizations. CBM-TR 5-110, Rutgers University, New Brunswick, NJ.
当学习器去预测其未遇到过的输入的结果时,会做一些假设(Mitchell, 1980)。而学习算法中归纳偏置则是这些假设的集合。
一个典型的归纳偏置例子是奥卡姆剃刀。奥卡姆剃刀(英语:Occam’s Razor, Ockham’s Razor),又称“奥坎的剃刀”,拉丁文为lex parsimoniae,意思是简约之法则,是由14世纪逻辑学家、圣方济各会修士奥卡姆的威廉提出的一个解决问题的法则,他在《箴言书注》2卷15题说“切勿浪费较多东西,去做‘用较少的东西,同样可以做好的事情’。”换一种说法,如果关于同一个问题有许多种理论,每一种都能作出同样准确的预言,那么应该挑选其中使用假定最少的。尽管越复杂的方法通常能做出越好的预言,但是在不考虑预言能力(即结果大致相同)的情况下,假设越少越好。
所罗门诺夫的归纳推理理论是奥卡姆剃刀的数学公式化:在所有能够完美描述已有观测的可计算理论中,较短的可计算理论在估计下一次观测结果的概率时具有较大权重。
在自然科学中,奥卡姆剃刀被作为启发法技巧来使用,更多地作为帮助科学家发展理论模型的工具,而不是在已经发表的理论之间充当裁判角色。在科学方法中,奥卡姆剃刀并没有被当做逻辑上不可辩驳的定理或者科学结论。在科学方法中对简单性的偏好,是基于可证伪性的标准。对于某个现象的所有可接受的解释,都存在无数个可能的、更为复杂的变体:因为你可以把任何解释中的错误归结于特例假设,从而避免该错误的发生。所以,较简单的理论比复杂的理论更好,因为它们更加可检验。
机器学习试图去建造一个可以学习的算法,用来预测某个目标的结果。要达到此目的,要给于学习算法一些训练样本,样本说明输入与输出之间的预期关系。然后假设学习器在预测中逼近正确的结果,其中包括在训练中未出现的样本。既然未知状况可以是任意的结果,若没有其它额外的假设,这任务就无法解决。这种关于目标函数的必要假设就称为归纳偏置。
以下是机器学习中常见的归纳偏置列表:
- 最大条件独立性(conditional independence):如果假说能转成贝叶斯模型架构,则试着使用最大化条件独立性。这是用于朴素贝叶斯分类器(Naive Bayes classifier)的偏置。
- 最小交叉验证误差:当试图在假说中做选择时,挑选那个具有最低交叉验证误差的假说,虽然交叉验证看起来可能无关偏置,但天下没有免费的午餐理论显示交叉验证已是偏置的。
- 最大边界:当要在两个类别间画一道分界线时,试图去最大化边界的宽度。这是用于支持向量机的偏置,它假设不同的类别是由宽界线来区分。
- 最小描述长度(Minimum description length):当构成一个假设时,试图去最小化其假设的描述长度。假设越简单,越可能为真的。见奥卡姆剃刀。
- 最少特征数(Minimum features):除非有充分的证据显示一个特征是有效用的,否则它应当被删除。这是特征选择(feature selection)算法背后所使用的假设。
- 最近邻居:假设在特征空间(feature space)中一小区域内大部分的样本是同属一类。给一个未知类别的样本,猜测它与它最紧接的大部分邻居是同属一类。这是用于最近邻居法的偏置。这个假设是相近的样本应倾向同属于一类别。
以下是深度学习中常见的归纳偏置列表:
还需要根据 Relational inductive biases, deep learning, and graph network 完善
- CNN的归纳偏置应该是locality和spatial invariance,即空间相近的grid elements有联系而远的没有,和空间不变性(kernel权重共享)
- RNN的归纳偏置是sequentiality和time invariance,即序列顺序上的timesteps有联系,和时间变换的不变性(rnn权重共享)
输入空间、输出空间与特征空间的关系
| 概念 | 解释 |
|---|---|
| 输入空间 | 输入X可能取值的空间 |
| 输出空间 | 输出Y可能取值的空间 |
| 特征空间 | 输入的具体实例通常由特征向量来表示,这是所有特征向量存在的空间称为特征空间 |
注释:
- 输入与输出空间可以是有限元的集合,也可以是整个欧式空间
- 输入与输出空间可以是同一个空间,也可以是不同空间,通常输出空间远小于输入空间
- 输入与输出又称为样本或者样本点
- 特征空间的每一维对应一个特征
- 有时可以假设输入空间与特征空间为相同的空间,不做区分
- 有时假设输入空间与特征空间为不同空间,并将实例从输出空间映射到特征空间
- 模型实际上都是定义在特征空间上的
比如,SVM的核函数,将输入从输入空间映射到特征空间得到特征向量之间的内积。通过在这个特征空间上学习线性支持向量机,实现了在输入空间中对非线性支持向量机的学习。(摘自《统计学习方法》李航,第95页)
机器学习十大经典算法
本节介绍了 10 大常用机器学习算法,包括线性回归、Logistic 回归、线性判别分析、朴素贝叶斯、KNN、随机森林。
注意,这里“算法”一词是广义上的算法,注意与统计机器学习三要素(模型、策略与算法)中的算法概念区分。
逻辑回归
下面只列出几个重要的知识点,逻辑回归的系统介绍可以参看【机器学习】逻辑回归(非常详细)
概率与logit(几率)的关系
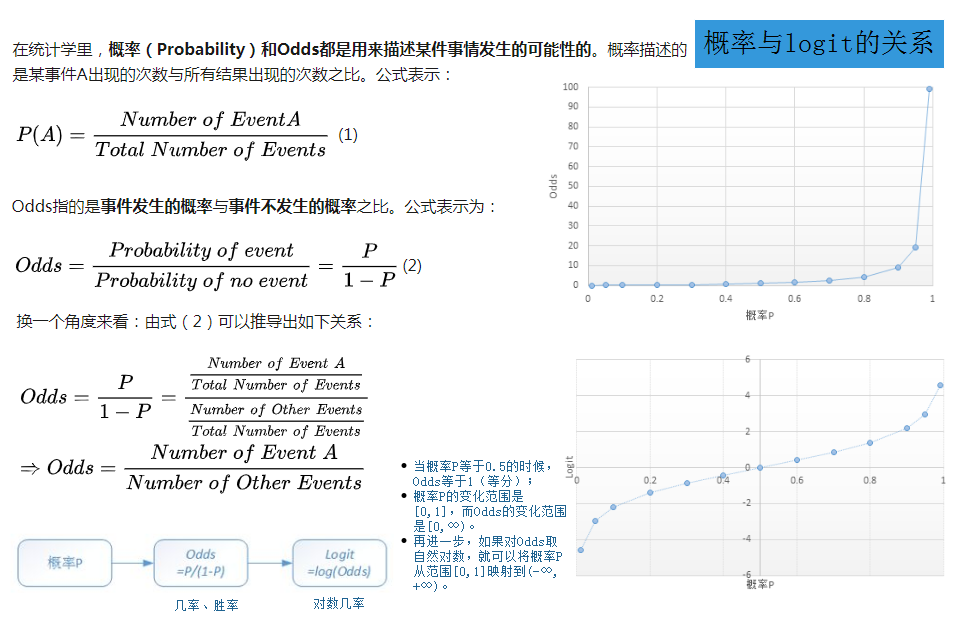
Logit模型和Logistic模型的区别与联系?

Logistic回归中的Logit函数和sigmoid函数的关系?
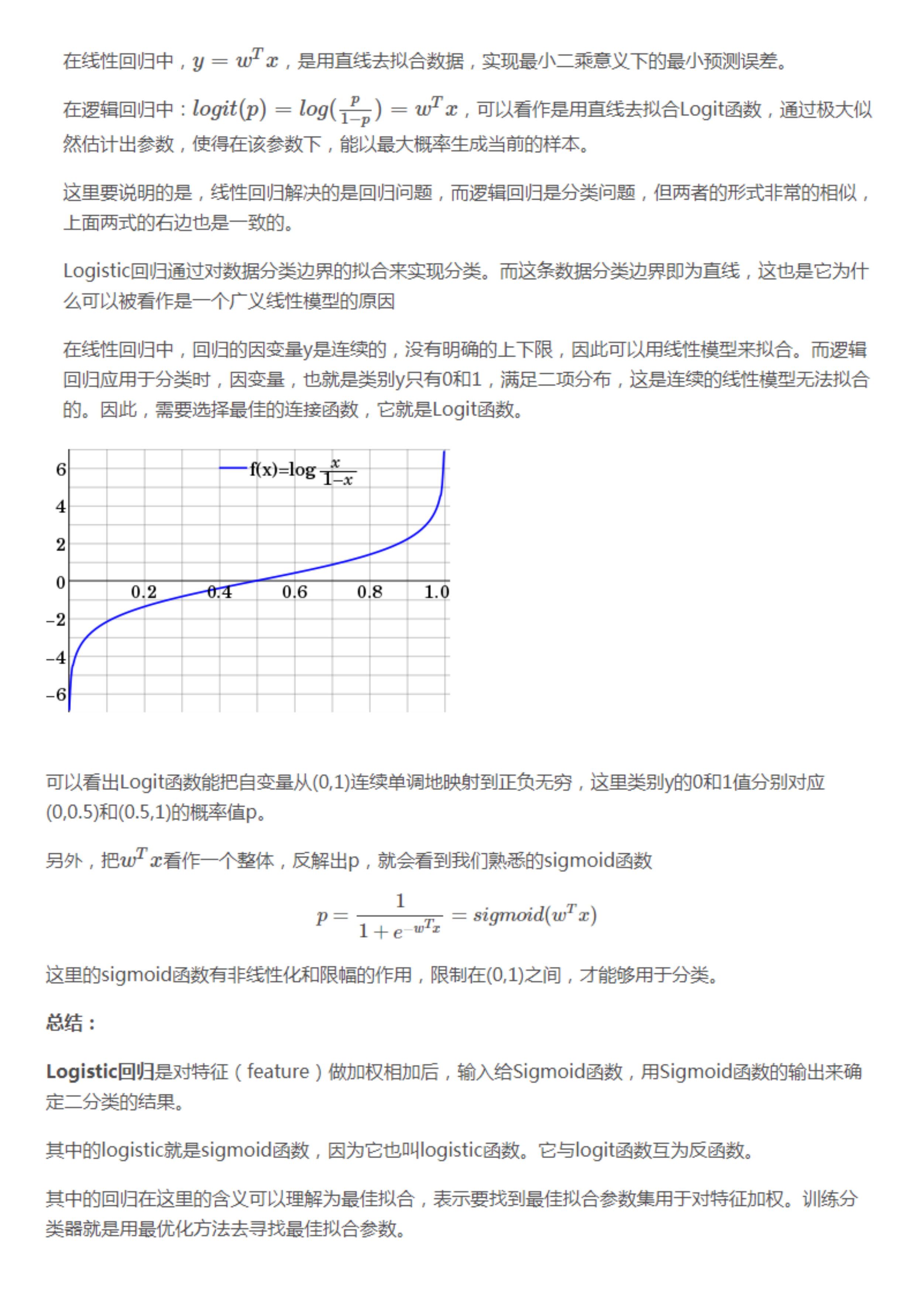
逻辑回归与线性回归的区别与联系?
本质区别:逻辑回归处理的是分类问题,线性回归处理的是回归问题。
联系:如果把一个事件的几率(odd)定义为该事件发生的概率与该事件不发生的概率的比值$\dfrac {p}{1-p}$,那么逻辑回归可以看作是对于“y=1|x”(将输入x预测为正样本的概率)这一事件的对数几率的线性回归。

支持向量机
支持向量机系统性总结看July的著名博文支持向量机通俗导论(理解SVM的三层境界)
深度学习中的基础模型结构
TODO:完善CV和NLP中的基础模型结构
画出循环神经网络中的RNN_cell、GRU、LSTM的结构图,并说明图中各部分的作用
更多内容参见 TensorFlow_rnn_cell_impl源码阅读
基本常用的RNN单元,如LSTM(长短期记忆)或GRU(门控循环单元)的基本计算公式是:(output, next_state) = call(input, state)
RNN_cell
LSTM
GRU
画出Transformer的模型结构图,并说明图中各部分的作用
更多内容参见 Attention is All You Need 解析并结合 Transformer 代码实现
![]()
模型结构相关的计算题
更多内容参见 深度学习中的计算题
机器学习中的损失函数
更多内容参见 常用损失函数小结
通常机器学习每一个算法中都会有一个目标函数,算法的求解过程是通过对这个目标函数优化的过程。在分类或者回归问题中,通常使用损失函数(代价函数)作为其目标函数。损失函数用来评价模型的预测值和真实值不一样的程度,在测试集上损失函数值越小,通常模型的性能越好。不同的算法使用的损失函数不一样。损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。
交叉熵损失函数

分开定义softmax运算和交叉熵损失函数可能会造成数值不稳定。
sigmoid和softmax后面接的两种不同交叉熵损失函数的比较
两种形式的二分类交叉熵损失函数的推导
更多内容参见 简单的交叉熵损失函数,你真的懂了吗?
对于类别标签为0和1的二分类交叉熵损失函数是:
对于类别标签为1和-1的二分类交叉熵损失函数是:
为什么结合sigmoid激活函数和交叉熵损失函数能保证数值稳定?
更多内容参见TensorFlow源码 nn.sigmoid_cross_entropy_with_logits
1 | For brevity, let `x = logits`, `z = labels`. The logistic loss is |
机器学习中的优化算法
在训练模型时,我们会使用优化算法不断迭代模型参数以降低模型损失函数的值。当迭代终止时,模型的训练随之终止,此时的模型参数就是模型通过训练所学习到的参数。
优化算法对于深度学习十分重要。一方面,训练一个复杂的深度学习模型可能需要数小时、数日,甚至数周时间,而优化算法的表现直接影响模型的训练效率;另一方面,理解各种优化算法的原理以及其中超参数的意义将有助于我们更有针对性地调参,从而使深度学习模型表现更好。
优化与深度学习的关系
由于优化算法的目标函数通常是一个基于训练数据集的损失函数,优化的目标在于降低训练误差。 而深度学习的目标在于降低泛化误差。为了降低泛化误差,除了使用优化算法降低训练误差以外,还需要注意应对过拟合。本章中,我们只关注优化算法在最小化目标函数上的表现,而不关注模型的泛化误差。
反向传播算法
反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。 在神经网络上执行梯度下降法的主要算法。该算法会先按前向传播方式计算(并缓存)每个节点的输出值,然后再按反向传播遍历图的方式计算损失函数值相对于每个参数的偏导数。
BP算法的学习过程由正向传播过程和反向传播过程组成。在正向传播过程中,输入信息通过输入层经隐含层,逐层处理并传向输出层。如果在输出层得不到期望的输出值,则取输出与期望的误差的平方和作为目标函数,转入反向传播,逐层求出目标函数对各神经元权值的偏导数,构成目标函数对权值向量的梯量,作为修改权值的依据,网络的学习在权值修改过程中完成。误差达到所期望值时,网络学习结束。
反向传播算法的四个基本方程如下,详细证明过程可参看《反向传播算法-by袁宵》

梯度下降算法




深度学习中的梯度消失、爆炸原因及其解决方法
梯度消失、爆炸和不稳定的概念
- 梯度不稳定:在深度神经网络中的梯度是不稳定的,在靠近输入层的隐藏层中或会消失,或会爆炸。这种不稳定性才是深度神经网络中基于梯度学习的根本问题。产生梯度不稳定的根本原因:前面层上的梯度是来自后面层上梯度的乘积。当存在过多的层时,就会出现梯度不稳定场景,比如梯度消失和梯度爆炸。
- 梯度消失:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度消失。
- 梯度爆炸:在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。这种现象叫梯度爆炸。
梯度消失与梯度爆炸的产生原因
- 梯度消失:(1)隐藏层的层数过多;(2)采用了不合适的激活函数(更容易产生梯度消失,但是也有可能产生梯度爆炸)
- 梯度爆炸:(1)隐藏层的层数过多;(2)权重的初始化值过大
梯度消失与梯度爆炸的解决方案
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑一下三种方案解决:
- 从激活函数的角度。用ReLU、Leaky-ReLU、P-ReLU、R-ReLU、Maxout等替代sigmoid函数。
- 从模型结构的角度。用Batch Normalization和残差连接,LSTM的结构设计也可以改善RNN中的梯度消失问题。
- 从梯度值本身的角度。梯度剪切、正则。这个方案主要是针对梯度爆炸提出的,其思想是设值一个剪切阈值,如果更新梯度时,梯度超过了这个阈值,那么就将其强制限制在这个范围之内。这样可以防止梯度爆炸。另一种防止梯度爆炸的手段是采用权重正则化,正则化主要是通过对网络权重做正则来限制过拟合,但是根据正则项在损失函数中的形式可以看出,如果发生梯度爆炸,那么权值的范数就会变的非常大,反过来,通过限制正则化项的大小,也可以在一定程度上限制梯度爆炸的发生。
指数加权移动平均与动量法

目标函数有关自变量的梯度代表了目标函数在自变量当前位置下降最快的方向。因此,梯度下降也叫作最陡下降(steepest descent)。在每次迭代中,梯度下降根据自变量当前位置,沿着当前位置的梯度更新自变量。然而,如果自变量的迭代方向仅仅取决于自变量当前位置,这可能会带来一些问题。

同一位置上,目标函数在竖直方向( x2 轴方向)比在水平方向( x1 轴方向)的斜率的绝对值更大。因此,给定学习率,梯度下降迭代自变量时会使自变量在竖直方向比在水平方向移动幅度更大。那么,我们需要一个较小的学习率从而避免自变量在竖直方向上越过目标函数最优解。然而,这会造成自变量在水平方向上朝最优解移动变慢。
下面我们试着将学习率调得稍大一点,此时自变量在竖直方向不断越过最优解并逐渐发散。



动量法使用了指数加权移动平均的思想。它将过去时间步的梯度做了加权平均,且权重按时间步指数衰减。动量法使得相邻时间步的自变量更新在方向上更加一致。
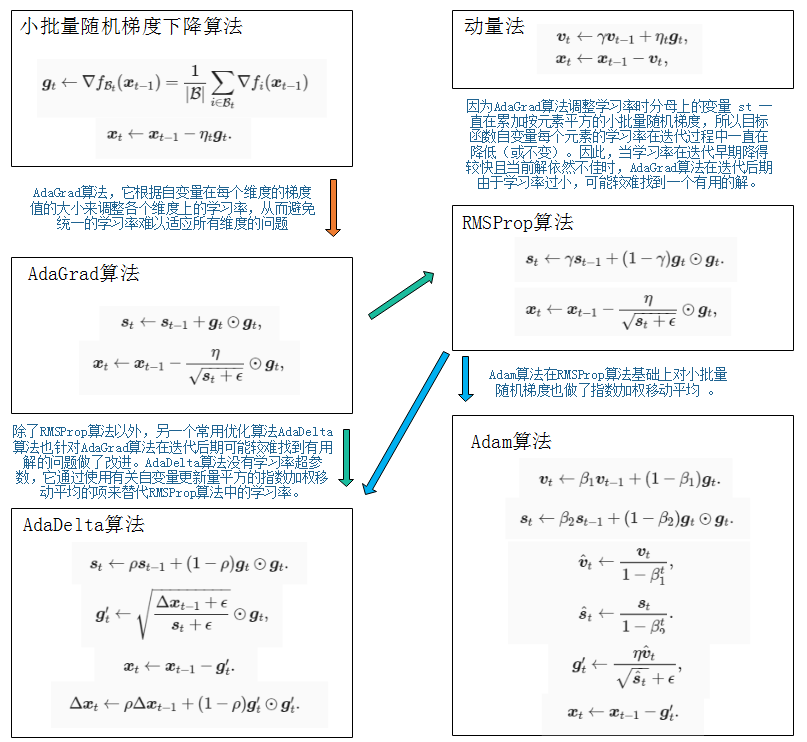
SGD、AdaGrad、RMSProp、AdaDelta和Adam基于梯度的优化算法关系
AdaGrad算法
AdaGrad算法,它根据自变量在每个维度的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应所有维度的问题。

RMSProp算法
我们在“AdaGrad算法”一节中提到,因为调整学习率时分母上的变量 $s_t$ 一直在累加按元素平方的小批量随机梯度,所以目标函数自变量每个元素的学习率在迭代过程中一直在降低(或不变)。因此,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。为了解决这一问题,RMSProp算法对AdaGrad算法做了一点小小的修改。

AdaDelta算法
除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进。AdaDelta算法没有学习率超参数,它通过使用有关自变量更新量平方的指数加权移动平均的项来替代RMSProp算法中的学习率。

Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均。

在小批量梯度下降算法使用中的注意事项
以下仅为经验结论,一切以具体实验结果为准:
- 批量大小一般选取2的正数次幂,例如32、64、128、256等。这样能充分利用矩阵运算操作。
- 挑选的批量数据要具有随机性,避免数据的特定顺序给算法收敛带来不良影响。
- 选取较优的学习速度,为了加快收敛速度,同时提高求解精度,通常会采用衰减学习速率的方案:一开始算法采用较大的学习速率,当误差曲线进入平台期后,减小学习速率做更精细的调整。
锯齿现象(zig-zagging)
梯度下降方法得到的是局部最优解,如果目标函数是一个凸优化问题,那么局部最优解就是全局最优解,理想的优化效果如下图,值得注意一点的是,每一次迭代的移动方向都与出发点的等高线垂直:
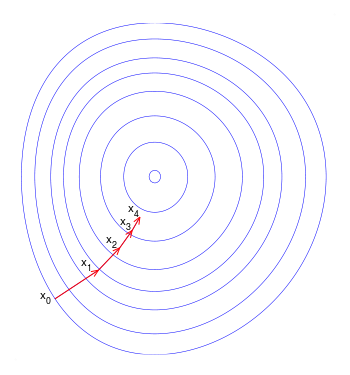
需要指出的是,在某些情况下,最速下降法存在锯齿现象( zig-zagging)将会导致收敛速度变慢(可以使用特征归一化来解决锯齿现象):
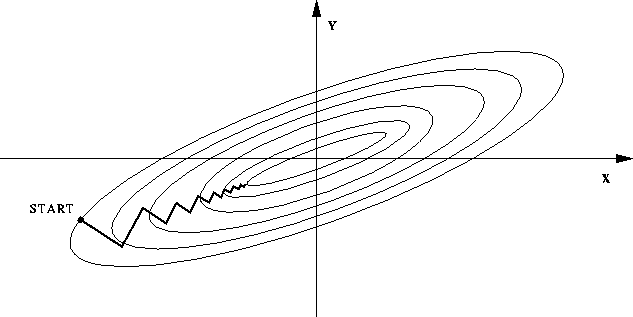
粗略来讲,在二次函数中,椭球面的形状受 hesse 矩阵的条件数影响,长轴与短轴对应矩阵的最小特征值和最大特征值的方向,其大小与特征值的平方根成反比,最大特征值与最小特征值相差越大,椭球面越扁,那么优化路径需要走很大的弯路,计算效率很低。
经典机器学习中的优化问题
牛顿法与拟牛顿法
牛顿法、梯度下降与最速下降法对比
- 牛顿法提供了对函数的二阶近似,并在每一步都对函数进行优化。其最大的问题在于,在优化过程中需要进行矩阵转换,对于多变量情形花销过高(尤其是向量的特征较多的时候)。
- 梯度下降是最常用的优化算法。由于该算法在每步只对导数进行计算,其花销较低,速度更快。但是在使用该算法时,需要对步长的超参数进行多次的猜测和尝试。
- 最速下降法在每步都对函数的梯度向量寻找最优步长。它的问题在于,在每次迭代中需要对相关的函数进行优化,这会带来很多花销。
最小二乘法
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可用于曲线拟合。其他一些优化问题也可通过最小化能量或最大化熵用最小二乘法来表达。

机器学习中的激活函数
为什么引入非线性激励函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释)。
为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释)。当然现在也有一些对relu的改进,比如prelu,random relu等。
激活函数优劣对比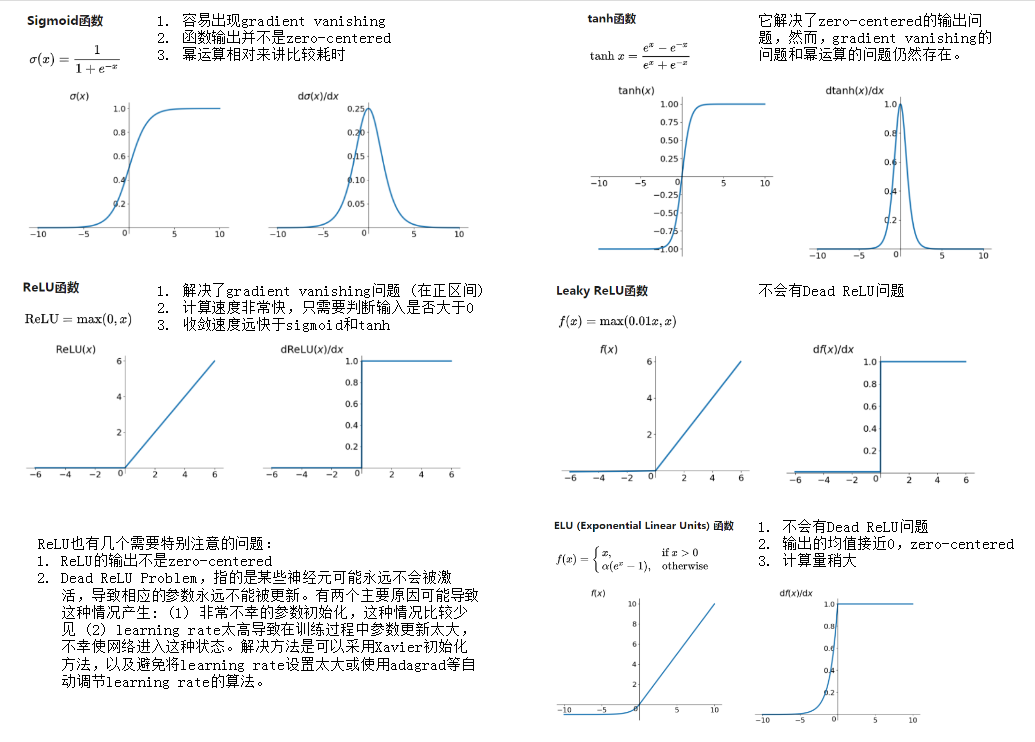
Sigmoid
$sigmoid(x)=\frac{1}{1+e^{-x}}$
$f’(z)=f(x)(1-f(x))$
Sigmoid的一个优良特性就是能够把𝑥 ∈ 𝑅的输入“压缩”到𝑥 ∈ [0,1]区间,这个区间的数值在机 器学习常用来表示以下意义:
- 概率分布。 [0,1]区间的输出和概率的分布范围契合,可以通过 Sigmoid 函数将输出转译为概率输出
- 信号强度。 一般可以将 0~1 理解为某种信号的强度,如像素的颜色强度,1 代表当前通 道颜色最强,0 代表当前通道无颜色;抑或代表门控值(Gate)的强度,1 代表当前门控 全部开放,0 代表门控关闭。
tanh
$tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}$
$f’(x)=1 - f^(x)$
更多内容参见 RNN中为什么要采用tanh而不是ReLu作为激活函数?
ReLU
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数,通常指代以斜坡函数及其变种为代表的非线性函数。
$Relu=max(0, x)$
Dead Relu
ReLU神经元对于所有的data point input,输出都是0,这是我们就说这个ReLU死掉了。
更多内容参见 由dead relu引发的思考——正则化算法漫谈
Leaky ReLU
$f(x)=max(\alpha x, x)$
ELU
$f(x)= \begin{cases}x,& \text{if } x > 0\\
\alpha(e^x - 1), & \text{otherwise}
\end{cases}$
gelu
更多内容参见深度学习中的gelu激活函数详解
近似的计算式是:
gelu(gaussian error linear units)就是我们常说的高斯误差线性单元,它是一种高性能的神经网络激活函数,因为gelu的非线性变化是一种符合预期的随机正则变换方式。原始论文:https://arxiv.org/abs/1606.08415
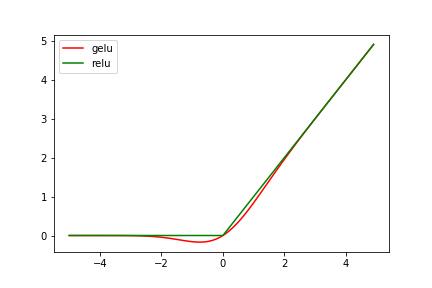
Softmax
$a_i=\frac{e^{z_i}}{\sum_k e^{z_k}}$
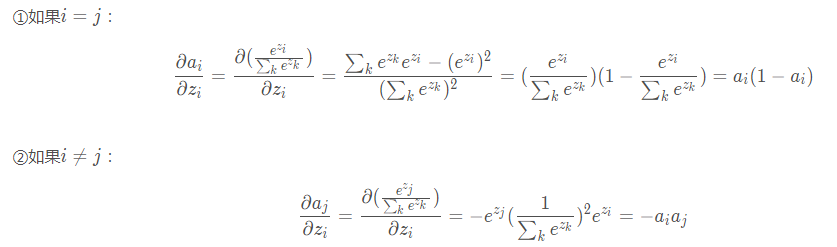
Softmax运算

扩展阅读:激活函数(ReLU, Swish, Maxout)
机器学习中的正则化方法
更多内容参见 正则化 Poll的笔记
L1 Normalization
L1 正则化使得模型参数具有稀疏性的原理是什么?
回答角度如下:
- 解空间形状
- 函数叠加
- 贝叶斯先验
L2 Normalization
Batch Normalization
batch normalization有效地加快了模型的收敛速度,在一定程度缓解了深层网络中“梯度弥散”的问题,从而使得训练深层网络模型更加容易和稳定。batch normalization的算法过程如下:

1 | 1.求当前batch的数据的均值u和方差sigma |
前三步很好理解,将数据减去均值,再除以方差,可以将数据归一到正态分布。那第四步该如何理解呢,又有什么作用呢?从公式上看,第四步相当于把已处于正态分布的数据乘以了一个尺度因子gamma,再加上了一个平移因子betta,这不是又逆向回原来的分布了吗?当然不是,第四步的gamma和betta是可学习的参数,网络会通过权重更新自己去调节这两个参数,使得它拟合现有的模型参数。如果取消了第四步,那相当于经过了bn层之后的数据都变成了正态分布,这样不利于网络去表达数据的差异性,会降低网络的性能,加上了第四步之后,网络会根据模型的特点自动地去调整数据的分布,更有利于模型的表达能力。
Group Normalization
Batch Normalization的效果虽好,但是它也有一些缺陷,当batch_size较小的时候,bn算法的效果就会下降,这是因为在较小的batch_size中,bn层难以学习到正确的样本分布,导致gamma和betta参数学习的不好。为了解决这一问题,Facebook AI Research提出了Group Normalization。
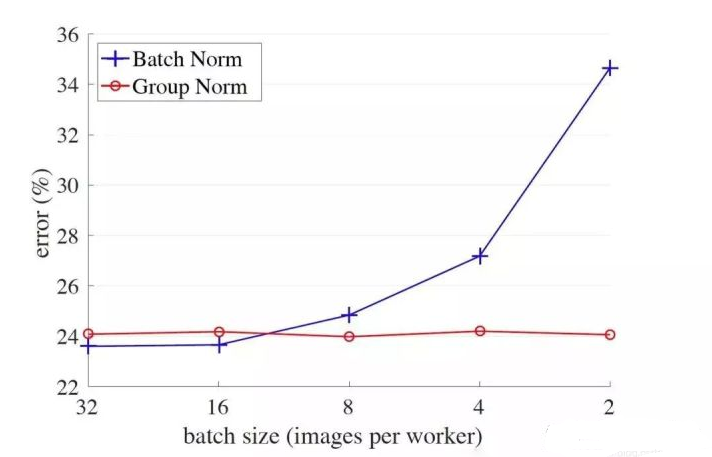
从上图可以看出,随着batch_size的减小,batch norm的error率逐渐上升,而group norm的error率几乎不变。在一些目标检测方面的模型中,例如faster-rcnn或mask-rcnn,当你只拥有一个GPU时,要求的batch_size通常为1或2张图片,这种情况下batch norm的效果就会大打折扣。那么group norm是如何改进这一点的呢?下面来看下group norm的算法流程:
1 | 1.将当前层的数据在通道的维度上划分为多个group |
可以看出,group normalization和batch normalization的算法过程极为相似,仅仅通过划分group这样的简单操作就改善了batch norm所面临的问题,在实际应用中取得了非常好的效果。
对比BatchNorm、LayerNorm、InstanceNorm、GroupNorm
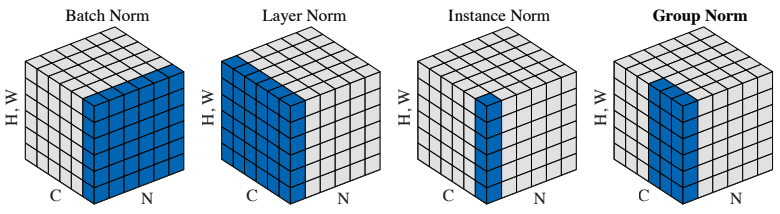
上图的N就是 batch,形状为 [batch, height, width, channel] 的特征图经过正则化时的计算轴和计算后的均值、方差的张量形状:
| BatchNorm | LayerNorm | InstanceNorm | GroupNorm |
|---|---|---|---|
| batch, height, width | height, width, channel | height, width | height, width, channel // Group |
| [1, 1, 1, channel] | [batch, 1, 1, 1] | [batch, 1, 1, channel] | [batch, 1, 1, Group, 1] |
注:GroupNorm时首先会将输入[batch, height, width, channel]根据设定的组数Group分组得到 [batch, height, width, Group, channel // Group],然后在对[1, 2, 4]轴上的数据计算均值和方差。
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm的通俗理解
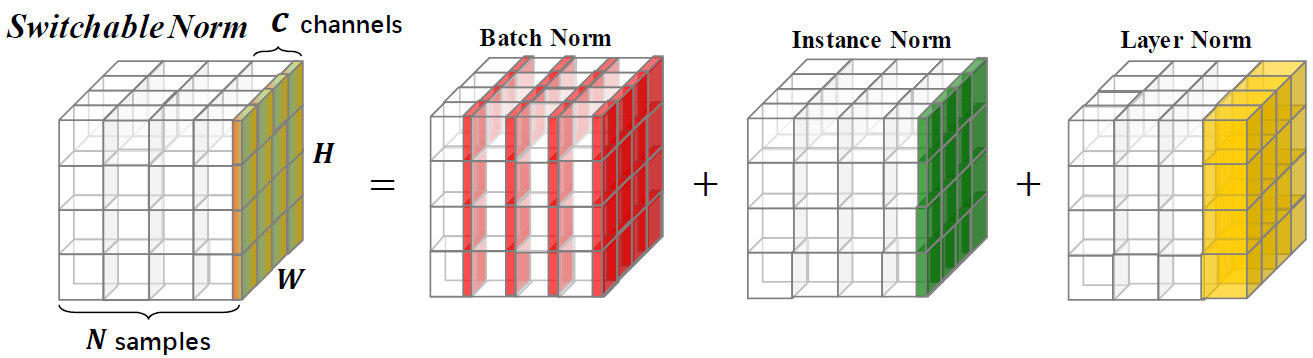
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm的相关论文、计算公式和代码总结
- BatchNorm:batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
- LayerNorm:channel方向做归一化,算CHW的均值,主要对RNN作用明显;
- InstanceNorm:一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
- GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
- SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
Dropout
机器学习中的模型训练技巧
TODO:丰富内容
- A Recipe for Training Neural Networks
- Must Know Tips/Tricks in Deep Neural Networks (by Xiu-Shen Wei)
机器学习中的评价指标
TODO:图片相关的评价指标
混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
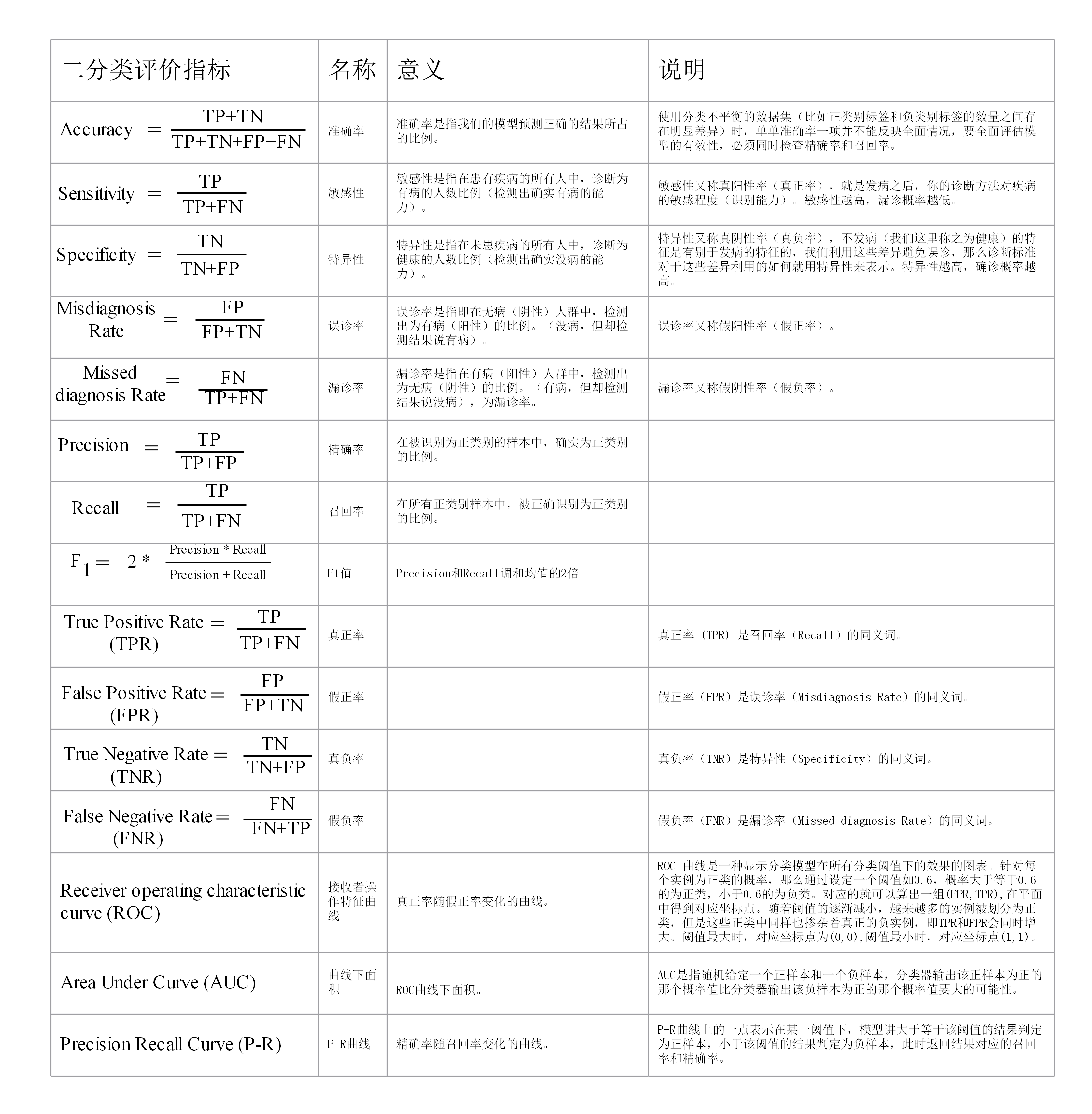
二分类评价指标
正例(Positives):你所关注的识别目标就是正例。
负例(Negatives):正例以外的就是负例。

多分类评价指标
多分类评价指标:一种方法是将多分类问题转化为多个二分类问题(在计算某个类别的统计值时,把关注的类当作二分类中的正例,其它类别都当作负例。)进行讨论。另一种方法直接定义的多分类指标。
将多分类评价指标转换成二分类指标
这里只介绍多分类的F1值计算方法,其它评价指标类似。
首先回顾的二分类情况下的准确率、精确率(Precision)、召回率(Recall)和F1值的计算方法。如图二分类的混淆矩阵,TP、TN、FP和FN分别表示真负、真正、假正和假负的样本个数,那么:
准确率表示模型预测正确的结果所占的比例,精确率表示在被识别为正类别的样本中,确实为正类别的比例,召回率表示在所有正类别样本中,被正确识别为正类别的比例,F1值表示Precision和Recall调和均值的2倍。
宏F1(F1_macro)值、加权F1(F1_weighted)值和微F1(F1_micro)值。宏F1值就是把多分类任务种的每一类作为一个二分类任务,算出其F1值,然后把这些F1值直接求平均数。加权F1值就是把多分类任务种的每一类作为一个二分类任务,算出其F1值,然后求这些F1值的加权平均,每个F1值对应的权重为该类别样本个数占总测试样本个数的比例。微F1值就是把多分类任务种的每一类作为一个二分类任务,然后依次累加这些二分类任务中对应的真负、真正、假正和假负的样本个数,最后根据这些累计量直接计算F1值。
上面式子的权重$\zeta$的计算式子如下,其中$M$是总的类别个数,$l_i$表示多分类任务中第$i$类标签,$\mathop{count}(\cdot)$是计数函数,统计对象是多分类任务的测试集。
上面式子中$Precision_{micro}$和$Recall_{micro}$与二分类的计算类似,只是把多分类任务种的每一类作为一个二分类任务,然后依次累加这些二分类任务中对应的真负、真正、假正和假负的样本个数,再计算累加量$Precision_{micro}$和$Recall_{micro}$。
直接定义多分类的评价指标
AUC定义
百度百科 https://baike.baidu.com/item/AUC/19282953
更多内容参见 AUC
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
机器翻译(文本生成)评价指标
机器翻译常用评价度量:
- 客观评价指标:BLEU、ROUGE、METEOR、CIDEr
- 主观评价指标 :流畅度、相关性、助盲性
注意这些指标不是完全独立,而是有相互的联系。比如客观评价指标BLEU采用了N-gram的匹配规则,通过它能够算出比较译文和参考译文之间n组词的相似的一个占比。一般情况1-gram可以代表原文有多少词被单独翻译出来,可以反映译文的充分性,2-gram以上可以反映译文的流畅性,它的值越高说明可读性越好。这两个指标是能够跟人工评价对应的。
BLEU (Bilingual Evaluation Understudy) 的内容、存在的问题、以及如何在工作中最大限度地减少这些问题?
- BLEU内容见 机器翻译质量评测算法-BLEU CSDN
- BLEU存在问题和解决方法见 Evaluating Text Output in NLP: BLEU at your own risk 或者 NLP输出文本评估:使用BLEU需要承担哪些风险?
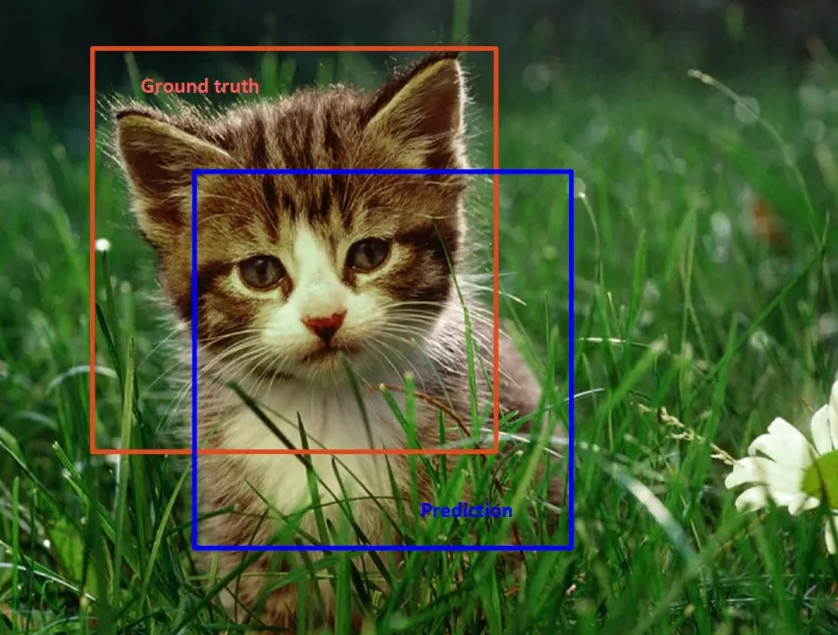
目标检测的评价指标IoU
IoU(Intersection-over-Union)交并比,顾名思义数学中交集与并集的比例。假设有两个集合A与B, IoU即等于A与B的交集除以A与B的并集,表达式如下:
在目标检测中,IoU为预测框(Prediction)和真实框(Ground truth)的交并比。如下图所示,在关于小猫的目标检测中,紫线边框为预测框(Prediction),红线边框为真实框(Ground truth)。
将预测框与真实框提取如下图,两者的交集区域为左下图斜线填充的部分,两者的并集区域为右下图蓝色填充的区域。IoU即为:左边斜线填充的面积/右边蓝色填充的总面积。
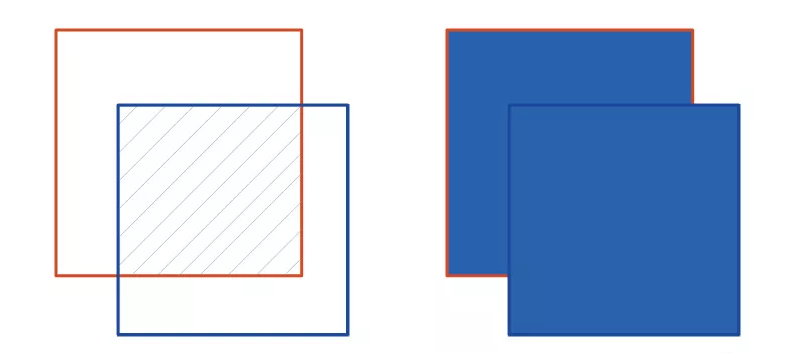
在目标检测任务中,通常取IoU≥0.5,认为召回。如果IoU阈值设置更高,召回率将会降低,但定位框则更加精确。理想的情况,当然是预测框与真实框重叠越多越好,如果两者完全重叠,则交集与并集面积相同,此时IoU等于1。
图像分类评价指标TopK
Top1:对一张图片,模型给出的识别概率中(即置信度分数),分数最高的为正确目标,则认为正确。这里的目标也就是我们说的正例。
TopK: 对一张图片,模型给出的识别概率中(即置信度分数),分数排名前K位中包含有正确目标(正确的正例),则认为正确。K的取值一般可在100以内的量级,当然越小越实用。比如较常见的,K取值为5,则表示为Top5,代表置信度分数排名前5当中有一个是正确目标即可;如果K取值100,则表示为Top100,代表置信度分数排名前100当中有一个是正确目标(正确的正例)即可。可见,随着K增大,难度下降。
机器学习中的模型选择
两种常见的模型选择方法:正则化与交叉验证。
正则化的作用是选择经验风险与模型复杂度同时较小的模型。
当数据充足时,将数据集划分为训练集、验证集和测试集,通过验证集来选择模型。当数据不充足时,采用交叉验证的方法。
交叉验证
- 简单交叉验证。首先随机将已给数据部分分为两部分,一部分作为训练集,另一部分作为测试集;然后用训练集在各种条件下(例如,不同的参数个数)训练模型,从而得到不同的模型;在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
- S折交叉验证。首先随机地将已给数据且分为S个不互相交的大小相同的子集;然后利用S-1个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次测评中平均测试误差最小的模型。
- 留一交叉验证。当S=N,N为数据集大小,称为留一交叉验证。
机器学习中的集成方法
TODO: 补充目前经典的集成学习方法
集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(bagging)、偏差(boosting)或改进预测(stacking)的效果。
集成学习在各个规模的数据集上都有很好的策略。
- 数据集大:划分成多个小数据集,学习多个模型进行组合。
- 数据集小:利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合。
机器学习中的著名的集成方法:Bagging,Boosting以及Stacking。
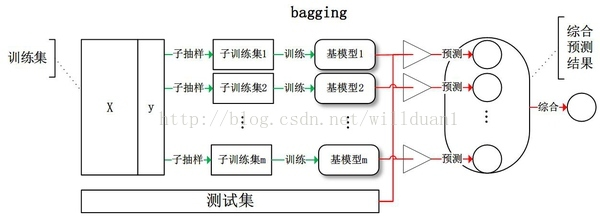
Bagging(bootstrap aggregating,装袋)
Bagging即套袋法,先说一下bootstrap,bootstrap也称为自助法,它是一种有放回的抽样方法,目的为了得到统计量的分布以及置信区间,其算法过程如下:
- 从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
- 每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
- 对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
Boosting
更多内容参见 机器学习—集成学习(Ensemble Learning)
其主要思想是将弱分类器组装成一个强分类器。通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。通过加法模型将弱分类器进行线性组合,比如:
- AdaBoost(Adaptive boosting)算法:刚开始训练时对每一个训练例赋相等的权重,然后用该算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在每次学习以后更注意学错的样本,从而得到多个预测函数。通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
- GBDT(Gradient Boost Decision Tree),每一次的计算是为了减少上一次的残差,GBDT在残差减少(负梯度)的方向上建立一个新的模型。
AdaBoost
AdaBoost原理详解
从基于树的算法的演变过程看集成学习
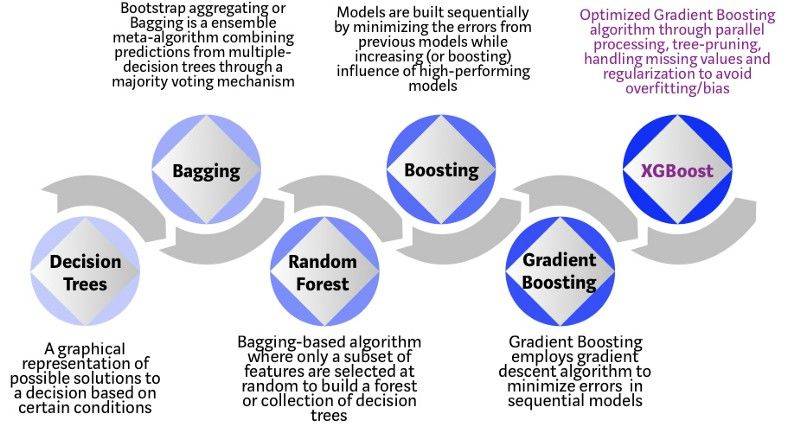
上述图片的直观解释:
假设你是面试官,要面试几名资历非常优秀的求职者。基于树的算法演变过程的每一步都可以类比为不同版本的面试场景。
- 决策树:每一名面试官都有一套自己的面试标准,比如教育水平、工作经验以及面试表现等。决策树类似于面试官根据他(她)自己的标准面试求职者。
- 袋装法(Bagging):现在面试官不只有一个人,而是一整个面试小组,小组中的每位面试官都有投票权。Bagging(Boostrap Aggregating)就是通过民主投票过程,综合所有面试官的投票,然后做出最终决定。
- 随机森林(Random Forest):这是基于 Bagging 的算法,但与 Bagging 有明显区别——它随机选择特征子集。也就是,每位面试官只会随机选择一些侧面来对求职者进行面试(比如测试编程技能的技术面或者是评估非技术技能的行为面试)。
- Boosting:这是一种替代方法,每位面试官根据前一位面试官的反馈来调整评估标准。通过部署更动态的评估流程来「提升」面试效率。
- 梯度提升(Gradient Boosting):这是 Boosting 的特例,这种算法通过梯度下降算法来最小化误差。用面试类比的话,就是战略咨询公司用案例面试来剔除那些不符合要求的求职者;
- XGBoost:将 XGBoost 视为极限的梯度提升。这是软硬件优化技术的完美结合,它可以在最短时间内用更少的计算资源得到更好的结果。
更多内容参见 决策树、随机森林、bagging、boosting、Adaboost、GBDT、XGBoost总结 知乎
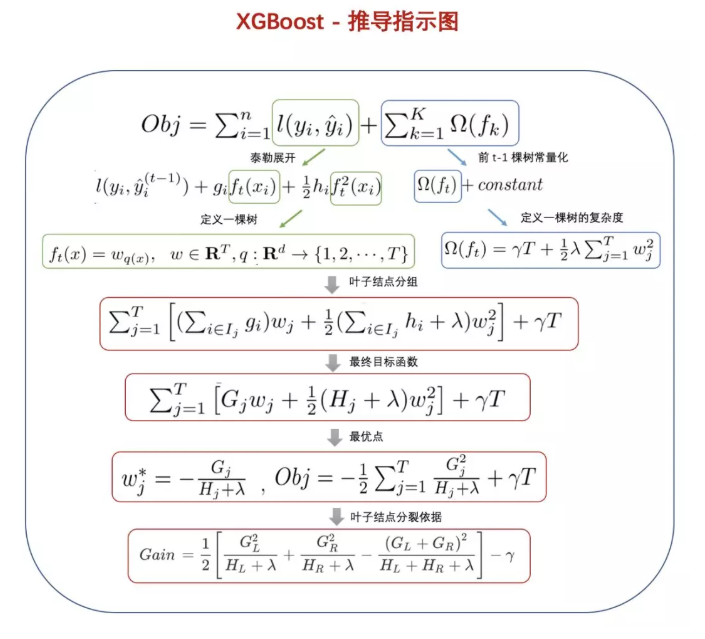
XGBoost
更多内容参见 XGBoost的工程师手册
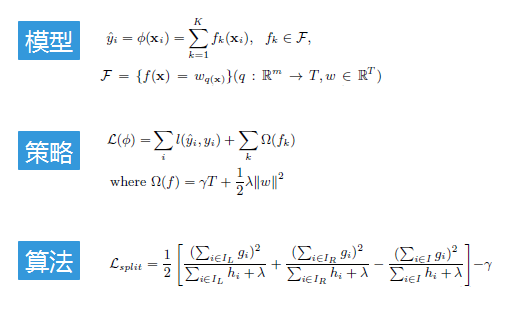
下图来自 XGBoost超详细推导,终于有人讲明白了!
降维
TODO: 完善内容
主成分分析(PCA)
更多内容参见 主成分分析(PCA)原理详解
PCA的概念
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
思考:我们如何得到这些包含最大差异性的主成分方向呢?
答案:事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。
线性判别分析(LDA)
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。
主成分分析(PCA)与线性判别分析(LDA)区别与联系
更多内容参见线性判别分析LDA原理总结
LDA用于降维,和PCA有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
首先我们看看相同点:
1)两者均可以对数据进行降维。
2)两者在降维时均使用了矩阵特征分解的思想。
3)两者都假设数据符合高斯分布。
我们接着看看不同点:
1)LDA是有监督的降维方法,而PCA是无监督的降维方法
2)LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
3)LDA除了可以用于降维,还可以用于分类。
4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
LDA主题模型
- 通俗理解LDA主题模型
- 一文详解LDA主题模型
- LDA数学八卦
- LDA主题模型原始论文 Latent Dirichlet Allocation
语言模型
语言模型 百度百科
语言模型是根据语言客观事实而进行的语言抽象数学建模,是一种对应关系。语言模型与语言客观事实之间的关系,如同数学上的抽象直线与具体直线之间的关系。
斯坦福公开课的自然语言处理 统计语言模型详解
神经语言模型 百度百科
神经语言模型(Neural Language Model,NLM)是一类用来克服维数灾难的语言模型,它使用词的分布式表示对自然语言序列建模。不同于基于类的n-gram模型,神经语言模型在能够识别两个相似的词,并且不丧失将每个词编码为彼此不同的能力。神经语言模型共享一个词(及其上下文)和其他类似词。
语言模型(language model)定义了自然语言中标记序列的概率分布。根据模型的设计,标记可以是词、字符、甚至是字节。标记总是离散的实体。最早成功的语言模型基于固定长度序列的标记模型,称为n-gram。一个n-gram 是一个包含n个标记的序列。基于n-gram 的模型定义一个条件概率——给定前n−1个标记后的第n个标记的条件概率。神经语言模型是由Bengio等人在2003年提出的,共享一个词(及其上下文)和其他类似词和上下文之间的统计强度。模型为每个词学习的分布式表示,允许模型处理具有类似共同特征的词来实现这种共享。
词向量、词嵌入与语言模型的关系?
词向量通常指通过语言模型学习得到的词的分布式特征表示,也被称为词编码,可以非稀疏的表示大规模语料中复杂的上下文信息。分布式词向量可以表示为多维空间中的一个点,而具有多个词向量的单词在空间上表示为数个点的集合,也可以看作在一个椭球分布上采集的数个样本 。
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。词嵌入的方法包括人工神经网络、对词语同现矩阵降维、概率模型以及单词所在上下文的显式表示等。在底层输入中,使用词嵌入来表示词组的方法极大提升了NLP中语法分析器和文本情感分析等的效果。
神经语言模型和统计语言模型有啥异同点?
更多内容参见 神经语言模型和统计语言模型有啥异同点? 知乎



语言模型的评价指标-困惑度?
困惑度 百度百科
在信息论中,perplexity(困惑度)用来度量一个概率分布或概率模型预测样本的好坏程度。它也可以用来比较两个概率分布或概率模型。(译者:应该是比较两者在预测样本上的优劣)低困惑度的概率分布模型或概率模型能更好地预测样本。

预训练语言模型的相关论文
词向量
word2vector
核心知识点:
- CBOW和Skip-gram两个语言模型
- 层次softmax 和负采样两个技术
然后深入读和实践:
- word2vec 中的数学原理详解(作者:peghoty 完整看完对理解w2v很有帮助)
- 附带注释的 word2vec 源码(作者:chenbjin)
- word2vec源码解析(作者:google19890102)
卷积
CNN中的局部连接(Sparse Connectivity)和权值共享
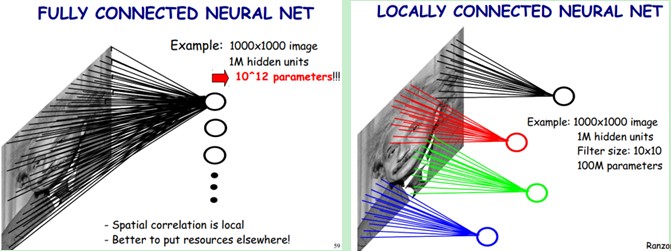
左边是全连接,右边是局部连接。对于一个1000 × 1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
尽管减少了几个数量级,但参数数量依然较多。能不能再进一步减少呢?能!方法就是权值共享。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数(也就是卷积核(也称滤波器)的大小),如下图。
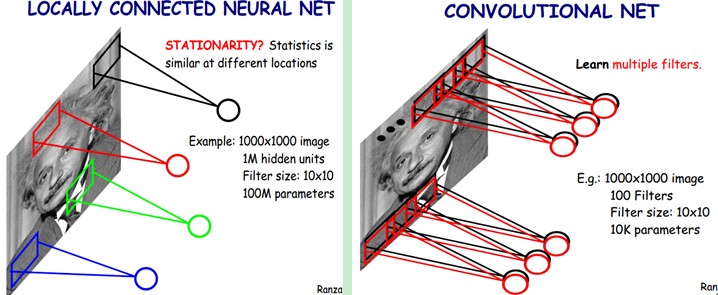
但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 = 10^4个而已。另外,偏置参数也是共享的,同一种滤波器共享一个。
卷积神经网络的核心思想是:局部感受野(local field),权值共享以及时间或空间亚采样这三种思想结合起来,获得了某种程度的位移、尺度、形变不变性
使用更小卷积核的作用
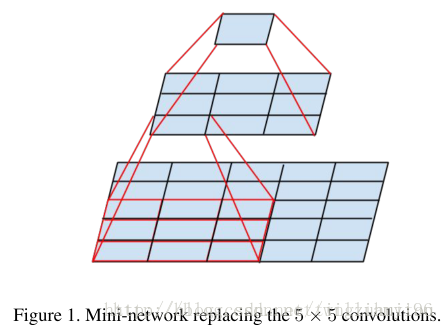
在VGG16中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5x5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
以下简单地说明一下小卷积(3*3)对于5×5网络感知野相同的替代性。
机器学习中的杂项问题
一名合格的算法工程师是怎样的
具体内容参见王喆的如何准备算法工程师面试,斩获一线互联网公司机器学习岗offer?
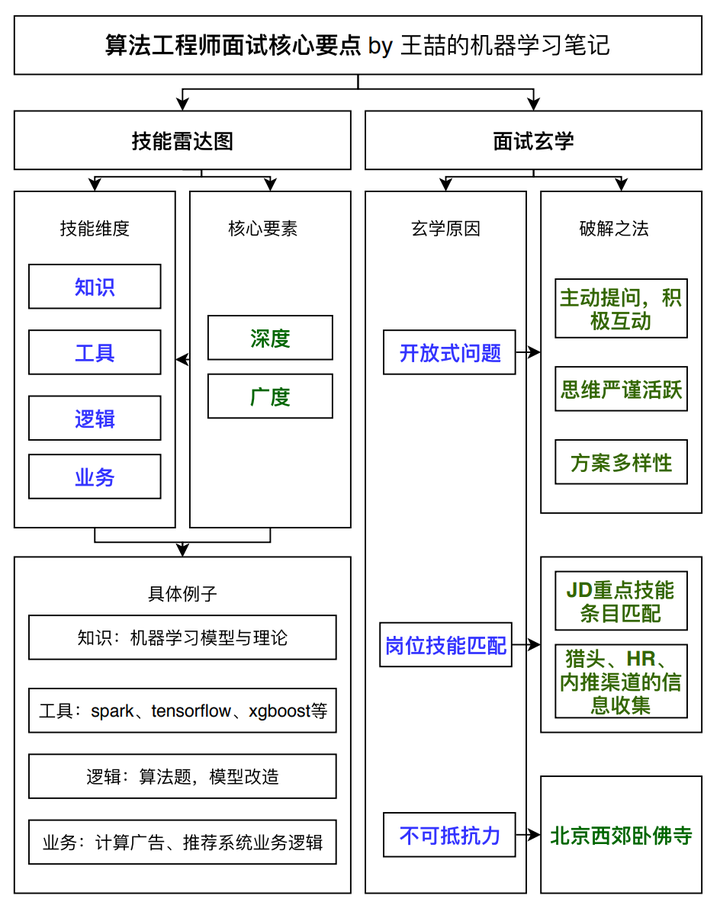
算法工程师的能力要求是相对全面的。作为算法模型的实现者和应用者,算法工程师在机器学习知识扎实的基础上,还应该具有算法的改进和实现的能力,因此工具和业务层面的要求也稍高。具体的内容来描述一下算法工程师的四个技能点:
- 知识:主要是指你对machine learning相关知识和理论的储备
- 工具:将你的machine learning知识应用于实际业务的工具
- 逻辑:你的举一反三的能力,解决问题的条理性,发散思维的能力,你的聪明程度
- 业务:深入理解所在行业的商业模式,从业务中发现motivation并进而改进模型算法的能力
那么如何找一份算法(机器学习)工程师的工作呢?请看找一份机器学习工作
真算法工程师与调包侠的区别与联系?
更多内容参见 现在的计算机专业(比如机器学习)已经沦为调包专业了吗?
区别:“轮子造了就是用来造车的。但是车好不好, 还是要看造车的人懂不懂轮子。”也就是说真算法工程师造出来的产物优于只会调包的人。
联系:进阶路线,普通的调包侠 -> 熟练的调包侠 -> 修包侠 -> 造轮子 -> 真算法工程师
进一步引用霍华德的回答:
虚假的AI有以下特点:
- 从不自己收集、处理、清洗、标注数据,而是找一个现有的数据集,疯狂 过拟合数据集。
- 科研idea主要来自于各种模块的花式排列组合,包含但不限于:各种CNN,各种RNN,各种attention,各种transformer,各种dropout,各种batchNorm,各种激活函数,各种loss function
- 而不是从实际问题和自然语言的现有挑战出发来思考idea
- 总是指望靠一个算法、一个模型可以解决所有问题
想做好真实AI,必须:
- 不断反馈,分析,改进。据说谷歌的搜索质量负责人Amit Singhal博士每天要看20个以上的不好搜索结果,然后持续不断的迭代改进。
- 面对真实环境中获取数据难,数据标注成本高,数据脏难清洗等问题
- 从实际问题和自然语言的现有挑战出发,设计针对问题最适合合理有效的模型
- 从不指望一个算法和问题可以解决所有问题,所有遇到的问题会做出合理的分析和拆解,针对各个难点设计最优解决算法,各个击破。
自然语言处理与机器学习的关系
点击下载自然语言处理与机器学习的双生树图。该图来自面向生产环境的自然语言处理工具包 HanLP
举例说明深度学习、机器学习在商业中的实际应用?
更多内容参见 深度学习算法的商业应用案例
机器学习“判定模型”和“生成模型”有什么区别?
更多内容参见 机器学习“判定模型”和“生成模型”有什么区别? 知乎详解
第一层理解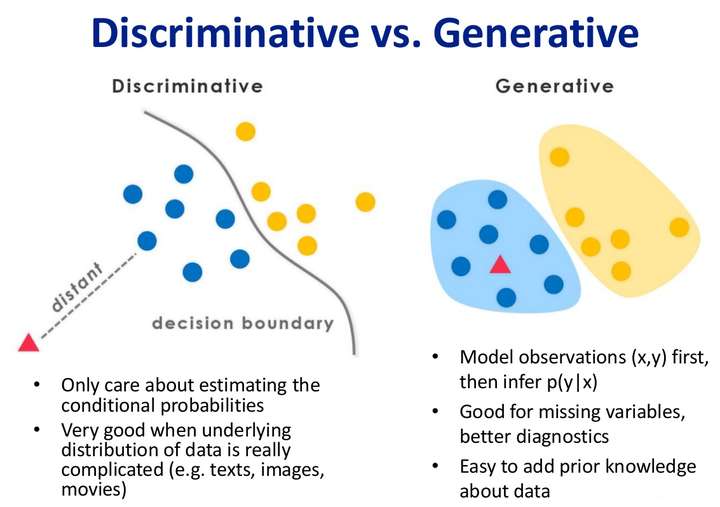
其实机器学习的任务是从属性X预测标记Y,即求概率P(Y|X);对于判别式模型来说求得P(Y|X),对未见示例X,根据P(Y|X)可以求得标记Y,即可以直接判别出来,如上图的左边所示,实际是就是直接得到了判别边界,所以传统的、耳熟能详的机器学习算法如线性回归模型、支持向量机SVM等都是判别式模型,这些模型的特点都是输入属性X可以直接得到Y(对于二分类任务来说,实际得到一个score,当score大于threshold时则为正类,否则为反类)
而生成式模型求得P(Y,X),对于未见示例X,你要求出X与不同标记之间的联合概率分布,然后大的获胜,如上图右边所示,并没有什么边界存在,对于未见示例(红三角),求两个联合概率分布(有两个类),比较一下,取那个大的。
在机器学习中任务是从属性X预测标记Y,判别模型求的是P(Y|X),即后验概率;而生成模型最后求的是P(X,Y),即联合概率。从本质上来说:判别模型之所以称为“判别”模型,是因为其根据X“判别”Y;而生成模型之所以称为“生成”模型,是因为其预测的根据是联合概率P(X,Y),而联合概率可以理解为“生成”(X,Y)样本的概率分布(或称为 依据);具体来说,机器学习已知X,从Y的候选集合中选出一个来,可能的样本有(X,Y_1), (X,Y_2), (X,Y_3),……,(X,Y_n),实际数据是如何“生成”的依赖于P(X,Y),那么最后的预测结果选哪一个Y呢?那就选“生成”概率最大的那个吧~
第二层理解
第三层理解
首先区分生成/判别方法和生成/判别模型。
有监督机器学习方法可以分为生成方法和判别方法(常见的生成方法有LDA主题模型、朴素贝叶斯算法和隐式马尔科夫模型等,常见的判别方法有SVM、LR等),生成方法学习出的是生成模型,判别方法学习出的是判别模型。


模型在验证集的测试指标优于在训练集的指标的原因是什么?
主要因素是因为像 BatchNormalization 和 Dropout 这样的层会影响训练期间的准确性。在计算验证损失时,它们会被关闭。
在较小程度上,这也是因为训练指标报告了一个周期的平均值,而验证指标是在周期之后进行评估的,因此验证指标体现的是已经训练稍长一些的模型。
计算机视觉迁移学习中的特征提取和微调的区别和联系
特征提取:使用先前网络学习的表示从新样本中提取有意义的特征。您只需在预训练模型的基础上添加一个新的分类器(将从头开始训练),以便您可以重新调整先前为我们的数据集学习的特征映射。您不需要(重新)训练整个模型。基本卷积网络已经包含通常用于分类图片的功能。然而,预训练模型的最终分类部分特定于原始分类任务,并且随后特定于训练模型的类集。
微调:冻结冻结模型库的一些顶层,并共同训练新添加的分类器层和基础模型的最后一层。这允许我们“微调”基础模型中的高阶特征表示,以使它们与特定任务更相关。
使用预先训练的模型进行特征提取:使用小型数据集时,通常会利用在同一域中的较大数据集上训练的模型所学习的特征。这是通过实例化预先训练的模型并在顶部添加完全连接的分类器来完成的。预训练的模型被“冻结”并且仅在训练期间更新分类器的权重。在这种情况下,卷积基础提取了与每个图像相关的所有特征,并且您刚刚训练了一个分类器,该分类器根据提取的特征集确定图像类。
微调预先训练的模型:为了进一步提高性能,可能需要通过微调将预训练模型的顶层重新调整为新数据集。在这种情况下,您调整了权重,以便模型学习特定于数据集的高级特征。当训练数据集很大并且非常类似于训练预训练模型的原始数据集时,通常建议使用此技术。
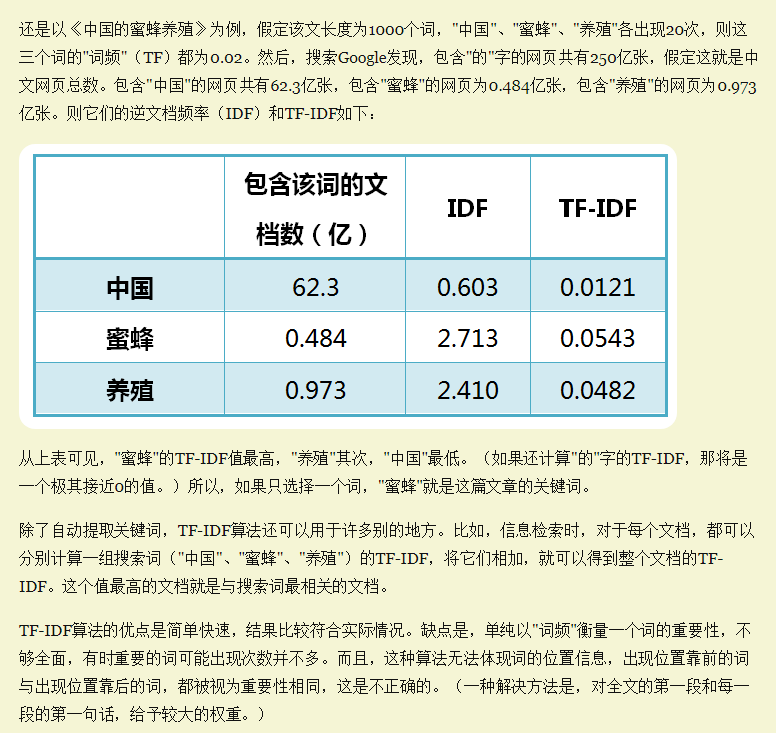
TF-IDF的定义、计算公式、应用和优缺点分别是什么?
TF-IDF有两层意思,一层是”词频”(Term Frequency,缩写为TF),另一层是”逆文档频率”(Inverse Document Frequency,缩写为IDF)。TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。

TF-IDF提取文档关键词的优缺点:
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。
TF-IDF的应用(后文一一举例说明):
- 提取文章关键词
- 确定文章相似性(结合余弦相似性)
- 自动摘要
TF-IDF与余弦相似性的应用(二):找出相似文章
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
TF-IDF与余弦相似性的应用(三):自动摘要
如果能从3000字的文章,提炼出150字的摘要,就可以为读者节省大量阅读时间。由人完成的摘要叫”人工摘要”,由机器完成的就叫”自动摘要”。其中,很重要的一种自动摘要技术就是词频统计。其实一种方法就是抽取文章中含有一定量关键词的句子。
BM25的定义、计算公式、应用和优缺点分别是什么?
如何提取文本关键词?
文本关键词提取算法总结和Python实现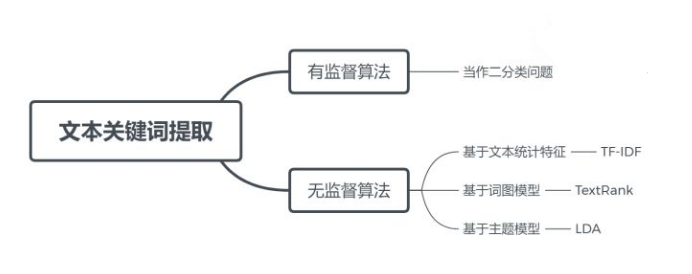
文本关键词提取算法大致分为有监督和无监督两种:
- 有监督算法将关键词抽取问题转换为判断每个候选关键词是否为关键词的二分类问题,它需要一个已经标注关键词的文档集合训练分类模型。
- 无监督算法不需要人工标注的训练集,利用某些方法发现文本中比较重要的词作为关键词,进行关键词抽取。词重要性的衡量有多种方式:基于文本统计特征、基于词图模型和基于主题模型,TF-IDF、TextRank和LDA分别是这几种不同方式的代表
TF-IDF关键词提取
TextRank关键词抽取
PageRank算法将整个互联网看作一张有向图,网页是图中的节点,而网页之间的链接就是途中的边。根据重要性传递的思想,如果一个网页A含有一个指向网页B的链接,那么网页B的重要性排名会根据A的重要行来提升。
在PageRank算法中,对于网页初始重要值(PR值)的计算非常关键,但是这个值无法预知,于是PageRank论文中给出了一种迭代算法求出这个PR值:为每个网页随机给一个初始值,然后迭代得到收敛值,作为网页重要性的度量。

LDA(Latent Dirichlet Allocation)关键词抽取
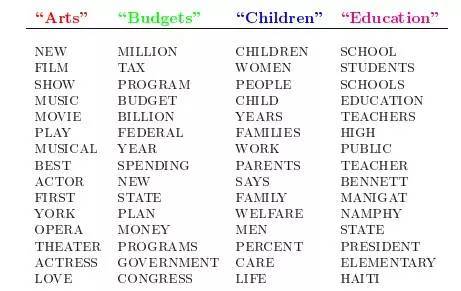
LDA的这三位作者在原始论文 Latent Dirichlet Allocation 中给了一个简单的例子。比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习的方式,获取每个主题Topic对应的词语(我们可以认为这些主题词语就是关键词)。如下图所示:
然后以一定的概率选取上述某个主题,再以一定的概率生成选取主题下的某个单词,不断的重复这两步,最终生成如下图所示的一篇文章(其中不同颜色的词语分别对应上图中不同主题下的词):

而当我们看到一篇文章后,往往喜欢推测这篇文章是如何生成的,我们可能会认为作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。LDA就是要干这事:根据给定的一篇文档,推测其主题分布。
如何处理数据类别不平衡问题
当一个分类任务的数据集中来自不同类别的样本数目相差悬殊时,我们通常称该数据集为“类别不平衡”的。以一个现实任务为例:在点击率预估(click-through rate prediction)任务中,每条展示给用户的广告都产生一条新样本,而用户最终是否点击了这条广告决定了样本的标签。显然,只有很少一部分的用户会去点击网页里的嵌入广告,这就导致最终得到的训练数据集中正/负例样本的数量差距悬殊。同样的情况也发生在很多实际应用场景中,如金融欺诈检测(正常/欺诈),医疗辅助诊断(正常/患病),网络入侵检测(正常连接/攻击连接)等等。 需要注意的是,尽管少数类的样本个数更少,表示的质量也更差,但其通常会携带更重要的信息,因此一般我们更关注模型正确分类少数类样本的能力。
分类问题的一个underlying assumption是各个类别的数据都有自己的分布,当某类数据少到难以观察结构的时候,我们可以考虑抛弃该类数据,转而学习更为明显的多数类模式,而后将不符合多数类模式的样本判断为异常/少数类,某些时候会有更好的效果。此时该问题退化为异常检测(anomaly detection)问题。
我将已有的不平衡学习算法划分为3类:数据级方法,算法级方法以及集成方法(参考极端类别不平衡数据下的分类问题研究综述)。
数据级方法
数据级方法是不平衡学习领域发展最早、影响力最大、使用最广泛的一类方法,也可称为重采样方法。该类方法关注于通过修改训练数据集以使得标准学习算法也能在其上有效训练。根据实现方式的不同,数据级方法可被进一步分类为:
- 从多数类别中删除样本的方法(欠采样)
- 为少数类别生成新样本的方法(过采样)
- 结合上述两种方案的混合类方法(过采样+欠采样去噪)
标准的随机重采样方法使用随机方法来选择用于预处理的目标样本。然而随机方法可能会导致丢弃含有重要信息的样本(随机欠采样)或者引入无意义的甚至有害的新样本(随机过采样),因此有一系列更高级的方法,试图根据根据数据的分布信息来在进行重采样的同时保持原有的数据结构。
数据级方法Strength
- 该类方法能够去除噪声/平衡类别分布:在重采样后的数据集上训练可以提高某些分类器的分类性能。
- 欠采样方法减小数据集规模:欠采样方法会去除一些多数类样本,从而可能降低模型训练时的计算开销。
数据级方法Weakness
- 采样过程计算效率低下:这一系列的“高级”重采样方法通常使用基于距离的邻域关系(通常是k-最近邻方法)来提取数据分布信息。该方式的缺点是需要计算每个数据样本之间的距离,而计算距离需要的计算量随着数据集的大小呈平方级增长,因此在大规模数据集上应用这些方法可能会带来极低的计算效率。
- 易被噪声影响:此外在具有高不平衡比且包含大量噪声的工业数据集中,少数类的结构可能并不能被样本的分布很好地表示。而被这些重采样方法用来提取分布信息的最近邻算法很容易被噪声干扰,因此可能无法得到准确的分布信息,从而导致不合理的重采样策略。
- 过采样方法生成过多数据:当应用于大规模且高度不平衡的数据集时,过采样类的方法可能会生成大量的少数类样本以平衡数据集。这会进一步增大训练集的样本数量,增大计算开销,减慢训练速度,并可能导致过拟合。
- 不适用于无法计算距离的复杂数据集:最重要的一点是这些重采样方法依赖于明确定义的距离度量,使得它们在某些数据集上不可用。在实际应用中,工业数据集经常会含有类别特征(即不分布在连续空间上的特征,如用户ID)或者缺失值,此外不同特征的取值范围可能会有巨大的差别。在这些数据集上定义合理的距离度量十分困难。
算法级方法
算法级方法专注于修改现有的标准机器学习算法以修正他们对多数类的偏好。在这类方法中最流行的分支是代价敏感学习(cost-sensitive learning),我们在此也只讨论该类算法。代价敏感学习给少数类样本分配较高的误分类代价,而给多数类样本分配较小的误分类代价。通过这种方式代价敏感学习在学习器的训练过程中人为提高了少数类别样本的重要性,以此减轻分类器对多数类的偏好。
算法级方法Strength
- 不增加训练复杂度:使用该类算法改进后的算法通常会有更好的表现,并且没有增加训练的计算复杂度。
- 可直接用于多分类问题:该类算法通常只修改误分类代价,因此可直接扩展到多分类问题上。
算法级方法Weakness
- 需要领域先验知识:必须注意的是,代价敏感学习中的代价矩阵(cost matrix)需要由领域专家根据任务的先验知识提供,这在许多现实问题中显然是不可用的。因此在实际应用时代价矩阵通常被直接设置为归一化的不同类别样本数量比。由于缺乏领域知识的指导,这种擅自设置的代价矩阵并不能保证得到最优的分类性能。
- 不能泛化到不同任务:对于特定问题设计的代价矩阵只能用于该特定任务,在其他任务上使用时并不能保证良好的性能表现。
- 依赖于特定分类器:另一方面,对于诸如神经网络的需要以批次训练(mini-batch training)方法训练的模型,少数类样本仅仅存在于在很少的批次中,而大部分批次中只含有多数类样本,这会给神经网络训练带来灾难性的后果:使用梯度下降更新的非凸优化过程会很快陷入局部极值点/鞍点(梯度为0),导致网络无法进行有效学习。使用敏感代价学习来给样本加权并不能解决这个问题。
集成学习的方法
集成学习类方法专注于将一种数据级或算法级方法与集成学习相结合,以获得强大的集成分类器。由于其在类别不平衡任务中表现出色,在实际应用中集成学习越来越受欢迎。
处理数据类别不平衡问题的工具:
imbalanced-learn A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
附加阅读
如何计算文本之间的相似度?
TODO: 完善内容
计算文本相似度的算法
| 一级分类 | 二级分类 |
|---|---|
| 基于词向量 | 欧几里德距离、曼哈顿距离和余弦距离、明式距离、切比雪夫距离等 |
| 基于具体字符 | 共有字符数、汉明距离、编辑距离、SimHash |
| 基于概率统计 | 杰卡德相似系数 |
| 基于统计学习模型的 | 主题模型(潜在语义分析LSA、潜在狄利克雷分布LDA) |
| 基于深度学习模型的 | doc2vec,word2vec |
短文本之间的相似度
如何设计一个比较海量文章相似度的算法?
SimHash是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling 》中提到的一种指纹生成算法或者叫指纹提取算法,被Google广泛应用在亿级的网页去重的Job中,作为locality sensitive hash(局部敏感哈希)的一种。其主要思想是降维,将高维的特征向量映射成低维的特征向量,通过两个向量的Hamming Distance来确定文章是否重复或者高度近似。其中,Hamming Distance,又称汉明距离,在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。也就是说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:1011101 与 1001001 之间的汉明距离是 2。至于我们常说的字符串编辑距离则是一般形式的汉明距离。
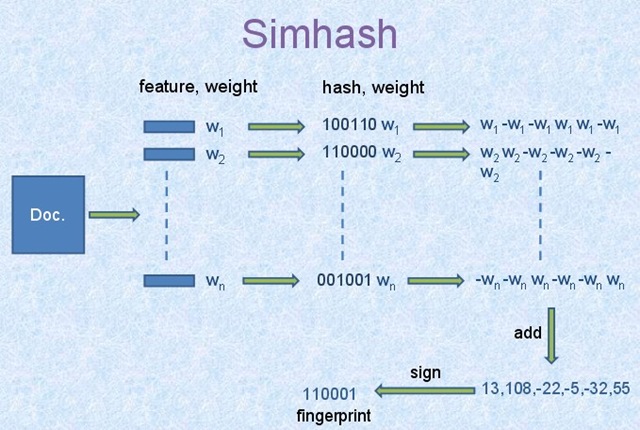
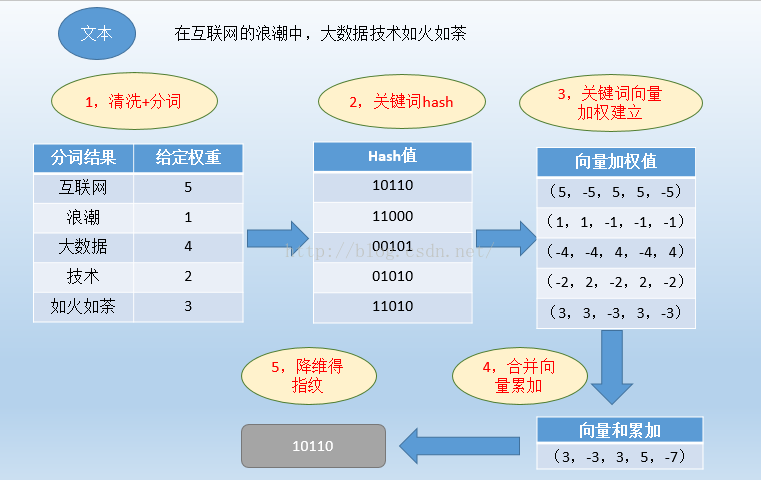
机器学习中距离和相似性度量方法
参见度量 百度百科。距离函数(度量)需要满足三条性质:正定性、对称性和三角不等式。
如何解决冷启动问题
如何用主题模型解决推荐系统中的冷启动问题?


下一步学习,终生学习
机器学习中的500问
系统性学习机器学习中的问题,参见 《深度学习500问》。
机器学习、深度学习框架
速览TensorFlow 基本概念 《Tensorflow-Cookbook》
自然语言处理的技术路线
详细内容见 nlp-roadmap
自然语言处理路线图详解,从数学基础、语言基础到模型和算法,这是你该了解的知识领域。
其它主题
深度学习
《神经网络与深度学习》
迁移学习
《迁移学习简明手册》
Transfer Learning - Machine Learning’s Next Frontier
Neural Transfer Learning for Natural Language Processing (PhD thesis)
jindongwang/transferlearning
多任务学习
《An Overview of Multi-Task Learning in Deep Neural Networks》

